第1章大型互联网公司的基础架构——1.8 Redis

第1章大型互联网公司的基础架构——1.8 Redis
John YamlRedis是现在最受欢迎的NoSQL数据库之一,是一个包含多种数据结构、支持网络访问、基于内存型存储、可选持久性的开源键值存储数据库。Redis具有如下特性。
- 数据被存储在内存中,性能高。
- 支持丰富的数据类型,包括字符串(String)、列表(List)、哈希表(Hash)、集合(Set)、有序集合(Sorted Set)等数据结构和相关数据操作。
- 支持分布式,包括主从模式、哨兵模式、集群模式,理论上其可以无限扩展。
- 基于单线程事件驱动模式实现,数据操作具有原子性。
Redis的应用场景非常广泛,例如缓存系统、计数器、限流、排行榜、社交网络等,具体的应用原理我们会在后面的章节中逐一介绍。本节还是聚焦于大型互联网公司如何应用Redis,即如何构建高性能、高可用、可扩展的Redis存储系统。
1.8.1 高可用架构1:主从模式
Redis也提供了主从复制机制,所以使用Redis可以很方便地构建与MySQL类似的主从模式。一个Master与若干Slave组成主从关系,当Slave与Master首次建立连接时,Master向Slave进行全量数据复制,复制结束后,再根据Master的最新数据变更进行增量数据复制。具体来说,Redis主从复制的流程如下。
- Slave连接到Master,发送PSYNC命令准备复制数据。
- Master收到PSYNC命令,执行BGSAVE命令生成目前全量数据的RDB快照文件,并创建缓冲区记录此后Master执行的数据变更命令。
- Master向所有Slave发送RDB快照文件,并在文件发送期间持续在缓冲区记录数据变更命令。
- Slave收到RDB快照文件后将其保存在磁盘中,再从磁盘中重新加载快照数据到内存,然后开始接收来自Master的数据变更命令。
- Master发送完RDB快照文件后,继续向Slave发送缓冲区中记录的数据变更命令。
- Slave收到数据变更命令后,在本地重新执行这些命令,以保证Slave与Master的数据一致。
不论是MySQL主从复制,还是Redis主从复制,大部分存储系统的主从复制原理都基本类似,即Master向Slave发送全量数据和增量数据;而且,如果Master向过多的Slave复制数据,则同样会出现“复制风暴”的问题。
1.8.2 高可用架构2:哨兵模式
在主从模式下,在Master宕机后,需要手动把一台Slave服务器切换为主服务器,这就需要费时费力的人工干预,而且会造成Redis服务在一段时间内不可用。这时候就需要哨兵模式登场了。Redis从2.6版本开始提供了哨兵模式。
哨兵模式的核心还是主从模式,只不过它在相对于主从模式下Master宕机导致不可写的情况下,提供了一种自动竞选机制:所有的Slave竞选新的Master。竞选机制的实现依赖于在Redis存储系统中启动的名为Sentinel(哨兵)的服务器。在Redis高可用架构中,Redis服务器除了可以是Master、Slave角色,还可以是Sentinel角色,它负责在Master宕机后自动选举出一个Slave升级为新的Master继续对外提供服务。
