第12章评论服务——12.6 二级模式服务设计

第12章评论服务——12.6 二级模式服务设计
John Yaml12.6 二级模式服务设计
对于需要评论功能引发用户之间广泛互动的产品,大多采用的是二级模式评论,例如微博、bilibili等常见的亿级用户应用,所以本节将重点讨论二级模式评论服务的设计,同时引入之前尚未讨论的评论审核和按照热度排序的能力。
12.6.1 —级评论和二级评论
在二级模式的评论功能中,所有对内容的评论都将作为一级评论,点击打开内容的评论区,会看到若干一级评论的集合。每条一级评论也都有自己的二级评论区,二级评论区由对此一级评论的回复和对回复的回复共同组成。二级评论区默认一般是折叠状态的,只有当用户主动点击打开某条一级评论的评论区时,其二级评论才会被展示出来。
在二级评论区中,对一级评论的回复和对回复的回复一般按照评论发布时间由远及近排序。而一级评论由于相互之间没有互动关系,所以既可以使用传统的按照评论发布时间对其进行排序,也可以使用更为个性化的排序方式来展示一些精彩的评论,比如微博评论区支持按照热度排序和按照时间排序两种规则,默认按照热度排序。所谓热度是一个比较笼统的概念,不同产品一般采用不同的热度定义,比如点赞数、回复数、发布时间等属性都会影响评论的热度(这个话题将在12.6.5节中讲述)。
总之,在二级模式的评论功能中包括两种评论列表。
- 点击打开内容评论区,展示由一级评论组成的评论列表。
- 点击打开一级评论的评论区,展示由二级评论组成的评论列表。
二级模式评论功能的数据模型需要区分一条评论是一级评论还是二级评论 ,还需要区分一条二级评论回复的是一级评论还是二级评论,这是设计二级模式评论元信息数据的核心所在。接下来,我们分别使用数据库和图数据库来设计评论元信息数据。为了使内容逐步得到升华,我们暂且不考虑一级评论区的热度排序,还是使用时间排序规则。
12.6.2 时间顺序:数据库方案
评论元信息的数据表结构设计可以参考表12-3(为了方便编写SQL语句,先假设数据表名为t)。
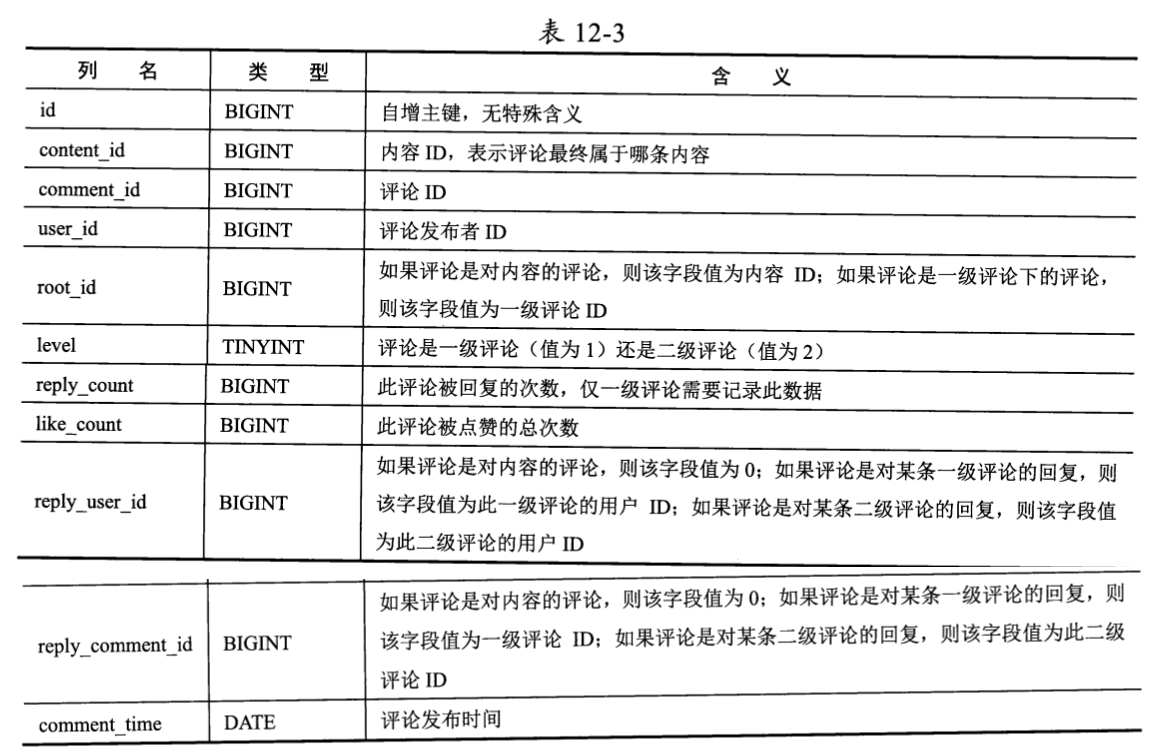
上文中提到,二级模式评论功能的数据模型需要判断一条评论是一级评论还是二级评论 ,以及二级评论回复的是一级评论还是二级评论,这个数据表可以清楚地做到这一点。
- level字段值为1,即表小是一级评论。
- level字段值为2,即表示是二级评论,且此评论属于root_id字段值指向的一级评论的二级评论区。如果reply_comment_id字段值为一级评论ID,则说明此评论回复的是一级评论;否则,说明回复的是二级评论。
例如,当用户点击打开内容111的评论区时,需要按照评论发布时间由远及近展示N条一级评论。对应的SQL语句如下:
1 | SELECT commented, user_id, reply_countr like_countz comment__time FROM t WHERE root id = 111 AND level = 1 ORDER BY comment_time LIMIT 0, N |
一级评论不仅要展示评论ID、用户ID和评论发布时间,而且要展示其二级评论区的长度和点赞数。用户继续上滑获取下一页的评论列表,无非就是使用LIMITN,N,这里不再赘述。
当用户点击打开一级评论222的二级评论区时,需要按照二级评论的发布时间由远及近展示N条二级评论。对应的SQL语句如下:
1 | SELECT comment id, user_id, like_countz comment_time FROM t WHERE root_id = 222 AND level = 2 ORDER BY comment_time LIMIT 0, N |
当用户999要查询自己发布的前N条历史评论时,需要执行如下SQL语句:
1 | SELECT comment_idr like_count, comment_time, content_id, reply_user__id, reply_comment_ici FROM t WHERE user_id = 999 ORDER BY comment_time DESC LIMIT 0, N |
为了使上面的SQL语句可以高效执行,我们创建了两个联合索引。
- idx_comment_list(root_id, level, comment_time):用于获取内容的评论区和某条评论的二级评论区的评论列表。
