第7章内容发布系统——7.6 内容展示设计

第7章内容发布系统——7.6 内容展示设计
John Yaml7.6 内容展示设计
前面已经完成了对内容创建、内容修改、内容审核、内容删除、内容分发的流程设计,本节将详细介绍内容展示设计,这是本章要讲解的最后一个重点功能。
用户读取内容,直观来看,是用户与数据库的item_info表、分布式KV存储系统(内容文本的存储源)、分布式对象存储系统(图片和视频的存储源)的交互。不过,出于应对高并发请求量的考虑,实际上这里需要引入更多的机制。让我们先从内容数据的特点入手。
7.6.1 内容数据的特点
内容生产是一个天然的读多写少且读远多于写的场景,创作者修改内容的请求量极少,用户读取内容的可能性极大。
对于一般的互联网应用的内容,由于用户创建和修改内容有一定的操作成本,所以注定了内容的创建和修改场景的请求量级不会太高。它的QPS一般是百级别的,如果QPS上千,那么几乎可以称得上国民级应用了。总体上,内容生产的高并发情况很少,且内容生产对内容生效的响应时间容忍性相对宽松,所以对应的高并发处理方式相对简单。即在高并发的内容创建和修改的极端情况下,对内容的发布或修改进行异步化处理,将发布或修改的内容投递到消息队列中,内容发布系统的消费消息队列进行内容的创建、修改或者通过审核,待发布成功后再通知用户。
虽然互联网应用的内容创建和修改的请求量级一般不会很高,但内容读取有可能是高并发场景。
- 一个优秀的内容创作者发布了足够吸睛的作品,往往会引来大量围观;
- 一个一线明星的绯闻爆料内容,会吸引亿万“吃瓜”群众围观;
- 一个政治、经济、军事类账号发布的新闻,甚至可以直接引起全国人民的实时关注
- ……
可以说,内容读取的QPS的日常状态达到上百万都很正常。
根据我们的设计,对一条内容的读取包括对内容元信息的读取(来自 item_info表)和对内容主体的读取,这两部分承载高并发的读请求往往有不同的策略。
7.6.2 使用CDN加速静态资源访问
对于静态数据,比如长文本、图片、视频,非常适合采用CDN(Content Delivery Network,内容分发网络)技术来应对其高并发的读请求。
简单来说,CDN就是把静态资源缓存到位于多个地理位置的边缘服务器上,当用户请求静态资源时,把用户的请求转发到附近的边缘服务器上实现就近访问。CDN技术一方面能很好地解决数据就近访问问题,另一方面能很好地缓存静态资源。
CDN的简单架构如图7-6所示。
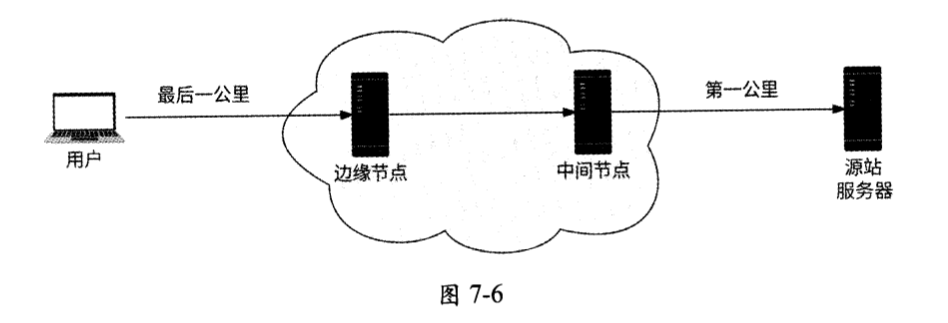
CDN技术的关键术语如下。
- 边缘节点:缓存用户请求内容的节点,是用户实际访问的服务器。
- 中间节点:CDN的内部节点,能缓存更多的内容。中间节点与边缘节点之间的网络是经过优化的,速度可观。如果用户在边缘节点访问不到数据,则会从中间节点访问或者经过中间节点回源。
