第12章评论服务——12.4 单级模式服务设计

第12章评论服务——12.4 单级模式服务设计
John Yaml12.4 评论服务设计的初步想法
如果某产品的评论功能不在意用户的互动性,或者某评论区中很难有成千上万条评论 ,那么可以基于单级模式来设计评论服务,比如博客的留言、商品的吐槽区等场景。
12.4.1 数据表的初步设计
在单级模式下,对内容本身的评论和对评论的回复处于同一层级,所以其数据表设计非常简单。假设数据表名为comment,表结构如表12-1所示。
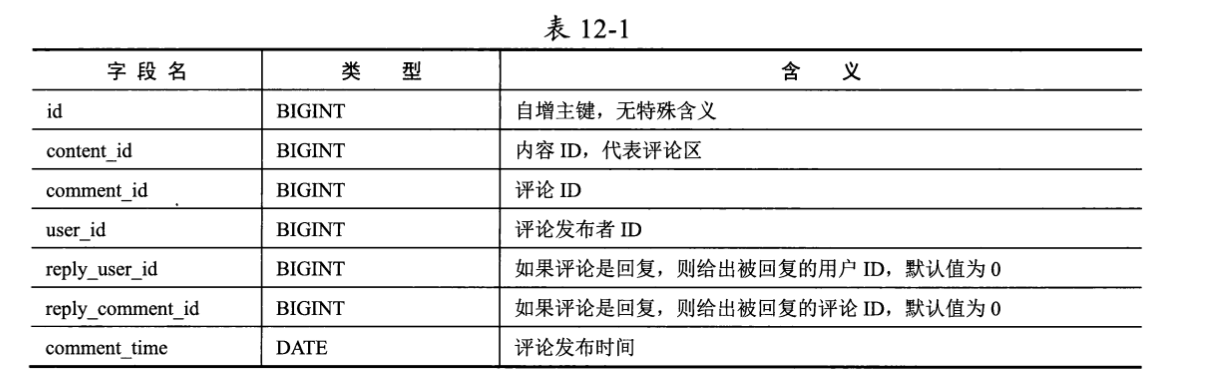
如果一条评论是对内容的评论,则其数据记录中的reply_user_id和reply_comment_id字段的值都为0;而如果一条评论是对其他评论的回复,则这两个字段都有明确的值。此外,评论ID作为评论的唯一标识,需要在创建评论时使用分布式唯一ID生成器生成并设置到commented字段。
12.4.2 读/写接口与索引
假设用户111在内容222的评论区中对内容本身发布了评论333,首先将评论文本以333为Key存储到分布式KV存储系统中,然后执行如下SQL语句保存评论元信息:
1 | INSERT INTO comment(content_idf comment_id, user_idz reply_user_id, comment_time) VALUES (222, 333, 111,当前时间戳) |
而如果用户111发布的评论555是在内容222的评论区中对用户333的评论444的回复,则实际执行的SQL语句如下:
1 | INSERT INTO comment(content_id, comment_id, user_idz reply_user_id, reply_comment_idz comment_time) VALUES (222, 555, 111r 333, 444,当前时间戳) |
在内容222的评论区中,评论列表是按照评论发布时间的顺序展示的(具体的顺序取决于产品设计,可能是由近及远,也可能是由远及近,此处假设为后者),且并不是一次性将全部评论都展示出来,而是分页展示的。当用户点击打开内容222的评论区时,在此评论区中应该展示第1页的N条评论,即评论发布时间最早的N条评论。执行的SQL语句如下:
1 | SELECT user_id, comment_id, content_id, reply_user_idr reply_comment_id FROM comment WHERE content__id = 222 ORDER BY comment_time LIMIT 0, N |
用户在阅读完这N条评论后,选择继续上滑获取更多的评论,即读取第2页的评论。 执行的SQL语句如下:
1 | SELECT user_id, comment_id, reply_user_id, reply_comment_id FROM comment WHERE content_id = 222 ORDER BY comment_time LIMIT N, N |
以此类推,当用户读取第M页的评论列表时,SQL语句使用LIMIT (M-1)*N,N来限制取数。
读取评论列表 ,适合使用content_id字段和comment_time字段作为联合索引idx_comment_list(content_id, comment_time)。这样一来,根据内容ID便可以快速定位到与此内容相关的全部评论,并且这些评论已经按照发布时间排序,可以充分提高SQL语句的执行效率。
当用户删除评论555时,最简单、直接的SQL语句是使用评论ID作为删除条件:
1 | DELETE FROM comment WHERE comment_id = 555 |
如果希望这条SQL语句能够高效执行,则需要再为comment_id字段创建一个索引,但是这个索引其实并不是必要的。因为用户在客户端删除某条评论前一定是先看到了这条评论,这就意味着客户端知道这条评论所属的内容ID和评论发布时间,所以依然可以使用content_id字段和comment_time字段来辅助删除此评论。在内容222的评论区中,删除发布于时间444的评论555O执行的SQL语句如下:
1 | DELETE FROM comment WHERE content_id = 222 AND comment_time = 444 AND comment_id = 555 |
这条SQL语句先命中idx_comment_list索引,然后在所定位到的数据记录中扫描comment_id字段。虽然这时数据库有扫描操作,但是好在针对同一内容在同一时刻收到的评论不会很多,所以扫描效率并不低。
用户111也可以查询自己发布的历史评论,这些评论一般是按照评论发布时间由近及远排序的,且同样是分页展示的。所以,筛选这些评论的SQL语句如下:
1 | SELECT content_idz user_idf comment_idz reply_user_id FROM comment WHERE user_id = 111 ORDER BY comment_time DESC LIMIT (M-l)*NZ N |
同理,这个场景适合使用user_id字段和comment_time字段作为联合索引idx_user_list(user_id, comment_time)。
综上所述,comment数据表需要两个联合索引,即idx_comment_list和idx_user_list。但是这两个索引的第一个字段不同,如果comment数据表需要分库分表,则无法选出合适的字段作为路由依据。然而,大部分面向用户的互联网产品都有海量的评论数据,即comment数据表必然要分库分表。如果选择content_id字段作为路由依据,那么查询某内容评论列表的SQL语句自然可以被准确地路由到一个特定的子数据表,保持SQL语句的查询效率;但是当查询某用户发布的评论列表时,由于此用户的评论数据可能散布在各个子数据表中,所以查询用户评论列表的SQL语句只能在每个子数据表中都进行查询和聚合汇总,查询效率大大降低。同理,如果选择user_id字段作为路由依据,那么查询用户评论列表的SQL语句仅会在一个子数据表中高效执行;但是当查询某内容的评论列表时,又得查询所有的子数据表。
12.4.3 数据库的最终设计
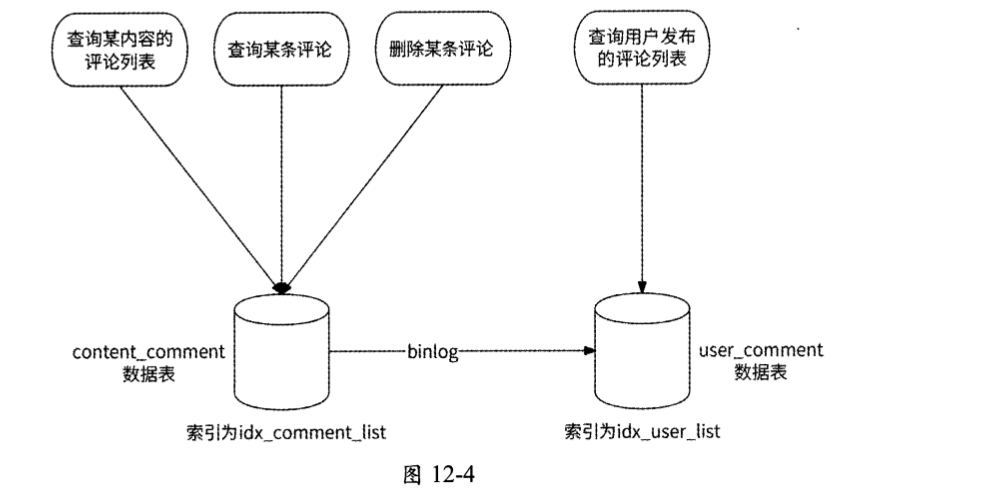
由于受限于分库分表的必要性,我们无法选出合适的字段作为路由依据。关于这个问题的解决思路,我们之前在第10章中也讨论过,那就是数据表冗余设计:创建两个结构与 comment数据表的结构完全一致的数据表content_comment和user_comment。
前者将idx_comment_list(content_id, comment_time)作为索引,将content_id作为分库分表的路由依据;
后者将idx_user_list(user_id, comment time)作为索引,将user_id作为分库分表的路由依据。
当查询某内容的评论列表时,评论服务会查询content_comment数据表;当查询某用户的评论列表时,评论服务则会查询user_comment数据表。