- idx_user_comment(user_id, comment_time):用于获取用户的历史评论。
在这里 ,我们依然创建两个结构与t数据表的结构完全一致的数据表content_comment 和user_comment,前者负责处理内容评论列表和一级评论的二级评论列表,后者负责处理用户的历史评论列表。
例如,用户999对内容111发布评论1000,对应的SQL语句如下:
1 | INSERT INTO content_comment (content_id, commented, user_id, root_idz level, comment_time) VALUES (111, 1000, 999, 111, 1,当前时间) |
用户999对内容111的一级评论222(评论发布者ID为333)发布回复1001:
1 | INSERT INTO content_comment(content_id, comment_idz user_id, root_id, level, comment_timez reply_comment_id, reply_user_id) VALUES (111, 1001, 999, 222, 2, 当前时间,222z 333) |
用户999对内容111的一级评论222下二级评论区的评论444(评论发布者ID为555)发布评论1001:
1 | INSERT INTO content__comment(content_id, comment_idf user_id, root_id, level, comment_time, reply_comment_id, reply_user_id) |
以上这些插入新评论的SQL语句都通过伪从技术被同步到user_comment数据表。
12.6.3 时间顺序:图数据库方案
在二级模式的评论功能中,除二级评论之间有回复关系外,一级评论与内容之间、二级评论与一级评论之间也存在回复关系,以内容和评论为点、以回复关系为边可以得到一个有向图,所以图数据库也是一种可用的选型。
我们仍然使用数据库来存储评论的各种元信息数据,但是评论与内容之间的回复关系、评论与评论之间的回复关系则使用图数据库来描述。图数据库作为数据库的伪从,每当有新评论数据产生时,图数据库就为内容节点与评论节点或者评论节点与评论节点建立回复关系。
这里通过一个完整的例子来介绍如何使用图数据库来获取评论列表。首先,创建内容节点和评论节点:
1 | // 创建1个代表内容的节点 |
然后,在cm1、cm2、cm3这3个评论节点与内容节点ctl之间建立回复关系,即这3条评论成为一级评论:
- CREATE (cm1)-[:Reply{comment_time:,2022-l 1-03 22:05:37*}]->(ct1)
- CREATE (cm2)-[:Reply{comment_time:,2022-ll-03 19:29:51’}]->(ct1)
- CREATE (cm3)-[:Reply{comment_time:,2022-ll-03 21:35:49!}]->(ct1)
接下来,在剩下的评论节点与待回复的评论节点之间建立回复关系,待回复的评论包括一级评论和二级评论。
1 | // 二级评论cm11回复一级评论cm1, cm12回复cm1, cm13回复cm12 |
最后,内容ct1与cm1、cm2等12条评论形成回复关系图,如图12-9所示。
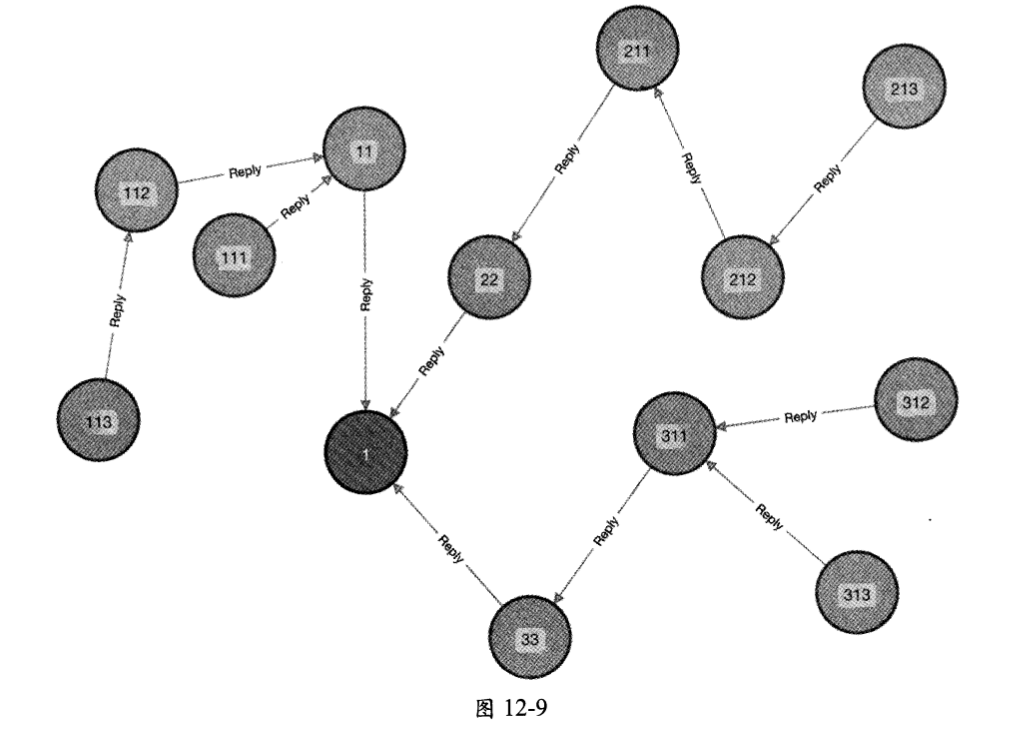
读取内容ct1的一级评论列表就是读取与ct1节点有直接回复关系的评论集合,并按照回复时间排序。对应的CQL语句如下:
1 | MATCH (ll_comment)-[r:Reply]->(Content(content_id:1)) RETURN ll_comment.comment_idr Uncomment.user_id, r.comment_time ORDER BY r.comment_time |
这条CQL语句的执行结果如图12-10所示。

读取评论cm1的二级评论列表就是读取那些与cm1节点有回复关系的节点,以及与这些节点有回复关系的节点。换言之,一个评论节点按照回复方向做深度遍历时,如果可以遍历到cm1节点,则说明此评论是评论cml的二级评论。所以,我们使用CQL语句查询多跳回复链路指向cm1节点的那些节点,它们就是评论cm1的二级评论列表:
1 | MATCH (12_comment) -[r:Reply*l *.]->(u:Comment(comment_id:11)) |
这条CQL语句的执行结果如图12-11所示。

用户1001查看自己发布的评论,就是查看属性user_id为1001的评论节点:
1 | MATCH (c:Comment{user_id:1001))-[r:Reply]->() RETURN c.coniment_idz r.comment_time ORDER BY r.comment_time DESC |
这条CQL语句的执行结果如图12-12所示。

鉴于二级模式的评论功能可以非常直观地通过回复关系构建出评论与内容之间、评论与评论之间的回复关系图,所以我们可以借助图数据库在图数据查询上的便捷性和高性能来存储二级模式评论的回复关系。
12.6.4 评论审核与状态
评论本质上是一种用户输出的内容,评论的意图和情感色彩注定其非常主观,所以,评论也是一个需要审核介入的重要场景。评论审核需要对涉及血腥暴力、谩骂攻击、垃圾广告等不合规的评论进行删除,并对评论发布者给予封号处罚。与内容发布系统章节中介绍的内容审核类似,评论审核分为所谓的机审和人审。
对于评论机审来说,其主要手段是使用自然语言处理技术对评论文本进行关键词分析,然后使用机器学习技术对评论进行类别判断,将识别出的不合规的评论删除。
而人审很直接,就是由审核人员阅读评论数据,主观判断是否要删除评论。因为用户活跃度较高的应用每天会产生动辄几千万条评论,审核人员要处理这么多数据必然是不现实的,所以人审通常只作用于满足某些条件的评论数据。
- 关键词召回:审核人员可以在评论运营后台根据关键词搜索出相关评论数据,然后对它们进行审核。比如我们的产品要对平台内的诈骗信息进行清理,审核人员可以在评论运营后台搜索“打字员”“网络键值”等关键词,然后逐个筛查相关评论 。为了支持根据关键词查询对应的评论,在评论运营后台适合选择使用Elasticsearch作为评论存储引擎,评论服务可以将数据库中已发布的评论数据通过伪从技术同步到Elasticsearch来实现。
- 热门召回:如果某条评论的曝光量达到一定的量级,则说明此评论已经对较多用户产生了影响,这种评论也是应该人审的。应用客户端可以周期性地上报每条评论被曝光的次数,由服务端做流式数据汇总,当某条评论的曝光量达到预设的阈值时,将其放入人审队列中。
- 举报召回:被举报的评论,极有可能是不合规的评论,所以也要人审。服务端需要监听评论举报事件,将对应的评论同样放入人审队列中。
以上是三种最基本的人审评论召回渠道。不同公司根据其业务特征的不同,可能会有更多个性化的召回渠道。无论是何种召回渠道,当审核人员认为某条评论不合规时,都需要将此评论标记为“不可见”(对于用户来说,就是此评论被删除了),这就要求评论元信息记录评论的状态。
评论元信息需要使用状态来表示评论的可见性,而且除了粗犷的可见、不可见状态,评论往往还有更精细的其他状态。
- 全员可见:所有人都能看到此评论。
- 仅好友可见:仅相互关注的好友能看到此评论。
- 自见:只有评论发布者可以看到此评论,评论发布者会认为自己已经发布了评论。
- 审核中:已被审核召回的评论处于审核中状态,此时评论的可见性与自见相同。
- 删除:审核没通过的评论会被标记为此状态,任何人都看不到此评论。
- 神评论:评论审核不只是对不合规的评论进行删除,还会把最热门的评论标记为“神评论”,以便对可提高用户活跃度的评论进行正向鼓励。一些搞笑应用如最右、皮皮虾等会对神评论进行置顶展示并赐予神评论勋章 ,有些应用还会对神评论做热评活动,比如网易云音乐等。
在评论元信息数据库中还需要增加评论状态字段,并包含以上各种状态的枚举值。当用户读取评论列表时,每条评论是否可以被用户读取到视其状态而定。
- 如果评论被删除了,那么用户一定不能读取到此评论。
- 如果评论处于自见状态(自见或审核中),那么用户必须是评论发布者才能读取到此评论。
- 如果评论处于非自见状态,但是仅好友可见,那么用户必须是评论发布者的好友才能读取到此评论。
- 非上述三种类型的评论,任何用户都可以读取到。