- 源站服务器:真正的远端服务,中间节点可以从源站服务器获取数据,即“回源”。
- 第一千米:中间节点到源站服务器的连接。
- 最后一千米:用户到边缘节点的连接。
当某个静态资源被首次访问时,由于CDN边缘节点并未对它进行缓存 ,所以此时CDN中间节点会向源站服务器回源:获取静态资源,并将其缓存到边缘节点。在此之后,任何用户请求同样的静态资源时,都会在CDN边缘节点发现数据并响应,用户请求不再对源站服务器进行访问,这极大地缓解了源站服务器的带宽压力,且大大提高了静态资源在用户侧的加载速度。
总之,对于内容发布系统中的内容主体数据,比如图片、视频,可以通过接入CDN的方式来应对大量请求。
7.6.3 使用缓存和多副本支撑高并发读取
内容元信息属于非静态数据,发布者和产品后台可能都会对内容元信息进行修改,并要求近实时生效。比如发布者因“手滑”发布了一条本不想对外展示的内容,于是很急迫地删除内容,希望这条内容立刻消失。又比如产品后台希望对某条不健康的内容进行封杀,为了尽快止损与消除舆论风波,相关处理人员要求实时删除内容。
内容元信息被存储在关系型数据库中,为了应对高并发的读取请求,可以使用Redis对元信息数据进行中心化缓存,防止读请求直接访问数据库。
- 内容元信息使用Redis Dict结构存储,Key=content_{item_id},Dict中的每个存储项Field都是item_info表的字段,而Value是item_info表中各字段的值。
- 在读取某内容(内容ID为item_id)元信息的Redis缓存项时,执行HGETALL content_{item_id}命令便可获取此内容元信息。
但是这样还不足以承载上百万级QPS,因为这条内容的元信息数据在Redis集群中最多占用一个Redis实例分片,让单个Redis实例承载上百万的请求量依然有较高的风险。我们可以进一步优化。
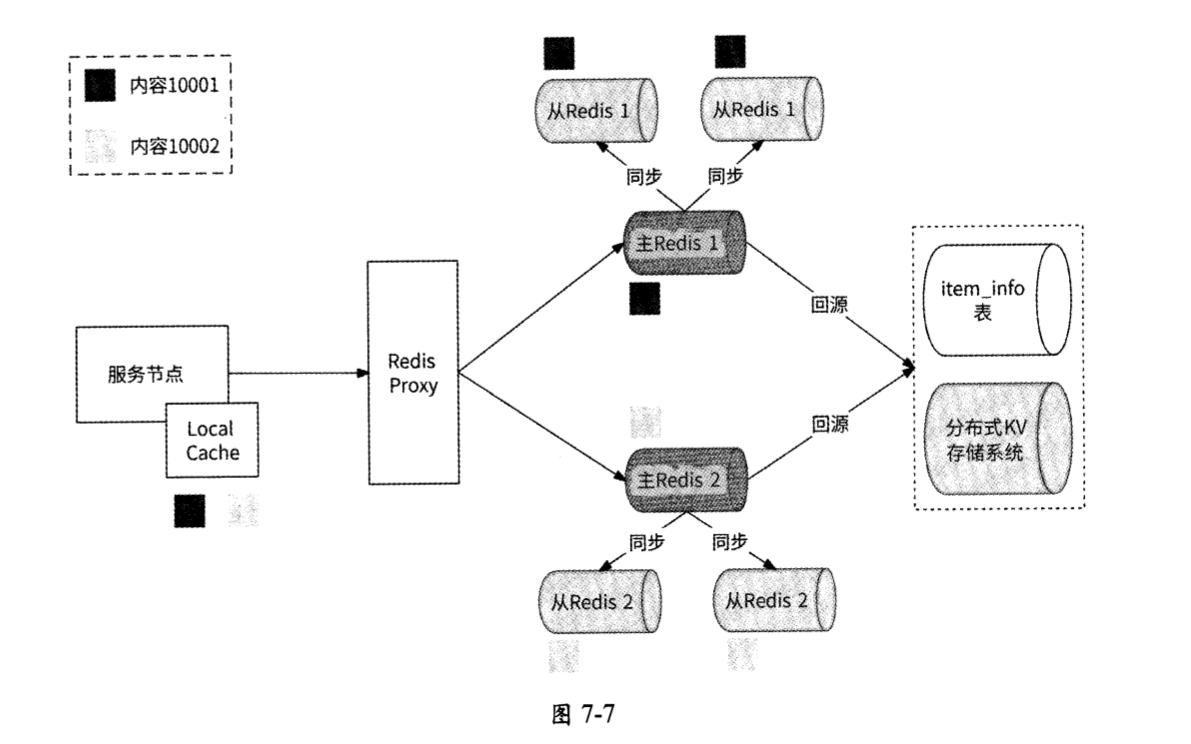
- 对Redis集群中的每个实例分片都采用主从架构,将一条内容的多个副本保存到多个Redis从节点上,尽量将对一条内容的读取分散到各个Redis从节点上。
- 对读取内容的服务节点增加Local Cache,同样将content_{item_id}作为缓存项Key,将内容元信息的数据结构体作为缓存项Value。Local Cache会尽量让请求在服务节点的本地内存中寻找内容元信息,而不是通过网络访问Redis。当然,需要注意的是,Local Cache毕竟使用的是服务节点的本地内存,应该控制缓存总量不要太大,需要使用一定的缓存淘汰策略如LFU来维护缓存总量。
将 Local Cache和Redis作为多级缓存策略,将Redis主从架构作为多副本策略,两者相互配合可以兜住大多数情况下的高并发读请求。
