第6章海量推送系统——6.1 分布式长连接服务的技术要素分析

第6章海量推送系统——6.1 分布式长连接服务的技术要素分析
John Yaml“推送”指的是把消息主动地实时推到客户端的行为。在互联网早期发展阶段,推送更多地属于即时通信(IM)领域范畴,但是随着移动互联网的普及,大量用户会维持很长时间的在线状态,于是对消息的实时触达能力有了广泛的需求。不仅仅在即时通信领域,几乎所有当代的互联网应用都对推送有大量的场景需求。例如:
社交互动类应用会实时通知与你相关的新互动(关注/私聊/回复/点赞 )、你关注的人发布了新内容、在直播间内谁给主播赠送了礼物;
电商类应用会告诉你所收藏的商品刚刚降价了、你的订单已完成退款、你的物流已到达目的地、你观看的带货直播间有新商品“上车”;
新闻类应用会推送你感兴趣的新闻和实时热点新闻;
更为普遍的是,大量应用都有系统版本升级主动提醒、重要全服公告能力等。
如上种种,都是非常典型的推送场景。在如今这样一个大数据个性化推荐的时代,很多应用出于保持用户活跃度的目的,甚至会投你所好,推送你可能感兴趣的消息,比如图6-1所展示的那样。

消息推送的应用场景如此广泛,我们很有必要来讨论一下推送系统这个议题。我们希望设计一个通用的推送系统,支持各种业务方主动向在线用户发出各种各样的事件消息,而且它能服务于百万级、千万级甚至上亿级的在线用户,并在保证消息实时到达的同时,有较高的性能,具备高可用性。
本章的学习路径与内容组织结构如下。
- 6.1介绍推送系统的核心,即分布式长连接服务的技术要素,包括WebSocket协议、长连接服务器、分布式推送服务器和路由算法。
- 6.2节详细介绍海量推送系统的设计。首先给出整体架构,然后分别介绍长连接的建立过程、消息格式设计、消息推送接口设计和各种消息类型的推送细节,最后介绍pusher的平滑升级与扩容。
本章关键词:WebSocket、长连接、分布式推送、单点消息推送、多点消息推送、全局消息推送、平滑升级。
6.1 分布式长连接服务的技术要素分析
一般来说,客户端与服务器的交互都是客户端主动发起请求,服务器进行应答的方式。而消息推送场景则不一样,服务器需要主动向客户端发起请求,那么推送系统必然需要客户端与服务器保持长连接,即推送系统需要构建长连接服务。长连接服务是推送系统设计的核心,我们的所有讨论都会围绕它展开。
6.1.1 WebSocket协议简介
客户端一般通过HTTP与远程服务器进行网络通信。HTTP采用了请求/响应模型,它是一种无状态、无连接、单向的应用层协议。网络请求只能由客户端主动发起,服务器被动接收请求进行应答,原生HTTP无法实现服务器主动向客户端发送数据。
采用请求/响应模型注定:如果服务器有信息变更想告知客户端,则交互会变得非常麻烦。比如客户端每隔几秒就要对服务器进行一次请求轮询,检查是否有新消息待接收。这种方式看起来简单粗暴,但是在使用轮询时需要格外谨慎,因为轮询本身效率低下,实时性不佳,不仅浪费了大量网络带宽,而且会让服务器增加无谓的访问压力。
在这种困境下,HTML 5定义了一种全新的通信协议:WebSocket,并于2011年被IETF定义为标准RFC 6455。WebSocket是一种基于TCP的全双工通信协议,允许在客户端与服务器之间建立全双工通信连接,这样客户端和服务器都可以主动将数据推送到另一端。如图6-2所示,WebSocket仅需要建立一次连接就能一直保持连接状态,比轮询的效率高。