由此可见,即使是读取同一个评论区的评论列表,不同用户看到的评论也有可能不同。当评论服务向数据库请求读取评论列表时,SQL语句无法轻易做到对评论状态的筛选,所以SQL语句无须判断评论状态,而是从数据库中读取评论列表后,评论服务再根据每条评论的状态进一步做业务层过滤。
12.6.5 按照热度排序
在讨论完基于评论发布时间对评论列表排序后,我们再来讨论如今非常流行的按照热度排序规则。目前很多互联网应用都选择在评论区优先展示一些热度较高的一级评论,这些评论往往被证明是具有话题性或者优质的评论,把它们优先展示出来可以使评论区变得更有吸引力,从而增加用户黏性。
既然是按照热度排序,那么就要先数字化度量一条评论有多热门。不同应用因业务的不同可能有不同的度量标准,一些简单的标准如下。
- 点赞数:评论被点赞的次数越多,评论就越热门。
- 回复数:评论被回复的次数越多,评论就越热门,即其二级评论列表的长度越长,评论就越热门。
- 点赞数与回复数加权:点赞数和回复数一起反映一条评论的互动性,热度可以是两者做比重加权,比如将“点赞数 × 0.4 + 回复数 x 0.6”作为热度值。
评论的热度一般用加权方式来度量,且可能有除点赞数、回复数之外的其他参考指标,比如有的产品会参考评论的积极性:越早抢占评论区“沙发”的评论,越是给予正向激励,具体需要根据各产品的业务特点来决定。
对于按照热度排序的评论列表,有如下几个重点要说明。
- 按照热度排序,并不意味着一个评论区中的所有评论都遵循此规则。当我们打开评论区时,首先展示的是热度排名前1000(一个示例值)的评论,在评论区中刷完这1000条评论后,我们看到的依然是按照评论发布时间由近及远排序的评论。
- 如果一条评论没有任何点赞,没有任何回复,即热度值为0,则其不属于热门评论,故不参与热度排名。如果一个评论区中只有50条热门评论,那么用户打开评论区刷完这50条评论后,展示的是按照评论发布时间排序的评论列表。
- 在刷完热门评论后,按照评论发布时间排序的评论列表中依然可能会包含热门评论 ,也就是说,用户会刷到重复的评论。对此感兴趣的读者可以试着阅读一条微博的全部评论,就会发现热门评论会重复出现在按照评论发布时间由近及远排序的评论列表中。
我们需要为满足热门评论的一级评论构建热度排名,但无论是12.6.2节介绍的数据库 方案,还是12.6.3节介绍的图数据库方案,一级评论都已经按照评论发布时间排序了,在此基础上很难做到再按照热度排序,况且热度值的计算规则极有可能是加权的。
实际上,我们往往可以使用独立的存储系统来保存按照热度排序的评论ID列表,它从基本的全量评论元信息数据库中筛选出热门评论ID并按照热度排序进行存储,在用户读取前1000条评论时展示对应的评论数据。一种可行的方案是选择使用Redis存储系统来维护热门评论,并使用ZSET对象表示一个内容评论区中按照热度排序的评论ID列表集合,其中Key为hot_comment_{content_id}, Member为评论ID,Score为评论的热度值。接下来讲解此方案的技术细节。
首先,构建实时的热门评论ID列表。以点赞数与回复数的加权度量方式为例,由于一条一级评论在收到点赞、回复时,此评论的热度也会发生相应的变化,所以需要监听评论的点赞事件和回复事件。当点赞事件和回复事件发生后,根据此评论的最新点赞数和回复数重新计算热度值并写入ZSET中,以达到评论热度排名实时更新的目的。如果一条评论被删除了,那么在热门评论列表中应该同时删除此评论,所以也需要监听评论被删除的事件。我们需要创建消费者服务hot_comment_trigger,通过消息队列监听评论的点赞事件、回复事件和删除事件,负责热门评论的实时构建工作。假设在内容1的评论区中一级评论22的当前点赞数是10,回复数是8(热度值=10 × 0.4 + 8 × 0.6 = 8.8), 那么此评论依次收到点赞、回复以及此评论被删除时,消费者服务hot_comment_trigger的工作流程如下所述,如图12-13所示。
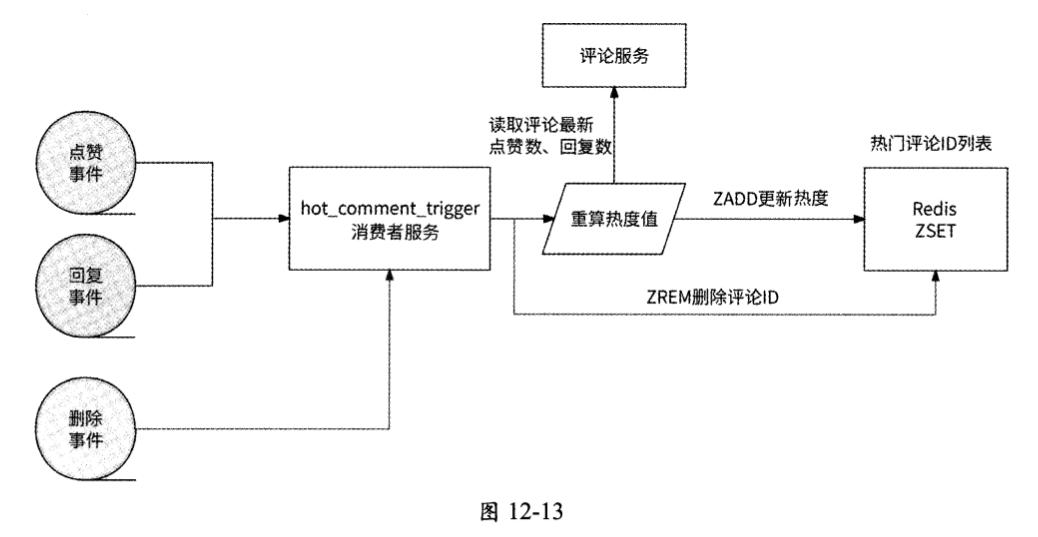
- 评论22收到一个点赞,即当前点赞数变为11。
- 消费者服务hot_comment_trigger收到评论22的点赞事件,说明评论22的热度需要更新,于是从评论元信息的content_comment数据表中获取其最新的点赞数和回复数,得到11和8。
- 消费者服务hot_comment_trigger重新计算评论22的热度值为11x0.4+8x0.6=9.2。