另外,可能有读者留意到,在7.6.2节中并没有提到短文本,这是笔者为了将短文本的缓存留到本节来讲而故意为之。短文本本身占用的空间不足1KB,可以将其视为普通的字符串数据。如果使用对象存储系统来存储短文本,则显得有点小题大做。所以,短文本的缓存方式和内容元信息的一致,也是基于Local Cache和Redis进行缓存的,并且可以和内容元信息的缓存数据合成一条缓存数据。
- 为Redis中内容元信息的Diet结构增加field=”short_text”,将短文本字符串作为其Value。
- 为Local Cache中缓存的内容元信息的数据结构体增加类型为String的short_text字段,用于存储短文本字符串。
这样一来,在读取内容元信息的缓存数据时,顺便就读取了内容的短文本数据。内容数据的缓存架构如图7-7所示。
如果Redis主从节点数量有限,或者Local Cache的缓存命中率不高,那么我们还可以采用另一种形式的多副本缓存策略不是对存储节点做多副本,而是对内容元信息的数据本身做多副本。
具体而言,就是在Redis中将过热的内容元信息的Dict数据拆分为N份数据拷贝,每份数据拷贝都使用不同的Redis Key,Key=content_{content_id}_{shared_number},其中shared_number为N 的模;每份数据拷贝的Dict结构都是完全一样的。这样的拆分会使得 一份内容元信息数据被存储到Redis集群中最多N个Redis节点上。
图7-8展示了N=3的情况,我们将item_id=123的内容元信息的Dict缓存数据拷贝了 3份,并为每份数据拷贝都设置了不同的Redis Key,以便将各数据拷贝尽量映射到Redis集群中不同的Redis节点上。
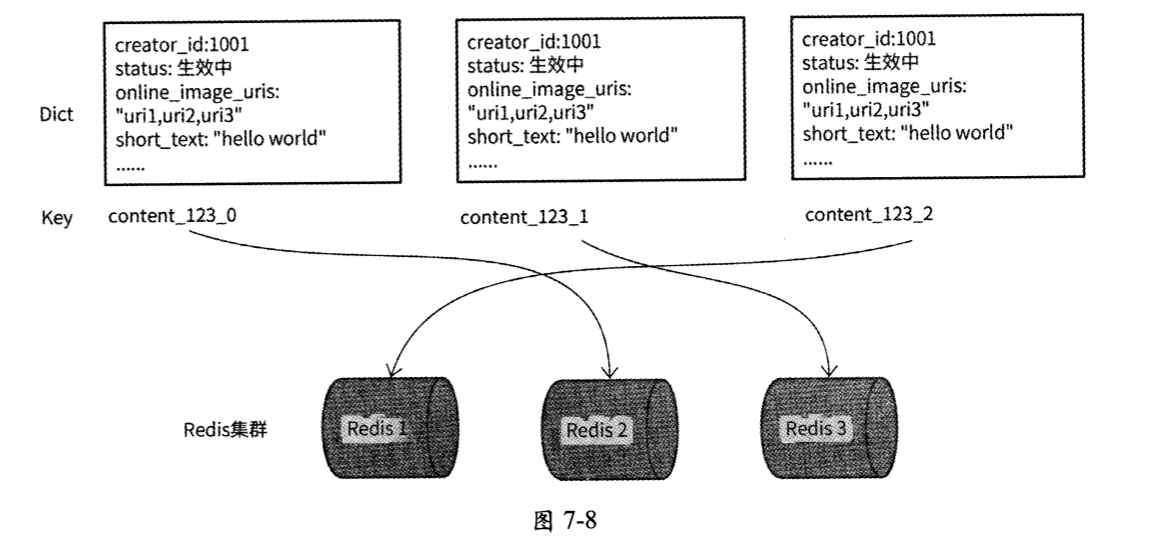
当读请求访问Redis时,Redis Proxy使用随机mod N来决定其访问哪个Redis Key。这样一来,每条热门内容的读请求在Redis集群中都可以被充分打散,使原本对单个Redis实例分片数百万级别的QPS下降到千级别。
既然为内容元信息建立了内容缓存,那么接下来就要考虑缓存的时效性问题。为了让内容元信息的变更可以更加实时地对线上用户生效,内容缓存也需要接收内容元信息变更的通知。想一想,这里是不是和内容分发渠道非常相似?实际上,我们确实可以将内容缓存理解为一种内容分发渠道,只不过这种内容分发渠道主要是用来为内容做数据缓存的。因此,需要将内容缓存作为event_content_meta_change消息队列的消息消费者,内容缓存在收到关于内容元信息变更的消息时可以主动更新缓存。
让内容缓存消费event_content_meta_change消息队列的消息,不仅可以达到缓存元信息主动更新的效果,而且可以作为一个更高级的功能:缓存预热。