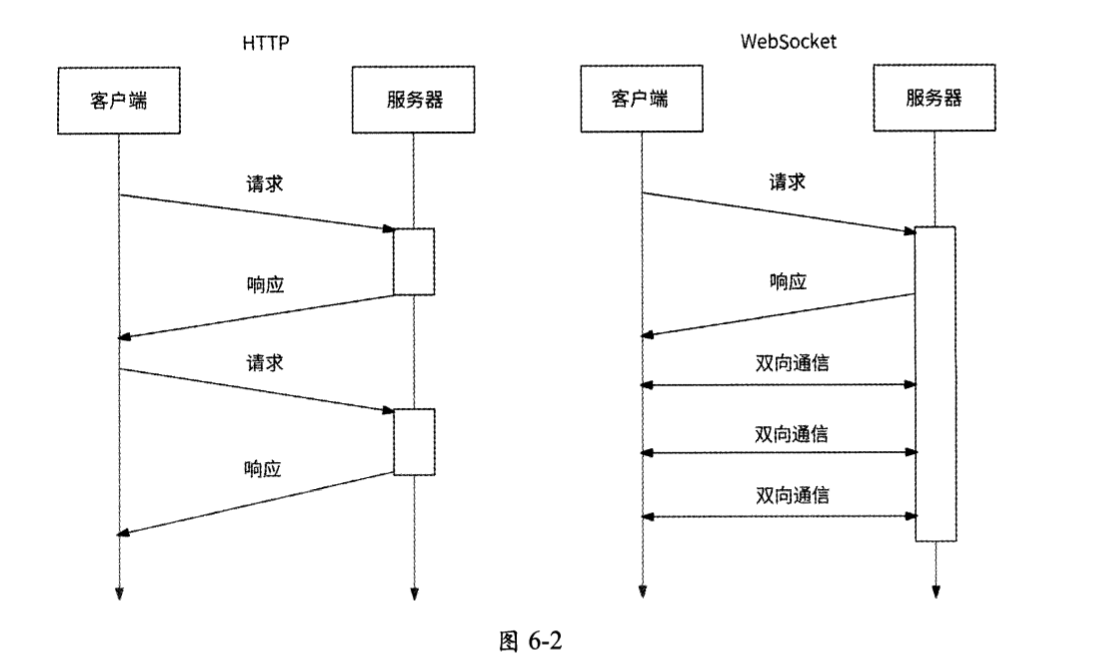
由于WebSocket协议很适合消息推送场景,所以我们可以在客户端开发一个基于WebSocket协议的长连接通信SDK,客户端通过调用这个SDK来创建专门用于接收服务器推送消息的通道。对于各种推送类型的业务场景,客户端都从这个专用通道接收推送的消息。
6.1.2 长连接服务器
客户端通过WebSocket协议与服务器建立长连接,从服务器的视角来说,其本身应该是一台可支持高并发、对长连接进行维护和管理的服务器。下面简单回顾常见的高并发服务器模型。
- accept+fork多进程模型:当一个客户端连接到来时,分配一个子进程负责处理这个连接的读/写请求,即一个连接对应一个进程。这种模型虽然简单、直观,但是缺点明显,大量连接会生成等量的进程,服务器资源消耗较大。
- accept+thread多线程模型:它是对多进程模型的优化。当一个客户端连接到来时,分配一个线程负责处理这个连接的读/写请求,即一个连接对应一个线程。虽然线程相比进程节约了一些资源,但是治标不治本,当连接量太大时,依然会有较大的服务器资源消耗。早期Tomcat曾使用过这种设计。
- 单线程多路复用模型:在单线程中使用epoll对所有的连接进行监听管理,当没有事件到来时,线程被epoll_wait阻塞;而当有连接读/写事件到来时,线程从阻塞中返回并回调handler。这种方式也被称为Reactor模式,其很适合有大量连接的I/O密集型场景。不过,由于只能使用单核CPU,如果handler耗时过长,则会影响服务器整体响应时间。此模型的典型代表是Redis。
- 多进程多路复用模型:它是对单进程多路复用模型的优化。其充分利用了多核能力,且对handler的耗时有一定的容忍性。此模型的典型代表是Nginx。
- 多线程多路复用模型:与多进程多路复用模型类似,只不过它用多线程代替了多进程。此模型的典型代表是缓存服务器Memcached。
推送服务器的主要职责是与客户端建立长连接,并将上游消息转发到客户端,是一台相对纯粹的消息转发服务器,属于典型的I/O密集型应用。所以,根据对上述常见的高并发服务器模型的简单分析,只要是多路复用类型的模型,就是比较合适的选型。使用单线程多路复用模型,无须考虑并发安全,开发较为简单,但是仅局限于单核CPU;而使用多进程/多线程多路复用模型,可以充分利用多核CPU,不过出于并发安全的考虑,有一定的开发成本。由于推送服务器的逻辑较为轻量级,这些服务器模型均可以较为优秀地支持数十万个长连接并发访问。
我们暂且称这台负责与客户端建立连接以及推送消息的单体长连接服务器为pusher。
6.1.3 分布式推送服务器
一台pusher服务器虽然可以承载数十万个客户端设备的长连接,但是由于同时在线的用户设备远不止这个数量级,可能有数百万个、数千万个乃至上亿个设备,所以一个pusher节点是无法满足要求的。另外,单体服务器天然不具备高可用性和可扩展性,所以势必需要将若干pusher节点组成一个分布式pusher集群对外提供服务。
将若干pusher节点组成一个分布式pusher集群,我们需要考虑如下主要问题。
- 问题1:集群中有哪些pusher节点,以及每个pusher节点的地址信息、每个pusher节点的活跃状态等,在哪里维护?