- 消费者服务hot_comment_trigger对内容1的热门评论列表更新评论22的热度,向Redis ZSET对象发起请求:
ZADD hot_comment_1 9.2 22。 - 评论22又被回复一次,即当前回复数变为9。
- 消费者服务hot_comment_trigger收到评论22的回复事件,从content_comment数据表中得到它的最新点赞数为11,回复数为9。
- 消费者服务hot_comment_trigger重新计算评论22的热度值为11x0.4+9x0.6=9.8。
- 消费者服务hot_comment_trigger对Redis更新评论22的热度:
ZADD hot_comment_1 9.8 2。 - 评论22被删除,消费者服务hot_comment_trigger收到此事件。
- 消费者服务hot_comment_trigger从Redis ZSET中删除此评论:
ZREM hot_comment_1 22。
其次,按照热度排序和按照评论发布时间排序的评论组成分页的评论列表。在按照热度排序的评论区中,并不是全部评论都遵循此规则,而是先展示最多1000条按照热度排序的评论,再展示按照评论发布时间由远及近排序的评论。用户的一次刷评论请求只读取某一页的评论,比如10条评论,假设目前在内容1的评论区中有16条热门评论,那么第1页的评论全部来自热度序评论列表,第2页的评论来自热度序评论列表和时间序评论列表的组合;第3页至最后一页的评论全部来自时间序评论列表。
用户在请求读取评论列表时,评论服务需要区分出是从热度序评论列表中获取数据,还是从时间序评论列表中获取数据,抑或是从两者的组合中获取。我们来具体分析一下。
用户分页读取评论列表,必要参数是内容ID、当前已读评论数的偏移量(offset)。下面分析用户读取内容1评论区的前3页评论的情况。
- 首次打开评论区,即读取第1页的评论,此时必然需要请求热度序评论列表,因为产品约定热门评论优先展示,且希望读取10条评论。内容1有16条热门评论,热度排名前10的评论被返回。
- 用户读取第2页的评论,且仍然希望读取10条评论。但是内容1只剩6条热门评论,此时还需要从时间序评论列表中拉取前4条评论组合起来返回给用户。
- 用户读取第3页的评论,由于上一页已经开始展示时间序评论列表中的评论了,所以此时需要拉取时间序评论列表中的第5~14条评论返回给用户。
通过以上三步我们可以看到一些重要细节。
- 第 1页的评论,一定要先读取热度序评论列表。
- 其他页可以将上一页最后一条评论的来源作为此次读取评论的来源,最后一条评论来自热度序评论列表就读取热度序评论列表,来自时间序评论列表就读取时间序评论列表。
- 当从读取热度序评论列表转换为读取时间序评论列表时,当前已读评论数的偏移量应该被重置为时间序评论列表的偏移量。
所以,当用户分页读取评论列表时,评论服务的响应除了返回评论数据,还要返回最后一条评论的来源。
对于客户端读取评论列表的请求,同样应该引入一个参数,来指定此次请求的读取评论的来源。此参数是上一页响应得到的数据来源,暂时将此参数命名为from_where,其可选值为hot(热度序评论列表)和time(时间序评论列表)。下面分析客户端读取内容1评论区的前3页评论的情况。
- 客户端读取第1页的评论,请求参数为(content_id=1, offset=0, from_where=’hot’)。评论服务在收到请求后,按照from_where参数的要求访问Redis ZSET对象获取前10条热门评论,执行语句:ZREVRANGE hot_comment_1 0 9,返回10条评论的评论ID,并告知客户端from_where为hot,offset为10。
- 客户端读取第2页的评论,请求参数为(content_id=1, offset=10, from_where=’hot’)。评论服务在收到请求后,按照from_where参数的要求访问Redis ZSET对象获取第11~20条热门评论,执行语句:ZREVRANGE hot_comment_1 10 19。由于热门评论一共只有16条,所以此次只得到6条热门评论。此时评论服务转而从时间序评论列表中获取前4条评论,即在SQL语句中设置LIMIT 0, 4。在组合这10条评论后,告知客户端from_where time, offset为4。