哨兵模式的工作流程大致如下:
- 在一个主从模式的Redis架构中会部署若干Sentinel节点,每个Sentinel节点都会与Master、Slave维持心跳。
- 当超过N个Sentinel节点认为Master宕机时,Sentinel节点会协商选举出一个Slave担任新的Master。
- Sentinel节点会告知所选举出的Slave节点它已被提升为Master,其他的Slave则转而与这个新的Master建立连接,复制数据。
引入Sentinel节点可以自动进行主从切换,其架构如图1-36所示。
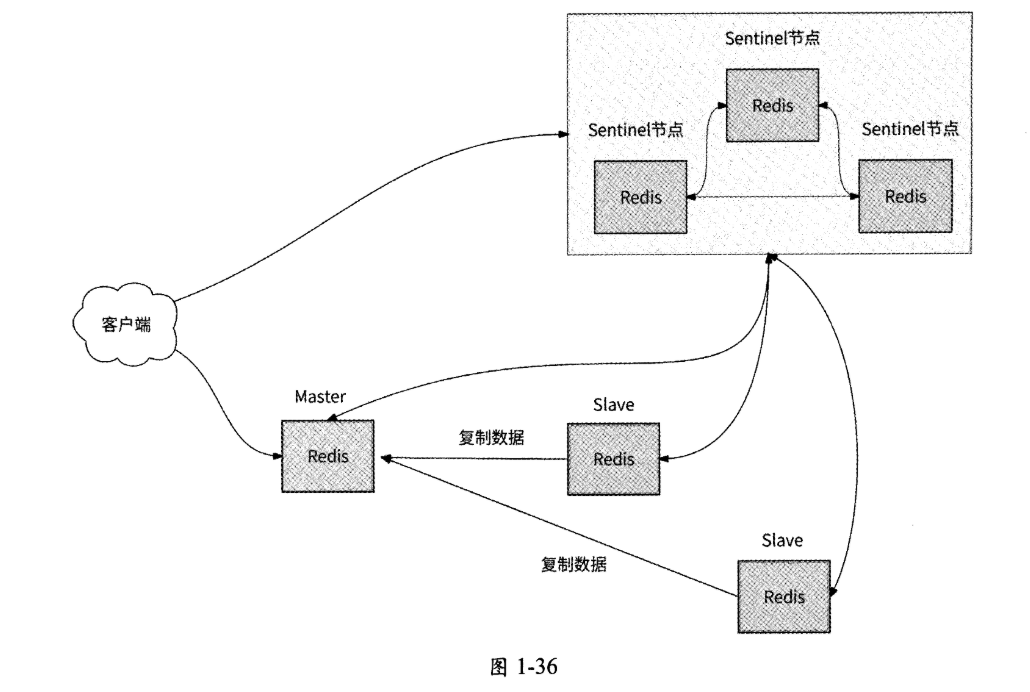
从图1-36中可以看出,3个Sentinel节点组成Sentinel集群,负责监控每个Redis节点的健康状况。在这种架构下,访问Redis的客户端,首先需要访问Sentinel集群获取Redis Master地址,当Master发生故障时,客户端会从Sentinel集群中得到新的Master地址。如此一来,研发工程师再也无须人工参与Redis主从切换的工作了,客户端也会在Master发生故障时主动获取新的Master地址。
1.8.3 高可用架构3:集群模式
无论是主从模式还是哨兵模式,Redis都只有一个Master对外提供服务,当有大量的数据需要存储时,单个Master的内存空间难以保存全量数据;而且,当有海量请求访问Redis时,单个Master会承受巨大的访问压力。实际上,互联网公司在应用Redis时,都会采用数据分片的方式:多个Master对外提供服务,全量数据分散在各个Master中。
Redis 3.0版本提供了集群(Redis Cluster)模式,使得Redis真正拥有了分布式存储能力。一个Redis集群由多个Redis节点组成,一个Master和若干Slave组成一个节点组,代表一个数据分片。如图1-37所示,Redis集群要求至少有3个Master,同时每个Master应该至少有一个Slave用于保证一个数据分片的高可用,集群中各个Redis节点之间可以相互通信。
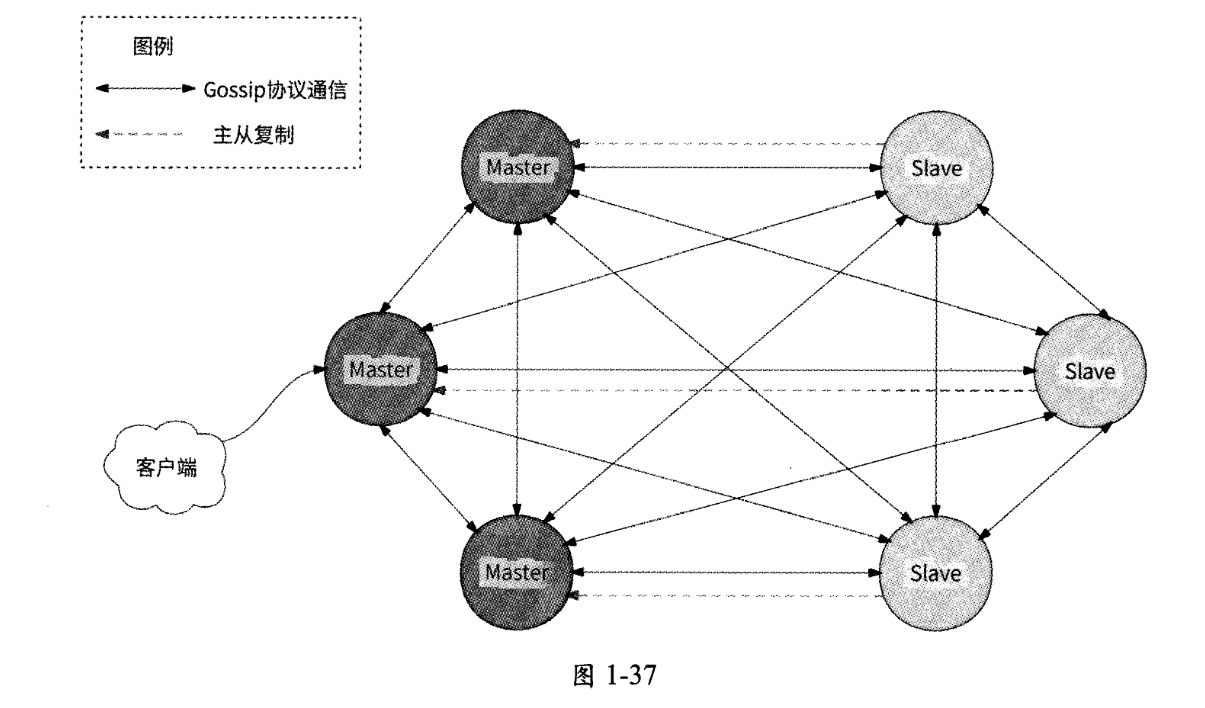
从图1-37中可以看出,在Redis集群中有3个数据分片,每个数据分片都通过主从模式保证高可用。Redis集群基于哈希槽进行数据分片:整个Redis数据库被划分为16384个哈希槽,每个Master可以管理0-16383个槽位(Slot),这些Master把16384个槽位都瓜分了。例如,图1-37中的3个Master可能分别管理0-5461、5462-10922 和 10923-16383个槽位。
当向Redis集群中写入某个数据时,会基于数据Key运行CRC16算法,然后将结果与16384取模得到一个槽位。此数据会被归属到这个槽位上,于是会被存储到管理这个槽位的Master上。槽位计算公式如下:
slot = CRC16(Key) mod 16384