在广义上,缓存预热是指系统上线时将相关的缓存数据预先直接加载到缓存系统中,这样就可以避免在用户请求数据时,先查询数据库,再构建数据缓存,用户直接查询的数据是事先预热的缓存数据。对于内容发布系统来说,在正式发布某内容前,如果业务架构师或产品策略师预测该内容对外发布后会有较高的访问热度,那么这条内容就可以被提前主动存储到缓存中,完成内容缓存预热。
假设产品策略师认为:拥有100万个粉丝的创作者每次发布的内容都可能成为热点,缓存预热系统每次从event_content_meta_change消息队列消费到属于“内容发布完成”的消息时,都先根据内容元信息中的creator_id获取创作者的粉丝量,如果粉丝量达到100万人,则将数据主动缓存到内容发布系统的各服务节点Local Cache中。
7.6.4 内容展示流程设计
7.6.2节和7.6.3节分别告诉我们:内容元信息通过Local Cache和Redis缓存;内容图片或视频通过CDN缓存。当向用户展示一条内容时,将优先读取这些数据缓存。
假设某创作者只发布了一条内容,其item_id为10001,某用户访问此创作者的个人主页,并点击了这条内容,这时客户端会向内容发布系统的服务端发起读取内容的请求,并携带item_id告知服务端希望读取这个内容ID的完整内容。
内容发布系统的任意一个服务节点在收到item_id=10001的内容读取请求后,会进入如下内容展示流程。
- 内容发布系统的服务节点根据item_id=10001拼接缓存项Key=content_10001,并尝试在Local Cache中查找内容元信息数据,如果查找到数据,则完成对内容元信息的获取,跳到第9步;如果未查找到,则进行下一步。
- 使用Key=content_10001查询Redis缓存,如果查询到数据,则完成对内容元信息的获取,跳到第9步;如果未查询到,则进行下一步。
- 使用item_id查询数据库的item_info表,主要读取creator_id、online_version、online_image_uris、online_video_id、online_text_uri、visibility和status字段。
- 将读取到的数据存储到Redis缓存中,并缓存到服务节点Local Cache中。
- 检查内容的状态:如果status字段的值为“正常展示”,则继续进行下一步;否则,直接返回空数据,表示内容不存在。
- 检查内容的可见性:如果visibility字段的值为“私密”,则检查user_id是否等于creator_id。如果不等于,则返回空数据,表示内容不存在;否则,表示内容可展示(创作者自见),继续进行下一步。