- 问题2:当一个客户端设备连接到来时,我们选择哪一个pusher节点与其建立连接?
- 问题3:当一条消息需要被推送给某个或某些设备时,我们如何找到这个或这些设备对应的长连接,它们在哪个或哪些pusher节点上?
- 问题4:当pusher集群需要扩容时,对存留的长连接如何处理?是否需要或者说是否能做到连接迁移?
解决思路:
- 问题1很好回答,无非就是服务发现问题。我们可以使用ZooKeeper或etcd等分布式一致性中间件来维护pusher节点列表:每当集群中新增pusher节点时,就向ZooKeeper进行地址注册,同时针对pusher节点的日常运行也向ZooKeeper上报心跳信息。如此一来,就可以从ZooKeeper中获取在工作的pusher节点地址列表了。
- 问题2和问题3的本质其实是一样的,即我们需要提供一套什么样的设备连接与pusher节点的关联规则。利用这套关联规则,我们可以为设备连接选择具体的pusher节点,并可以知道哪些设备与哪些pusher节点连接。设备连接与pusher节点的关联规则,其实就是路由问题,更通俗的叫法是负载均衡。这个问题会在下一节中具体介绍。
- 对于问题4,不同于分布式存储系统扩容时的数据迁移,推送系统的长连接本身不是实体数据,无法做到跨机器迁移,只能断开与旧服务器的连接,再连接新服务器。为了不让用户感知到重连,客户端应充分权衡影响面后再做决定。
6.1.4 路由算法
推送系统有两处需要利用路由算法。
- 用户设备发起连接请求,pusher集群需要通过路由算法,选择一个合适的pusher节点与这个用户设备建立连接。
- 当向某个device id进行消息推送时,pusher集群需要通过路由算法,找到这个device id与哪个pusher节点建立了长连接。
对路由算法的选型,要尽量保证各个用户设备的连接可以被均匀地分配到集群中的每个pusher节点上,不能出现有的pusher节点连接过多且趋于饱和,而有的pusher节点长期空闲的情况。此外,由于不同用户设备的长连接被分配到不同的pusher节点上,当我们想向指定的设备发送推送类型的消息时,必然需要知道这个用户设备在哪个pusher节点上,这样才能把待推送的消息转发到有此设备连接的pusher节点上,然后由此pusher节点进行真正的下行消息的下发。所以,我们需要时刻知道每个用户设备的device_id与pusher节点地址的关联关系。
常见的路由算法如Random(随机调度)算法、Round-Robin(轮询调度)算法、一致性Hash算法,都可以较好地保证连接均匀地分布在pusher集群的每个节点上。不过,不同的算法在推送消息时获取device id与pusher节点地址的关联关系的方式有较大差异。
- 对于Random算法、Round-Robin算法:由于device_id与pusher节点地址的关联关系没有数学规律性(即不能通过一个固定的公式得到),我们无法直接获取到某个device_id对应于哪个pusher节点的信息,所以不得不在设备与pusher节点建立连接时而用一种外部存储系统来保存两者的关联关系。这里笔者推荐使用Redis分布式存储,一方面,Redis有足够高的读/写性能,可以应对海量消息推送时的查询路由请求;另一方面,这种关联数据并非一定要保证在极端条件下不丢失,使用内存型存储是没有太大问题的。
- 对于一致性Hash算法或其他Hash算法:由于device id与pusher节点地址的关联关系有明确的数学公式指导,也就是可以直接算出,我们无须使用外部存储系统来保存两者的关联关系。
既然一致性Hash算法作为路由算法可以免去额外存储device_id与pusher节点地址的关联关系,那么它是否就是最合适的算法呢?其实未必,我们还没有考虑pusher集群中节点变化的情况。
如果目前pusher集群的压力较大而需要进行服务扩容,那么当向集群中新增一个pusher节点p1时,在一致性哈希环上与其相邻的pusher节点p0上大约一半的device id都要指向p1节点,这些device_id与p0节点的长连接必须断开,再重连到p1节点。可以看出,一致性Hash算法在面对pusher集群的扩容时有较多额外的工作要做。
而Round-Robin算法对集群的扩容比较友好,当向集群中新增一个pusher节点p1时,全部存留的长连接都不需要进行迁移,所有的device_id与pusher节点地址的关联关系依然是有效的。
选择哪种路由算法,其实没有绝对的好坏之分,需要工程师来分析各种算法的优劣进行权衡。
在完成路由算法的选型后,下一步就是由谁来负责计算路由和转发请求。
对于设备的建立连接请求,我们可以让它们统一指向一个代理层服务器,比如Nginx,由Nginx负责通过路由算法选择一个pusher节点与设备建立连接。
对于后端消息的推送请求,我们可以提炼出一个下行消息到pusher集群的代理网关,由它负责根据消息的目标设备进行路由计算,把消息转发到对应的pusher节点上。
总结
HTTP协议的交互过程?