Redis集群中的每个节点都保存有各个节点的IP地址及其所负责的槽位信息,于是Redis客户端连接任意一个节点最终都能保证数据读/写请求正确的数据分片(或者说 Master)处理。Redis客户端访问Redis集群的流程如下。
- Redis客户端连接到Redis集群中的任意一个Redis节点,获取槽位与Master的映射关系,并将该映射关系的信息缓存在客户端本地。
- 当Redis客户端要读/写数据时,首先基于数据Key运行CRC16算法,然后将结果与16384取模得到对应的槽位。
- Redis客户端根据计算出的槽位,在本地缓存中进一步定位到具体的Master地址,然后将数据访问请求发送到这个节点上。
接下来介绍Redis集群如何保证每个节点都能拥有各个节点的IP地址及其所负责的槽位信息。这就涉及Gossip协议通信了。
在Redis集群架构中,为了保证集群中的Redis节点能够灵活自动变更,我们应该格外关注集群的如下事件。
- 某个Redis节点加入集群。
- 数据分片扩缩容,将槽位迁移到新的数据分片上。
- 某数据分片的Master宕机,Slave需要被选举为新的Master。
我们希望整个Redis集群中的每个节点都能够尽快发现这些事件,并在所有节点中达成信息一致,那么各个节点之间就需要相互连通并且携带相关信息相互通知。按照最直白的逻辑,当某个节点涉及如上集群事件时,采用广播的形式向Redis集群中的其他所有节点发送通知,这样就能做到集群节点变更的实时同步。然而,Redis开发者考虑到,当Redis集群中的节点较多时,这种通知形式会占用大量的网络带宽,所以采用了Gossip协议通信。
Gossip的中文意思是“流言蜚语”,Gossip协议的通信机制就像流言蜚语一样被随意传播,成为人们茶余饭后的谈资。它的特点是,在一个节点数量有限的通信网络中,每个节点都会随机与部分节点通信,经过多轮迭代通信后,各个节点的信息在一定时间内会达成一致。Gossip协议的工作流程大致如下。
- 假设Gossip协议每隔1s传播一次信息。
- 当信息被传播到某个节点时,此节点会随机选取k个相邻节点传播信息。
- 节点每次传播信息时,都会选择没有收到此信息的相邻节点作为传播目标。
- 经过多次信息传播,最终全部节点都收到了此信息。
Gossip协议包含多种消息类型,与Redis集群相关的有meet、ping、pong、fail消息。
- meet:某个节点发送meet消息给新加入的节点,让新节点加入集群中并与其他节点周期性地进行ping、pong消息的交换。
- ping:每个节点都会向其他节点发送ping消息,用于相互告知自身的状态和所维护的槽位信息,同时检查其他节点是否已经宕机下线。
- pong:当某个节点接收到ping、meet消息时,使用pong消息作为响应消息返回给发送方。pong消息包含节点自身的信息数据。一个节点也可以向集群广播自身的pong消息,来通知整个集群变更此节点的状态信息。
- fail:某个节点判断出另一个节点宕机之后,就发送fail消息给其他节点,告知其他节点所指定的节点宕机了。
(1)集群新增节点