- 客户端读取第 3 页的评论,请求参数为(content_id=1, offset=4, from_where=’time’)。评论服务在收到请求后,按照from_where参数的要求访问时间序评论列表,获取第5~14条评论,即在SQL语句中设置LIMIT 4,10。在得到若干评论后,告知客户端from_where为time, offset为14。
如此一来,客户端分页读取评论列表可以无缝地从热度序评论列表切换到时间序评论列表。
最后,控制热门评论的总数。在一个内容评论区中,有热度的评论可能超过1000条,我们没必要在Redis ZSET对象中保存全部热门评论,只需要截取热度排名前1000的评论就好。这样做,一方面可以防止浪费Redis的内存空间,另一方面可以保持ZSET对象不会成为大Key。截取前1000条热门评论的方法很简单,我们使用一个脚本周期性(如10s)地执行如下操作来截断ZSET。
- 执行ZCARD hot_comment_(content_id)命令,得到ZSET对象的长度N。
- 如果N大于1000,则执行ZREMRANGEBYRANK hot_comment_{content_id} 0 N-1000-1命令删除前N-1000个成员(ZSET按照Score值从小到大排列,ZSET的前N-1000个成员之后的成员才是热度Top 1000,故删除前N-1000个成员)。
这里仅以存储选型为Redis的 ZSET对象介绍了按照热度排序的评论列表方案,但这并不代表这种方案是最优的,使用图数据库也是一种可行的方案。
12.6.6 高并发处理
二级模式评论作为大部分海量用户应用的强大功能,也免不了存在高并发问题。对于高并发的写评论来说,依然采用异步写和写聚合解决方案来处理,与在12.4.4节讨论的单级模式评论功能的内容高度一致,这里不再赘述;而对于高并发的读评论来说,由于二级模式的评论功能与单级模式的评论功能有不同的数据模型,所以需要单独讨论。
其实到目前为止,我们讨论的通过评论服务实现读评论的流程是不完整的。在读取按照热度排序的评论列表时,实际上只从Redis ZSET对象中读取到若干已排序的评论ID,还需要读取这些评论对应的元信息,以及从分布式KV存储系统中获取这些评论的文本。在读取按照评论发布时间由近及远排序的评论列表时,虽然从数据库中读取到了已排序的评论元信息,但是依然要获取这些评论的文本。使用评论服务构建完整的评论列表主要分为三步。
- 获取应该展示的评论ID列表,来源可能是热度序评论列表或时间序评论列表。
- 批量获取评论列表中每条评论的元信息,来源是数据库。
- 批量获取评论列表中每条评论的文本,来源是分布式KV存储系统。
评论元信息数据表通过索引实现了评论按照时间排序,所以前两步是合并执行的。构建完整评论列表的示意图如图12-14所示。
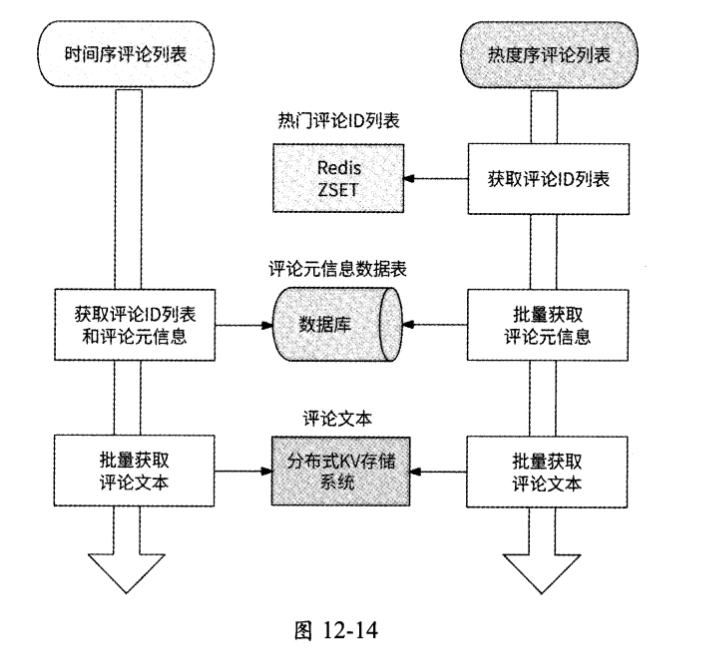
与其他列表数据类型场景类似的是,在读取评论列表的高并发请求中,大部分请求实际上访问的都是前几页评论数据,毕竟很少有用户会花时间一直刷一个评论区。前几页评论数据就是前N条评论,这N条评论可能全部来自热度序评论列表、时间序评论列表或者两者的组合,所以无论是热度序评论列表还是时间序评论列表,都可能会面临高并发请求的问题。下面我们根据图12-14来分析两者的性能瓶颈分别在哪里。
- 热度序评论列表:获取热门序评论ID列表,读取的是Redis ZSET对象,高并发性能表现没什么问题;根据若干评论ID批量获取评论元信息,则是直接访问数据库,数据库有被击垮的风险。
- 时间序评论列表:获取时间序评论ID列表和对应的评论元信息,需要直接访问数据库,数据库同样无法应对高并发请求。
可见,存储评论元信息的数据库成为两种排序场景中读取评论列表的共同瓶颈点,所以我们应该对数据库构建Redis缓存数据。那么,应该使用哪种Redis对象缓存数据呢?对于热度序评论列表,希望从缓存数据中批量获取评论元信息;而对于时间序评论列表,不仅希望批量获取评论元信息,而且希望获取按照评论发布时间由近及远排序的评论ID列表。但无论使用的是String、Hash、List还 是Set、ZSET对象,Redis都没有高效的办法兼顾两种数据访问形式,所以我们为这两种数据访问形式使用了两种Redis对象。
- 对于希望访问时间序评论列表的形式,缓存可以基于ZSET对象来存储与每条内 容前N条评论的发布时间最近的一级评论ID,其中Key为cache_time_ {content_id}, Member为评论ID,Score为评论发布时间。