- 如果visibility字段的值为“好友可见”或“粉丝可见”,则从关系服务(见第10章)中读取用户与创作者的关系。如果不满足好友、粉丝的关系,则返回空数据;否则,继续进行下一步。
- 创建存储项Key=10001_{online_version),从分布式KV存储系统中读取内容文本。
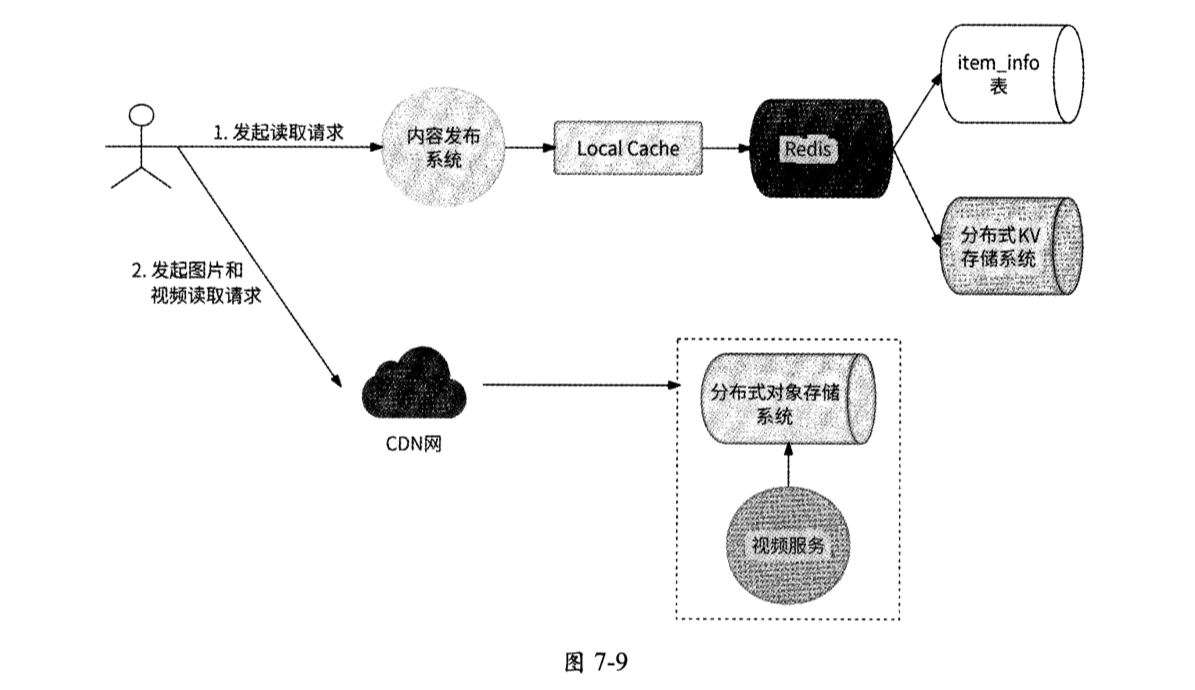
- 到了这一步,表示这条内容可对此用户展示,于是服务端将内容元信息、内容短文本数据及其他涉及内容主体的长文本URI online_text_uri、图片URI online_image_uris、视频URI online_video_id返回给客户端。
- 客户端展示内容文本,同时携带online_text_uri、online_image_uris、online_video_id(如果这3个字段非空)发起第2次请求访问服务端,用于获取长文本、图片、视频。
- CDN检查用户附近的CDN边缘节点,如果图片和视频在此节点中已缓存,则直接向用户返回内容;否则,继续进行下一步。
- CDN访问CDN中间节点,如果图片和视频在此节点中已缓存,则直接向用户返回内容,同时将图片和视频缓存到上一步中的边缘节点;否则,继续进行下一步。
- CDN访问源站服务器(也就是内容发布系统服务端)以获取图片和视频。
- 服务端分别根据online_image_uris和online_text_uri从对象存储系统中获取图片文件和长文本文件,同时根据online_video_id从视频服务中获取视频文件,并将它们回复给CDN。
- CDN将文本文件、图片文件、视频文件缓存到中间节点和边缘节点,并将它们返回给客户端,最终内容被完整地展示给用户。
从内容读取的流程可以得知,对内容的展示是分两阶段进行的:首先把内容元信息和内容短文本回传到客户端优先展示,包括内容创作者ID (creator_id)、内容创建时间(create_time)和内容短文本数据(short_text)),这样可以保证基本的内容读取体验(至少用户知道这条内容的主要话题是什么),并能让用户有耐心等待此内容中包含的图片和视频的展示;图片内容和视频内容则是客户端根据所收到的内容元信息数据向服务端进行第2次请求来获取和展示的,如图7-9所示。
这样做与浏览器展示网页有类似的考虑:如果浏览器一定要等到页面的所有元素都返回后再展示,那么会有较大的概率让用户盯着空白的页面等待较长的时间,用户可能会不耐烦,进而关闭页面;而如果浏览器选择将已经返回的元素先展示,用户就可以先读取已展示的内容,同时给剩余未展示的内容元素争取到一定的获取时间。
至于这条内容的其他周边展示元素,比如创作者的昵称与头像,可以从专门的用户服务中获取,而内容的点赞数、转发数、评论数、收藏数,可以从计数系统(见第8章)中获取。
总结
什么是CDN呢?