假设有一个Redis节点B想加入某个Redis集群,则可以通过Redis客户端向此集群中的任意一个Redis节点(比如A节点)发送CLUSTER MEET命令,其过程如下。
- 客户端向A节点发送
CLUSTER MEET <B节点IP地址〉<B节点端口号〉命令,告知A节点“这个地址的Redis服务器想加入你所在的集群,你们互相认识一下”。 - A节点处理CLUSTER MEET消息,保存B节点的地址并标记节点状态为“握手中”。
- 由于Gossip协议的周期性驱动,A节点发现B节点的状态处于“握手中”,于是向B节点发送meet消息,尝试与B节点建立网络连接。
- B节点收到meet消息后,同样保存A节点的地址并标记节点状态为“握手中”。
- B节点将自身信息通过pong消息返回给a节点,并接受与A节点的网络连接。
- A节点处理pong消息,更新B节点信息,并消除B节点的“握手中”状态。
- 与A节点一样,B节点会发现A节点的状态为“握手中”,于是向A节点发送 ping消息。
- A节点处理ping消息,将自身信息通过pong消息返回给B节点。
- B节点处理pong消息,同样是更新A节点信息并消除其“握手中”状态。
- 通过Gossip协议,A节点逐渐将B节点信息告知集群内所有的节点,b节点加入集群成功。
(2)节点故障转移
Redis集群中的每个节点(比如A节点)都会定期向其他节点发送ping消息,如果接收ping消息的B节点在指定的时间内没有为A节点返回pong消息,那么A节点就会认为B节点失联下线。但是由于网络原因,一个节点认为另一个节点下线并不能说明这个节点真的下线了,于是Redis集群引入了主观下线和客观下线的概念。
- 主观下线:A节点向B节点发送ping消息,但是没有得到回复,于是A节点主观地认为B节点下线了。
- 客观下线:如果集群中超过一半的节点均认为B节点主观下线了,按照少数服从多数的原则,B节点就会被认为客观下线了。
如果B节点被认为客观下线了,那么集群中的其他所有节点都会收到fail消息,用于通知B节点下线的事实。当B节点的从节点B’,收到fail消息后,得知自己的主节点已经下线,B’节点会停止数据复制并接管B节点管理的槽位,将自己提升为主节点,然后向集群广播pong消息,让集群中的所有节点都得知B’节点已经接管B节点。
Gossip协议的优点在于集群元信息的更新比较分散,不是集中在一个地方,所以可以使集群去中心化管理。不过,元信息更新会经过多次传播才能通知到集群内所有的节点,所以它是一个最终一致性协议。
Redis集群模式的Redis存储系统架构具有如下优势。
- 去中心化架构,集群中的每个节点都是对等的。
- 抽象了槽位的概念,集群数据分片管理更为便捷。
- 可扩展性较强,可以轻易地对集群节点进行动态扩容。
- 集群高可用,拥有自动故障发现与恢复能力,几乎不需要人工介入。
- Redis官方出品,对Redis的命令支持较为全面。