- 客户端一般通过HTTP与远程服务器进行网络通信。
- HTTP采用了请求/响应模型,它是一种无状态、无连接、单向的应用层协议。
- 网络请求只能由客户端主动发起,服务器被动接收请求进行应答,原生HTTP无法实现服务器主动向客户端发送数据。
请求响应模型的缺点?
- 如果服务器有信息变更想告知客户端,则交互会变得非常麻烦。
- 比如客户端每隔几秒就要对服务器进行一次请求轮询,检查是否有新消息待接收。
- 这种方式看起来简单粗暴,但是在使用轮询时需要格外谨慎,因为轮询本身效率低下,实时性不佳,不仅浪费了大量网络带宽,而且会让服务器增加无谓的访问压力。
介绍WebSocket协议?
- WebSocket是一种基于TCP的全双工通信协议,允许在客户端与服务器之间建立全双工通信连接,这样客户端和服务器都可以主动将数据推送到另一端。
- WebSocket仅需要建立一次连接就能一直保持连接状态,比轮询的效率高。
常见的高并发服务器模型?
- accept+fork多进程模型:当一个客户端连接到来时,分配一个子进程负责处理这个连接的读/写请求,即一个连接对应一个进程。这种模型虽然简单、直观,但是缺点明显,大量连接会生成等量的进程,服务器资源消耗较大。
- accept+thread多线程模型:它是对多进程模型的优化。当一个客户端连接到来时,分配一个线程负责处理这个连接的读/写请求,即一个连接对应一个线程。虽然线程相比进程节约了一些资源,但是治标不治本,当连接量太大时,依然会有较大的服务器资源消耗。早期Tomcat曾使用过这种设计。
- 单线程多路复用模型:在单线程中使用epoll对所有的连接进行监听管理,当没有事件到来时,线程被epoll_wait阻塞;而当有连接读/写事件到来时,线程从阻塞中返回并回调handler。这种方式也被称为Reactor模式,其很适合有大量连接的I/O密集型场景。不过,由于只能使用单核CPU,如果handler耗时过长,则会影响服务器整体响应时间。此模型的典型代表是Redis。
- 多进程多路复用模型:它是对单进程多路复用模型的优化。其充分利用了多核能力,且对handler的耗时有一定的容忍性。此模型的典型代表是Nginx。
- 多线程多路复用模型:与多进程多路复用模型类似,只不过它用多线程代替了多进程。此模型的典型代表是缓存服务器Memcached。
推送服务器的主要职责?
- 推送服务器的主要职责是与客户端建立长连接,并将上游消息转发到客户端,是一台相对纯粹的消息转发服务器,属于典型的I/O密集型应用。
推送系统有两处需要利用路由算法?
- 用户设备发起连接请求,pusher集群需要通过路由算法,选择一个合适的pusher节点与这个用户设备建立连接。
- 当向某个device id进行消息推送时,pusher集群需要通过路由算法,找到这个device id与哪个pusher节点建立了长连接。
常见的路由算法?
- Random(随机调度)算法
- Round-Robin(轮询调度)算法
- 一致性Hash算法
不过,不同的算法在推送消息时获取device id与pusher节点地址的关联关系的方式有较大差异?
- 对于Random算法、Round-Robin算法:由于device_id与pusher节点地址的关联关系没有数学规律性(即不能通过一个固定的公式得到),我们无法直接获取到某个device_id对应于哪个pusher节点的信息,所以不得不在设备与pusher节点建立连接时而用一种外部存储系统来保存两者的关联关系。这里笔者推荐使用Redis分布式存储,一方面,Redis有足够高的读/写性能,可以应对海量消息推送时的查询路由请求;另一方面,这种关联数据并非一定要保证在极端条件下不丢失,使用内存型存储是没有太大问题的。
- 对于一致性Hash算法或其他Hash算法:由于device id与pusher节点地址的关联关系有明确的数学公式指导,也就是可以直接算出,我们无须使用外部存储系统来保存两者的关联关系。
在完成路由算法的选型后,下一步就是由谁来负责计算路由和转发请求?
对于设备的建立连接请求,我们可以让它们统一指向一个代理层服务器,比如Nginx,由Nginx负责通过路由算法选择一个pusher节点与设备建立连接。
对于后端消息的推送请求,我们可以提炼出一个下行消息到pusher集群的代理网关,由它负责根据消息的目标设备进行路由计算,把消息转发到对应的pusher节点上。