当用户发布评论、删除评论时,要同时更新content_comment和user_comment这两个数据表。为了保证这两个数据表的数据的一致性,我们可以选择content_comment作为主表,而 user_comment数据表通过伪从技术自动同步最新的评论数据,如图12-4所示。
12.4.4 高并发问题
评论功能是一个典型的可能读多写多的场景。如果流量明星发布了内容,或者某条内容具有极高的话题度,则会吸引大量的用户前来查阅评论和参与评论。所以,评论服务需要应对高并发写评论和高并发读评论两种情况。
我们先来看高并发写评论的情况。用户发布评论作为典型的写类型请求会直接操作数据库。虽然数据库可以通过分库分表提高并行处理写评论请求的能力,但是content_comment数据表将内容ID作为分库分表的依据。对于热门内容来说,有大量的写评论请求指向同一个内容ID,也就是说,这些写评论请求将被路由到同一个子数据表中,所以数据库依然会面临被击垮的风险。如图12-5所示,我们可以使用本书2.7节中介绍的异步写和写聚合解决方案来处理高并发的写评论请求。
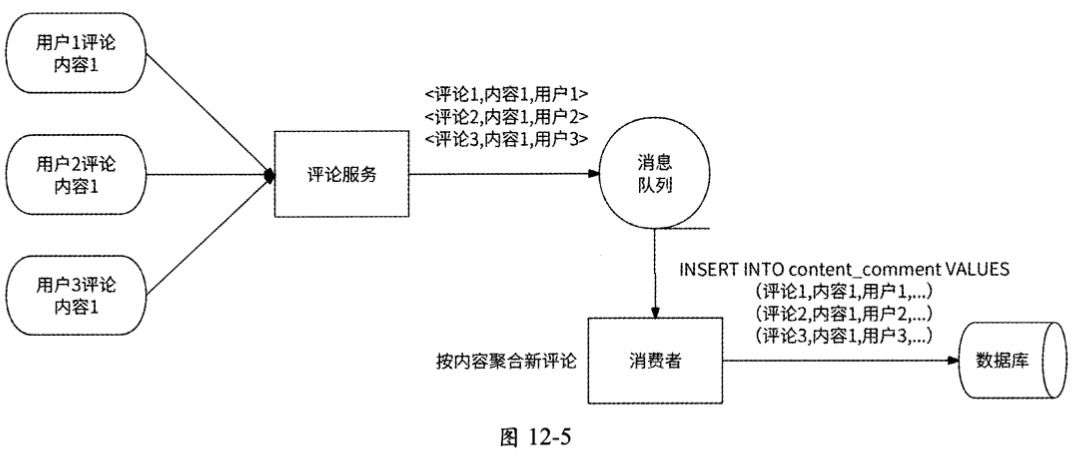
- 异步写:在评论服务和数据库之间使用主题为push_comment的消息队列建立通信通道,评论服务将所收到的写评论请求发送到push_comment消息队列中就成功响应用户;创建一个“发评消费者”来消费push_comment消息队列中的写评论请求,逐步将评论元信息数据插入数据库中。这样一来,高并发的写评论请求就被削峰为数据库可从容处理的平滑流量。
- 写聚合:发评消费者可以每隔10s就将所收到的写评论请求按照内容ID做一次聚合,将指向同一个内容ID的写评论请求聚合为一条SQL语句后插入数据库中。比如在某10s内,发评消费者收到了100个对内容111的写评论请求,这时就可以把对应的100条SQL语句改写为1条,然后交给数据库执行。这样一来,原本需要访问100次数据库的写评论请求被聚合为访问1次即可,提高了发评消费者的处理速度,缓解了数据库的访问压力。
我们再来看高并发读评论的情况。这里的读评论特指拉取热门内容的评论列表。对于绝大部分用户来说,其拉取的评论列表是位于评论区前几页的那些评论。所以,我们可以为评论列表中的前N条评论构建Redis缓存。
既然评论列表是按照评论发布时间排序的,那么我们照例使用Redis ZSET结构来描述缓存,其中Key为内容ID,Member为评论ID,Score为评论发布时间。这种将时间作为Score的ZSET结构,我们在用户关系服务、Timeline Feed服务的实现中已经反复介绍过,所以这里不再深入介绍读评论列表的Redis命令。
不过,需要注意的是,产品的评论功能有按照评论发布时间由近及远和由远及近排序的区别。如果评论列表是按照评论发布时间由远及近排序的,那么前N条评论数据是相对固定的,缓存极少需要更新;而如果评论列表是按照评论发布时间由近及远排序的,那么前N条评论数据会时刻发生动态变化,且内容越热门,前N条评论数据变化得越快。所以,更好的缓存形式是将Redis作为数据库的伪从,即每当将一条评论插入数据库中时,同时将此评论也插入Redis ZSET对象中。
考虑到高并发读取评论列表对Redis造成的请求压力,我们还可以进一步做本地缓存: 评论服务的每个服务实例都将从Redis ZSET对象中得到的评论列表缓存到本地内存中,并设置过期时间,如 5s。对于按照评论发布时间由近及远排序的评论列表来说,本地缓存会导致用户拉取到最多5s前的评论,而非此时最新的N条评论。但是好在用户并不是非常在意一定要看到此时的最新评论,只要评论数据相对比较新即可。所以,我们可以使用本地缓存进一步应对高并发读取评论列表的请求,只是不要将本地缓存的过期时间设置得太大就好。