虽然Redis集群模式为Redis提供了分布式存储能力,但是根据笔者的经验,它并不一定是互联网公司构建Redis存储系统的最终架构方案。这是因为Gossip协议归根结底依赖扩散式的网络通信,集群节点的数量直接影响Gossip协议的传播范围。当Redis集群中的节点只有几百个时,它可以运行良好,但是如果集群节点有成千上万个,那么Gossip 协议就会造成集群内部存在大量网络通信,严重占用网络带宽,形成Gossip风暴。
1.8.4 高可用架构4:中心化集群架构
Redis集群中间代理(Proxy)用得最多的是推特公司开源的Twemproxy,其基本原理是:
- 通过中间代理的形式,Redis客户端将请求发送到Twemproxy;
- 然后Twemproxy根据数据路由规则将请求发送到正确的Redis节点;
- 最后Twemproxy将请求执行结果汇总并返回给客户端。
如图1-38所示(注意:这里的Redis集群省略了主从复制功能。在实际应用中,图中的每个Redis节点都会作为Master并与若干Slave共同组成一个Redis数据分片)。
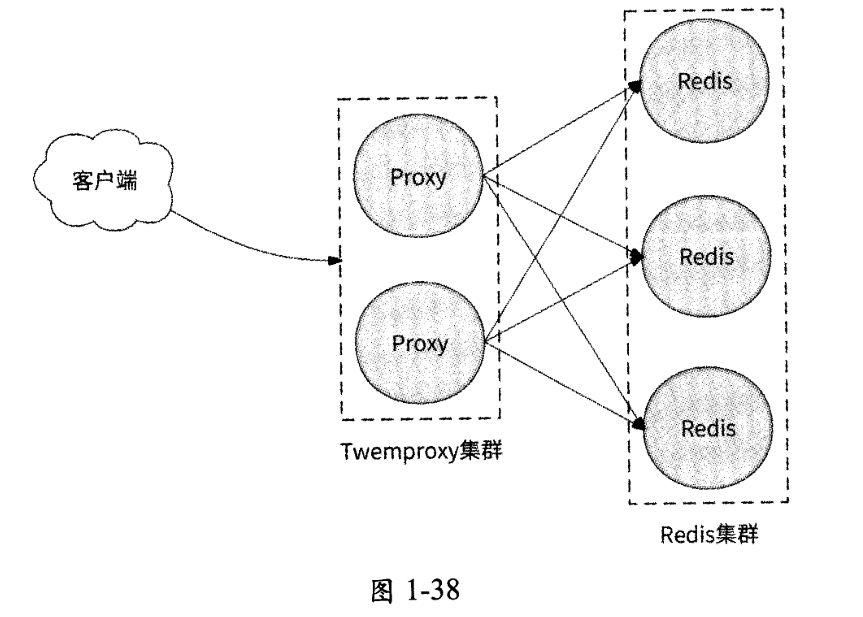
Twemproxy的思路与接入层技术类似:通过引入Twemproxy作为客户端访问Redis节点的中间代理,为由若干Redis节点组成的集群提供了数据分片的负载均衡能力,提高了Redis节点的高可用性和可扩展性。将Twemproxy作为中间代理的优势如下。
- 客户端像连接Redis实例一样直接连接Twemproxy,不需要修改任何代码逻辑。
- Twemproxy与Redis实例保持长连接,减少了客户端与Redis实例的连接数。
- 由Twemproxy决定客户端请求最终访问哪个Redis节点,不需要客户端、Redis 节点的参与。
不过,Twemproxy也存在一些功能层面的不足,例如:
- 没有友好的管理后台,不利于运维监控;
- 无法支持平滑的Redis集群扩缩容,当业务要求Redis集群增加节点时,会产生较高的运维成本。这也是Twemproxy的主要痛点。
许多大型互联网公司都借鉴了Twemproxy的思路并取长补短,纷纷推出了自研的Redis中心化集群架构方案,业界较为知名的是豌豆荚公司开源的Codis项目。下面我们重点介绍Codis的架构原理。
与Redis集群模式类似,Codis将数据划分为N个槽位(默认为1024个),每个槽位负责存储若干数据,数据与槽位之间的映射关系通过对数据Key运行CRC32算法后再与 N取模得到:
slot = CRC32(Key) mod N
在Codis中包含如下四大类核心组件。
- Codis Server:经过二次开发的Redis服务器,支持数据迁移操作。可以认为它就是Redis服务器,负责处理客户端的读/写请求。
- Codis Proxy:接收客户端请求并转发给Codis Server,其作用与Twemproxy—样, 都是中间代理。
- ZooKeeper集群:用于保存Redis集群元信息,包括每个Redis数据分片负责管理的槽位信息、各个Redis节点的地址信息。它还保存了Codis Proxy的地址列表,提供Redis客户端访问Redis集群的服务发现能力。