- 对于希望批量获取评论元信息的形式,缓存选择使用String对象来存储每条一级评论的元信息,每条一级评论的元信息都被以JSON形式存储到Value中,并将
meta_{content_id}_{commented}作为Key,执行MGET命令便可以批量获取评论元信息。另外,本书中多次提到,在Redis集群中执行MGET命令获取的Key只在访问一个Redis分片时性能最佳,所以我们为前缀meta_{content_id}打上hashtag标签,这样Redis集群可以保证同一条内容下的一级评论被存储到同一个Redis分片中。
在上面的流程中,需要从分布式KV存储系统中获取评论文本,我们可以进一步将文本作为评论元信息的一个属性加入String对象中,减少对分布式KV存储系统的访问,再次提升读取性能。
为了减轻Redis作为中心化缓存的访问压力,我们还可以引入本地缓存。评论服务将最近访问量较大的数据直接缓存在本地内存中:如果某内容的评论区访问量较大,则本地缓存前N条热度序评论id列表和前N条时间序评论ID列表;如果某条评论的最近曝光量较大,则本地缓存此评论的全部数据。
最终评论服务处理读取评论列表请求的架构由本地缓存、Redis、数据库和图数据库组成,其工作流程如图12-15所示。
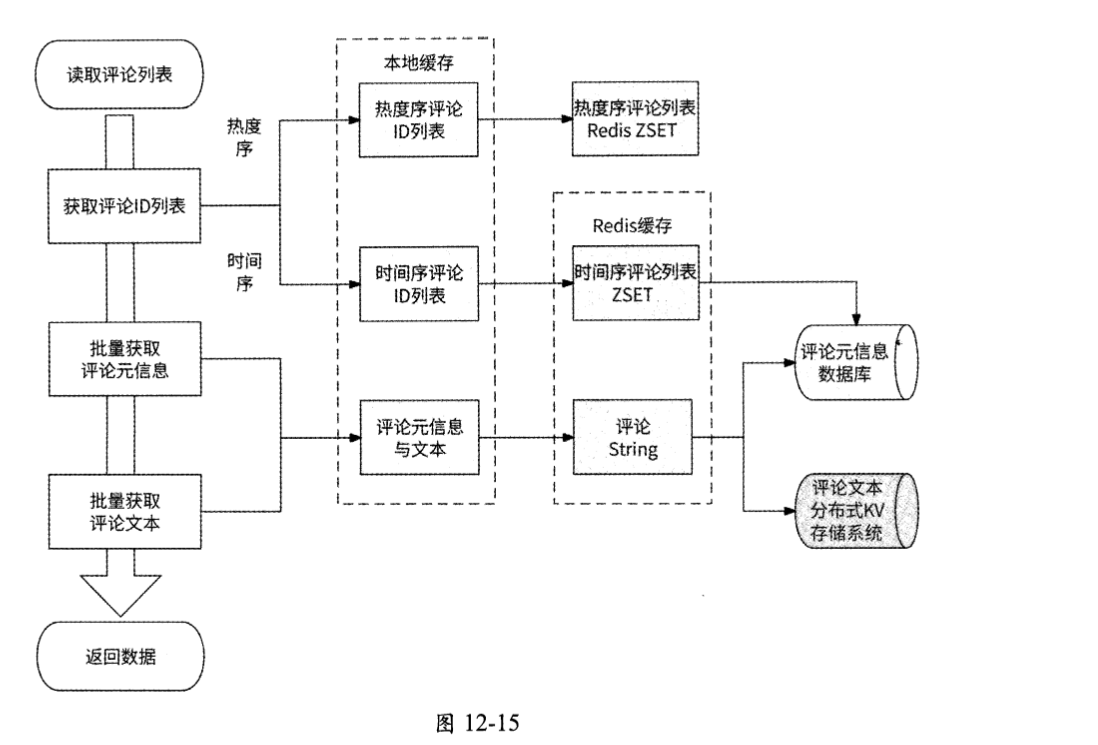
当用户访问某页的10条评论时,评论服务先执行第一部分流程,即获取评论ID列表。
- 检查请求希望访问的数据方向,如果要访问热度序评论列表,则执行下一步;如果要访问时间序评论列表,则执行第4步。
- 访问热度序评论列表的本地缓存,如果命中本地缓存,则执行下一步;否则,进一步访问热度序评论列表的Redis缓存。
- 如果可以得到10条热门评论数据,则完成此流程;如果得不到相应的数据,或者剩余的热门评论数量不足10条,则继续访问时间序评论列表。
- 准备访问时间序评论列表,先访问时间序评论列表的本地缓存,如果命中本地缓存 ,则完成此流程。
- 如果未命中本地缓存,则访问时间序评论列表的Redis缓存;如果命中Redis缓存 ,则完成此流程。
- 如果未命中Redis缓存,则访问数据库,得到评论ID列表。
在执行完第一部分流程后,如果评论服务获取到若干评论ID列表,则继续执行第二部分流程,即批量获取评论元信息。
- 访问评论元信息的本地缓存,如果所有评论都命中本地缓存,则直接返回。
- 对于未命中本地缓存的评论ID ,则通过这些评论ID继续访问Redis缓存。
- 访问Redis缓存批量获取评论元信息,如果所有评论都命中Redis缓存,则直接返回。
- 对于未命中Redis缓存的评论ID ,则访问数据库获取评论元信息。
- 将访问数据库得到的评论元信息结果存储到Redis缓存和本地缓存中。
在执行完第二部分流程后,如果每条评论都来自本地缓存或Redis缓存,则说明已经得到评论文本,可以直接返回响应了;否则,对于那些需要访问数据库才能得到的评论,继续执行第三部分流程,即批量获取评论文本。
- 批量从分布式KV存储系统中读取评论文本。
- 将评论文本加入Redis缓存的评论元信息数据库中。
- 将评论文本加入本地缓存的评论元信息数据库中。
在执行完全部流程后,评论服务将最终数据返回。
12.6.7 架构总览
在介绍完评论服务设计的主要技术细节后,我们总结一下评论服务的架构。
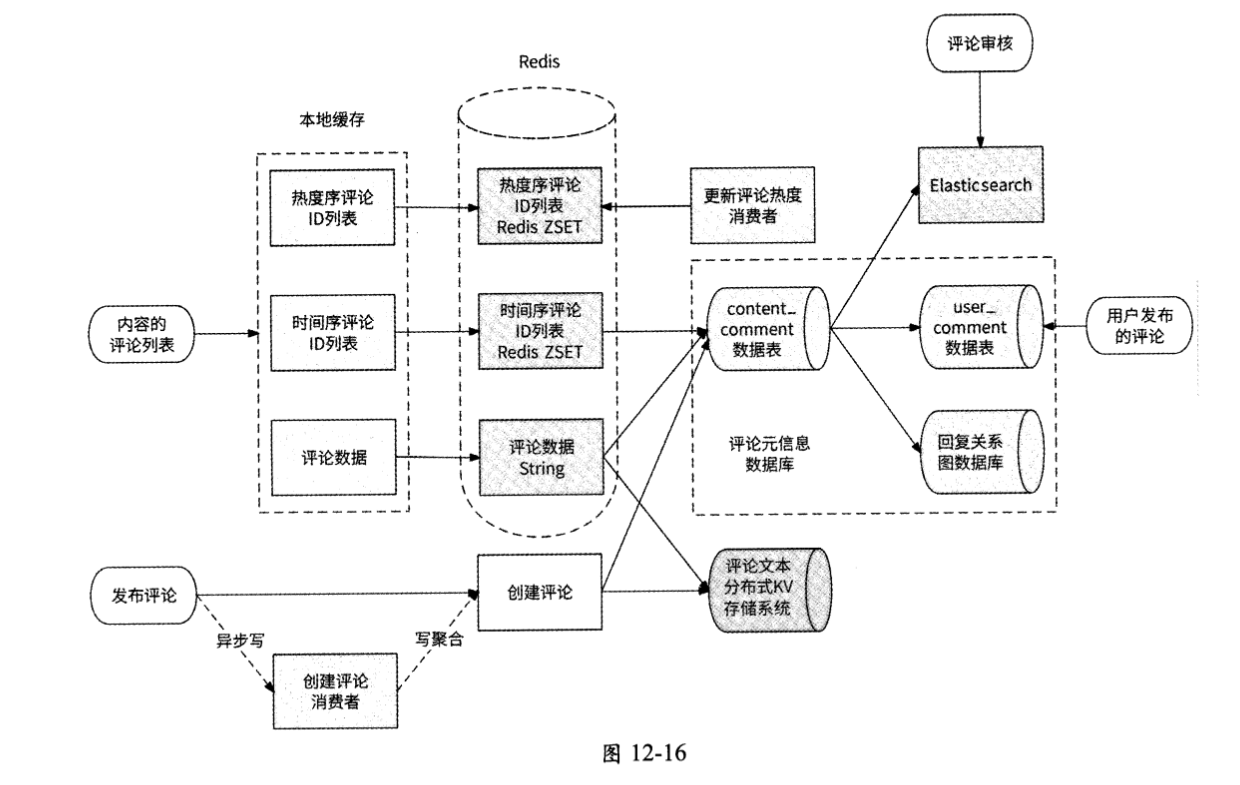
评论数据分为评论元信息和评论文本,前者主要指评论的发布者、发布时间、点赞数、回复数等元信息,适合使用数据库存储;后者指用户实际发布的评论内容,适合使用分布式KV存储系统存储。
发布评论的逻辑相对简单,在创建评论后,评论服务先把评论文本存储到分布式KV存储系统中,再把评论元信息存储到数据库中即可。如果发布评论的请求量级达到数据库无法承载的地步,则可以采用异步写和写聚合的策略:评论服务把所创建的评论放到消息队列中,由专门的消费者把评论均匀地写到数据库和分布式KV存储系统中。如果某条内容被多人评论,则可以聚合这些评论的创建请求,降低数据库的访问压力。
在进行评论审核时,可以根据关键词搜索评论数据,这个功能只有搜索引擎Elasticsearch擅长,每当有评论被创建时,评论元信息数据库都需要告知Elasticsearch,让其新增可进行搜索的评论数据,所以在Elasticsearch与评论元信息数据库之间需要建立伪从关系。