- CDN(Content Delivery Network,内容分发网络)就是把静态资源缓存到位于多个地理位置的边缘服务器上,当用户请求静态资源时,把用户的请求转发到附近的边缘服务器上实现就近访问。
- CDN技术一方面能很好地解决数据就近访问问题,另一方面能很好地缓存静态资源。
CDN技术的关键术语?
- 边缘节点:缓存用户请求内容的节点,是用户实际访问的服务器。
- 中间节点:CDN的内部节点,能缓存更多的内容。中间节点与边缘节点之间的网络是经过优化的,速度可观。如果用户在边缘节点访问不到数据,则会从中间节点访问或者经过中间节点回源。
- 源站服务器:真正的远端服务,中间节点可以从源站服务器获取数据,即“回源”。
- 第一千米:中间节点到源站服务器的连接。
- 最后一千米:用户到边缘节点的连接。
当某个静态资源被首次访问时,由于CDN边缘节点并未对它进行缓存 ,所以此时CDN中间节点会向源站服务器回源:获取静态资源,并将其缓存到边缘节点。在此之后,任何用户请求同样的静态资源时,都会在CDN边缘节点发现数据并响应,用户请求不再对源站服务器进行访问,这极大地缓解了源站服务器的带宽压力,且大大提高了静态资源在用户侧的加载速度。
内容展示流程?
- 内容发布系统的服务节点根据item_id=10001拼接缓存项Key=content_10001,并尝试在Local Cache中查找内容元信息数据,如果查找到数据,则完成对内容元信息的获取,跳到第9步;如果未查找到,则进行下一步。
- 使用Key=content_10001查询Redis缓存,如果查询到数据,则完成对内容元信息的获取,跳到第9步;如果未查询到,则进行下一步。
- 使用item_id查询数据库的item_info表,主要读取creator_id、online_version、online_image_uris、online_video_id、online_text_uri、visibility和status字段。
- 将读取到的数据存储到Redis缓存中,并缓存到服务节点Local Cache中。
- 检查内容的状态:如果status字段的值为“正常展示”,则继续进行下一步;否则,直接返回空数据,表示内容不存在。
- 检查内容的可见性:如果visibility字段的值为“私密”,则检查user_id是否等于creator_id。如果不等于,则返回空数据,表示内容不存在;否则,表示内容可展示(创作者自见),继续进行下一步。
- 如果visibility字段的值为“好友可见”或“粉丝可见”,则从关系服务(见第10章)中读取用户与创作者的关系。如果不满足好友、粉丝的关系,则返回空数据;否则,继续进行下一步。
- 创建存储项Key=10001_{online_version),从分布式KV存储系统中读取内容文本。
- 到了这一步,表示这条内容可对此用户展示,于是服务端将内容元信息、内容短文本数据及其他涉及内容主体的长文本URI online_text_uri、图片URI online_image_uris、视频URI online_video_id返回给客户端。
- 客户端展示内容文本,同时携带online_text_uri、online_image_uris、online_video_id(如果这3个字段非空)发起第2次请求访问服务端,用于获取长文本、图片、视频。
- CDN检查用户附近的CDN边缘节点,如果图片和视频在此节点中已缓存,则直接向用户返回内容;否则,继续进行下一步。
- CDN访问CDN中间节点,如果图片和视频在此节点中已缓存,则直接向用户返回内容,同时将图片和视频缓存到上一步中的边缘节点;否则,继续进行下一步。
- CDN访问源站服务器(也就是内容发布系统服务端)以获取图片和视频。
- 服务端分别根据online_image_uris和online_text_uri从对象存储系统中获取图片文件和长文本文件,同时根据online_video_id从视频服务中获取视频文件,并将它们回复给CDN。
- CDN将文本文件、图片文件、视频文件缓存到中间节点和边缘节点,并将它们返回给客户端,最终内容被完整地展示给用户。