- Codis Dashboard和Codis Fe:它们共同组成了集群运维管理工具,前者负责Redis集群扩缩容、Codis Proxy集群扩缩容、槽位迁移等,后者负责提供Dashboard的友好Web操作页面。
Codis将Redis集群中的每个数据分片都定义为Redis Server Group。一个Redis Server Group包括一个Redis Master和若干Slave,用于保证每个数据分片的高可用。Codis整体架构如图1-39所示。
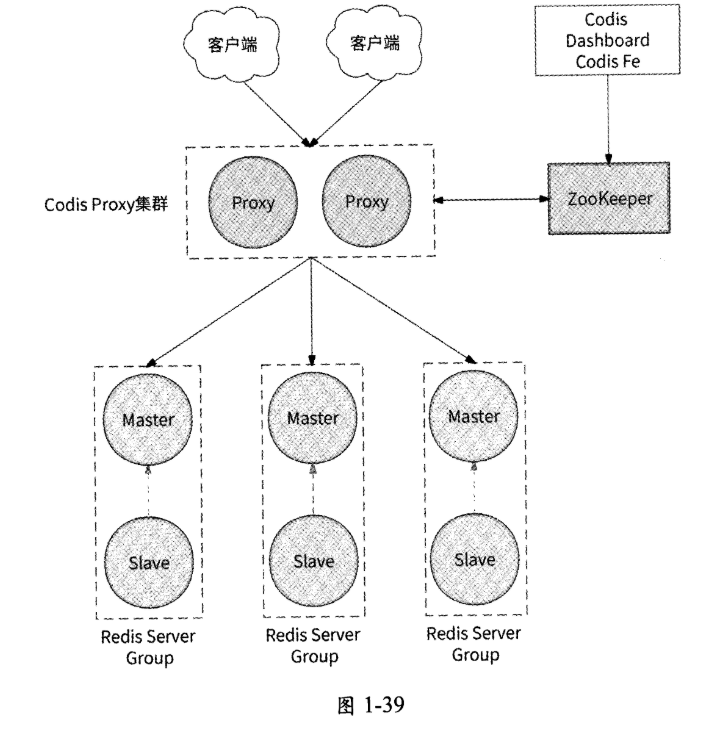
为了让Codis运行起来,我们先使用Codis Dashboard配置Redis Server Group的地址信息、所管理的槽位信息以及Codis Proxy的地址,最终这些配置信息都会被存储到ZooKeeper集群中。完成配置后,Codis就可以正式对外提供服务了。Redis客户端访问Codis的流程基本如下。
- Redis客户端从ZooKeeper集群中获取到Codis Proxy集群的地址列表,并选择一个Codis Proxy建立连接。
- Redis客户端向Codis Proxy发送数据读/写请求。
- Codis Proxy根据数据Key计算出对应的槽位,然后通过ZooKeeper集群得到负责此槽位的Redis Server Group。
- Codis Proxy将数据读/写请求转发到Redis Server Group中的某个Redis节点,其中Master可以处理数据读/写请求,Slave可以处理数据读请求。
- Redis节点处理完数据后,将结果返回给Codis Proxy。
- Codis Proxy将结果返回给Redis客户端,整个数据访问流程结束。
接下来介绍Codis如何平滑地完成集群扩缩容。在Codis中,数据迁移的单位是槽位。
假设有一个新的Redis节点B加入了集群,那么集群中的某些槽位必然要交给B节点负责。如果需要将集群中A节点负责的槽位S迁移到B节点,则流程如下。
- A节点将槽位S关联数据复制到B节点,在数据复制过程中,A节点依然对外提供服务。
- 如果客户端读/写某数据D的请求到达A节点,且此数据不属于槽位S,则A节点正常处理请求。
- 如果数据D恰好属于槽位S,但由于槽位S正在进行迁移,我们并不知道数据D是否已经迁移到B节点,所以请求无法抉择是应该被A节点处理还是应该被B节点处理。
- A节点只好强行将数据D迁移到B节点,即使数据D可能早已迁移到B节点。
- 当数据D迁移完成后,A节点再将请求转发到B节点处理,因为此时已经确定数据D已经迁移到了B节点。
至于某个节点发生故障宕机需要主从切换的场景,新版本的Codis建议每个Redis Server Group都引入哨兵模式即Sentinel节点来处理,其具体流程这里不再重复。
在如上所述的中心化集群架构模式下,只要中间代理服务器的实现足够高效,便可以轻松地将Redis客户端请求代理到成千上万台Redis服务器。所以,当Redis集群有较多的节点时,笔者非常推荐使用与Codis类似的Redis集群架构模式。
总结
什么是Redis呢?