读取评论则是最复杂的逻辑,无法进行简单处理,其复杂性主要受如下影响。
- 用户可以读取某条内容下的评论列表和自己发布的评论,前者以内容为起点,后者以用户为起点,所以为了保持分库分表的高效率,在评论元信息数据库中只能冗余建立面向内容的数据 表 content_comment和面向用户的数据表user_comment, 其中content_comment数据表为主表,user_comment数据表作为其伪从来同步评论元信息数据。
- 在读取某条内容的评论列表时,还区分了一级评论列表和二级评论列表,其中一级评论回复的是内容,二级评论回复的是一级评论或另一条二级评论。在数据库中可以引入level字段来表示评论的层级,我们也可以使用图数据库来专门描述这种回复关系。
- 某条内容的一级评论可以按照热度排序,且评论区是热度序评论列表与时间序评论列表的组合。热度序评论ID列表需要使用专门的存储系统(本章中使用的是Redis ZSET对象)来维护,每当有任何影响某条评论热度的事件发生时,我们都需要通过异步事件消费者来重新计算和更新评论热度,以保证热度序评论列表的实时性。
- 读取评论列表的高并发问题。读取评论列表分为读取评论ID列表(时间序评论列表或热度序评论列表)、读取评论元信息和读取评论文本3步,不仅需要缓存每条评论数据,而且需要缓存某条内容的时间序评论ID列表,缓存形式包括Redis缓存和本地缓存。Redis缓存需要选择合适的对象,评论数据可以使用String对象存储,而评论ID列表适合使用ZSET对象存储。
评论服务的最终架构如图12-16所示。
本章小结
评论和内容非常相似,评论数据分为评论元信息和评论文本。对于评论文本,很适合使用分布式KV存储系统存储;对于评论元信息,则需要考虑存储选型和数据模型设计。本章以评论功能的多种评论列表模式展开,讨论了评论服务的设计要点。最常见的评论列表模式包括单级模式、二级模式和盖楼模式。不同模式的评论展示诉求不同,自然要求评论元信息有不同的侧重点。
单级模式是最简单的评论列表模式,它基本满足评论功能的互动性,包括内容发布者可以知道哪些用户发布了哪些评论,以及评论发布者可以得知谁回复了他的评论。单级模式的评论功能可以直接基于数据库实现,我们只需要简单地记录评论回复了哪条内容,以及评论回复了哪条评论即可。单级模式适合那些不强调社交属性的互联网应用,它的定位是满足评论功能。
盖楼模式是一种特殊的评论列表模式,通过每条评论都可以回溯到完整的回复链路,它更像是一种接力。使用数据库实现盖楼模式评论比较吃力。因为追溯一条评论的完整回复链路要么需要借助低效的递归查询,要么需要把完整的回复链路保存下来,所以数据库只适合那种楼层注定不会太高的场景。对于楼层较高的场景,图数据库是一种比较适合的选型,因为所谓的盖楼评论就是对一条评论按照回复关系进行深度遍历。
二级模式是最常见的、最被认可的一种评论列表模式,它可以清楚地反映出谁对内容发表了意见、谁对评论发表了意见,评论互动性极强,而且方便按照热度排序以进一步吸引用户,广泛受到各大面向用户社交的互联网应用的青睐。因此,二级模式评论也是本章的重点内容。如果使用数据库方案,则不仅要记录每条评论回复的对象是谁,而且要记录评论所处的层级:是一级评论还是二级评论。图数据库也是合适的选型,它实际上就是内容与评论组成的回复关系图。在二级模式评论下,我们还讨论了如何支持按照热度排序的评论列表。这种评论列表实际上优先展示的是热门评论,然后展示的是热度序评论和时间序评论的组合,其重点是评论服务应该为热度序评论列表和时间序评论列表分别建立评论ID列表存储系统,并可以明确区分什么时候访问热度序评论列表,什么时候访问时间序 评论列表。
此外,评论也是用户发布的主观言论,评论审核是必不可少的环节。与内容审核一样,评论也会经过机审和人审的环节。
评论功能注定是一个读多写多的场景。对于高并发的写评论而言,可以借助消息队列的异步写方式对流量进行削峰填谷,还可以对同一条内容的评论进行聚合,减少写请求量;对于高并发的读评论而言,我们把读取评论列表的流程拆分为获取评论ID列表、批量获取评论元信息和批量获取评论文本3步。通过分析,可以对热度序评论ID列表、时间序评论ID列表和每条评论的完整信息进行适当的缓存,可能的缓存形式包括Redis缓存和对最近热门内容、热门评论的本地缓存。




