第11章Timeline Feed服务——11.3 拉模式与用户发件箱

第11章Timeline Feed服务——11.3 拉模式与用户发件箱
John Yaml11.3 拉模式与用户发件箱
一种较为符合我们直觉的实现Timeline Feed服务的方式是拉模式。每个内容发布者都有自己的“发件箱”,每当用户发布一个内容时,就把内容存放到发件箱中,由其他用户来拉取内容。
如图11-1所示,当用户获取Timeline Feed流时,系统会先拉取此用户的关注列表,然后遍历每个关注者的发件箱,取出他们发布的全部内容,最后根据发布时间倒序排列后展示给用户。
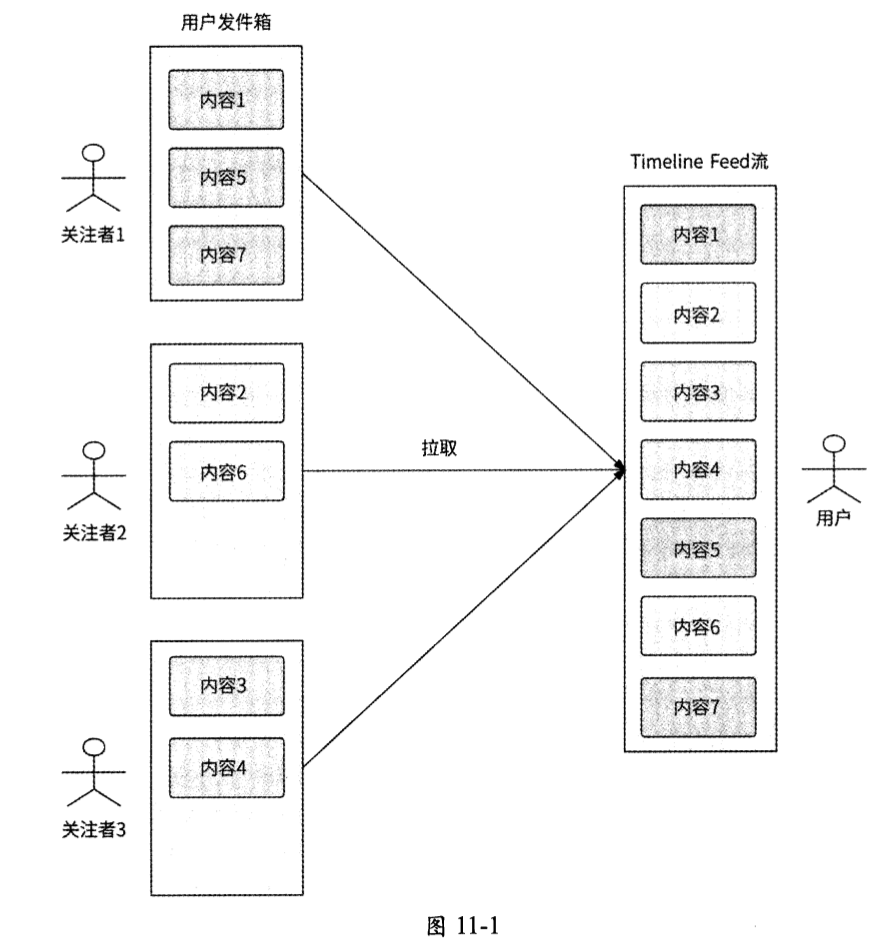
所谓的发件箱只是一种使描述更形象的代称,我们不需要专门设计发件箱,它实际上就是第7章讲的内容发布系统(服务)所负责存储的用户内容列表,所以拉模式就是从内容发布服务中拉取关注者的内容列表。可见,在拉模式下不需要为Timeline Feed服务单独设计存储系统,实现非常简单。因此,当一个互联网应用在初期阶段用户规模较小时,很适合使用这种方式来实现Timeline Feed流的功能。
不过 ,在拉模式下,用户每刷新一次Feed流 ,系统就需要读取N个用户的发件箱(这里的N是指用户关注的人数),这意味着一次用户请求会放大产生N倍的读请求,故而这种模式也被称为读扩散。如果用户量级较大,那么获取Feed流会是一个高并发场景,而且用户关注的人数也会较多。所以,这种读扩散会增加用户请求延迟,并可能击垮存储用户内容列表的数据库。