- Redis是一个包含多种数据结构、支持网络访问、基于内存型存储、可选持久性的开源键值存储数据库。
Redis有哪些特性?
- 数据被存储在内存中,性能高。
- 支持丰富的数据类型,包括字符串(String)、列表(List)、哈希表(Hash)、集合(Set)、有序集合(Sorted Set)等数据结构和相关数据操作。
- 支持分布式,包括主从模式、哨兵模式、集群模式,理论上其可以无限扩展。
- 基于单线程事件驱动模式实现,数据操作具有原子性。
Redis有哪些高可用架构?
- 主从模式
- 哨兵模式
- 集群模式
- 中心化集群架构
Redis主从复制的工作流程?
一个Master与若干Slave组成主从关系,当Slave与Master首次建立连接时,Master向Slave进行全量数据复制,复制结束后,再根据Master的最新数据变更进行增量数据复制。
- Slave连接到Master,发送PSYNC命令准备复制数据。
- Master收到PSYNC命令,执行BGSAVE命令生成目前全量数据的RDB快照文件,并创建缓冲区记录此后Master执行的数据变更命令。
- Master向所有Slave发送RDB快照文件,并在文件发送期间持续在缓冲区记录数据变更命令。
- Slave收到RDB快照文件后将其保存在磁盘中,再从磁盘中重新加载快照数据到内存,然后开始接收来自Master的数据变更命令。
- Master发送完RDB快照文件后,继续向Slave发送缓冲区中记录的数据变更命令。
- Slave收到数据变更命令后,在本地重新执行这些命令,以保证Slave与Master的数据一致。
Redis服务器的三种角色?
- Master角色
- Slave角色
- Sentinel角色
Sentinel哨兵的作用?
- 它负责在Master宕机后自动选举出一个Slave升级为新的Master继续对外提供服务。
哨兵模式的工作流程?
- 在一个主从模式的Redis架构中会部署若干Sentinel节点,每个Sentinel节点都会与Master、Slave维持心跳。
- 当超过N个Sentinel节点认为Master宕机时,Sentinel节点会协商选举出一个Slave担任新的Master。
- Sentinel节点会告知所选举出的Slave节点它已被提升为Master,其他的Slave则转而与这个新的Master建立连接,复制数据。
为什么会出现集群模式?
- 无论是主从模式还是哨兵模式,Redis都只有一个Master对外提供服务,当有大量的数据需要存储时,单个Master的内存空间难以保存全量数据;
- 当有海量请求访问Redis时,单个Master会承受巨大的访问压力。
什么模式使得Redis真正具备分布式存储的能力?
- 集群模式
集群模式的工作原理?
- 在Redis集群中有多个数据分片,每个数据分片都通过主从模式保证高可用。
- Redis集群基于哈希槽进行数据分片:整个Redis数据库被划分为16384个哈希槽,每个Master可以管理0-16383个槽位(Slot),这些Master把16384个槽位都瓜分了。
- 当向Redis集群中写入某个数据时,会基于槽位计算公式
slot = CRC16(Key) mod 16384得到一个槽位。此数据会被归属到这个槽位上,于是会被存储到管理这个槽位的Master上。
Redis客户端访问Redis集群的流程?
- Redis客户端连接到Redis集群中的任意一个Redis节点,获取槽位与Master的 映射关系,并将该映射关系的信息缓存在客户端本地。
- 当Redis客户端要读/写数据时,首先基于数据Key运行CRC16算法,然后将结 果与16384取模得到对应的槽位。
- Redis客户端根据计算出的槽位,在本地缓存中进一步定位到具体的Master地址, 然后将数据访问请求发送到这个节点上。
什么是Gossip协议?
- Gossip协议的通信机制就像流言蜚语一样被随意传播,成为人们茶余饭后的谈资。
- 它的特点是,在一个节点数量有限的通信网络中,每个节点都会随机与部分节点通信,经过多轮迭代通信后,各个节点的信息在一定时间内会达成一致。
Gossip协议的工作流程?
- 假设Gossip协议每隔1s传播一次信息。
- 当信息被传播到某个节点时,此节点会随机选取次个相邻节点传播信息。
- 节点每次传播信息时,都会选择没有收到此信息的相邻节点作为传播目标。
- 经过多次信息传播,最终全部节点都收到了此信息。
Gossip协议包含与Redis集群相关的消息类型有哪些?
- meet:某个节点发送meet消息给新加入的节点,让新节点加入集群中并与其他节点周期性地进行ping、pong消息的交换。
- ping:每个节点都会向其他节点发送ping消息,用于相互告知自身的状态和所维护的槽位信息,同时检查其他节点是否已经宕机下线。
- pong:当某个节点接收到ping、meet消息时,使用pong消息作为响应消息返回给发送方。pong消息包含节点自身的信息数据。一个节点也可以向集群广播自身的pong消息,来通知整个集群变更此节点的状态信息。
- fail:某个节点判断出另一个节点宕机之后,就发送fail消息给其他节点,告知其他节点所指定的节点宕机了。
Redis集群中的主观下线和客观下线?
- 主观下线:A节点向B节点发送ping消息,但是没有得到回复,于是A节点主观地认为B节点下线了。
- 客观下线:如果集群中超过一半的节点均认为B节点主观下线了,按照少数服从多数的原则,B节点就会被认为客观下线了。
Redis集群采用Gossip协议有啥弊端?
- Gossip协议归根结底依赖扩散式的网络通信,集群节点的数量直接影响Gossip协议的传播范围。
- 当Redis集群中的节点只有几百个时,它可以运行良好,但是如果集群节点有成千上万个,那么Gossip协议就会造成集群内部存在大量网络通信,严重占用网络带宽,形成Gossip风暴。
Twemproxy的基本原理?
- 通过中间代理的形式,Redis客户端将请求发送到Twemproxy;
- 然后Twemproxy根据数据路由规则将请求发送到正确的Redis节点;
- 最后Twemproxy将请求执行结果汇总并返回给客户端。
Twemproxy的作用?
- 通过引入Twemproxy作为客户端访问Redis节点的中间代理,为由若干Redis节点组成的集群提供了数据分片的负载均衡能力,提高了Redis节点的高可用性和可扩展性。
Twemproxy的缺点?
- 没有友好的管理后台,不利于运维监控;
- 无法支持平滑的Redis集群扩缩容,当业务要求Redis集群增加节点时,会产生较高的运维成本。这也是Twemproxy的主要痛点。
Codis中包含的四大类核心组件?
- Codis Server:经过二次开发的Redis服务器,支持数据迁移操作。可以认为它就是Redis服务器,负责处理客户端的读/写请求。
- Codis Proxy:接收客户端请求并转发给Codis Server,其作用与Twemproxy—样, 都是中间代理。
- ZooKeeper集群:用于保存Redis集群元信息,包括每个Redis数据分片负责管理的槽位信息、各个Redis节点的地址信息。它还保存了Codis Proxy的地址列表,提供Redis客户端访问Redis集群的服务发现能力。
- Codis Dashboard和Codis Fe:它们共同组成了集群运维管理工具,前者负责Redis集群扩缩容、Codis Proxy集群扩缩容、槽位迁移等,后者负责提供Dashboard的友好Web操作页面。
Redis客户端访问Codis的流程?
- Redis客户端从ZooKeeper集群中获取到Codis Proxy集群的地址列表,并选择一个Codis Proxy建立连接。
- Redis客户端向Codis Proxy发送数据读/写请求。
- Codis Proxy根据数据Key计算出对应的槽位,然后通过ZooKeeper集群得到负责此槽位的Redis Server Group。
- Codis Proxy将数据读/写请求转发到Redis Server Group中的某个Redis节点,其中Master可以处理数据读/写请求,Slave可以处理数据读请求。
- Redis节点处理完数据后,将结果返回给Codis Proxy。
- Codis Proxy将结果返回给Redis客户端,整个数据访问流程结束。




