第3章通用的服务可用性治理手段——3.5 自适应限流

第3章通用的服务可用性治理手段——3.5 自适应限流
John Yaml无论是时间窗口、漏桶算法、令牌桶算法,还是全局限流方案,限流阈值都是人为设置的,这就意味着这些限流策略的实际效果很被动,依赖限流阈值的设置是否足够合理。
为了设置合理的限流阈值,在一个服务正式上线前,我们一般会事先对它进行一段时间的全链路压测,再根据压测期间服务节点的各项性能指标,选择服务负载接近临界值前的QPS作为限流阈值。
基于服务的压测数据得出的限流阈值看似是合理的,但是服务的性能会随着服务的不断迭代而变化,例如:
- 某服务的单个实例可承受的最大QPS为100,研发工程师不满意此服务的性能表现,于是对服务进行了系统性重构,性能得到大幅提升,单个实例可承受的最大QPS变为300。
- 某服务原本是一个轻量级服务,单个实例可承受的最大QPS为500。但是在某次产品需求变更中,为此服务增加了对多个下游服务的调用,于是服务性能下降到单个实例可承受的最大QPS为100。
可以看到,服务的每次迭代都有可能影响服务的性能,性能可能提升,也可能劣化。
- 如果服务的性能提升了,则原限流阈值会限制服务发挥性能,浪费服务资源;
- 如果服务的性能劣化了,则原限流阈值无法有效保护服务不被打垮。
理论上,服务每涉及变更时都应该更新其限流阈值,这也就意味着服务每次迭代后都需要执行全链路压测。但是,实际上这么做需要较多的准备工作和较高的人力成本,而且难以保证可持续执行。
最了解自己的人还是自己。实际上,服务实例可以根据自身的负载情况自动判断是否可以继续处理请求,我们不再基于人工观测和个人经验设置限流阈值,而是把限流这件事交给服务自己来做,这就是自适应限流。无论服务怎样迭代,无论网络状况和下游服务状况怎样,自适应限流都可以使服务根据自身当下的负载情况对新来的请求做合理取舍。
3.5.1 服务与等待队列
在正式介绍自适应限流算法前,我们需要先了解一下等待队列的概念。
每个服务都有一定的并发度(concurrency),对于一定范围内的并发请求,服务能立即处理这些请求,而当到达服务的请求量级大于服务并发度时,请求就会排队等待。
Netflix技术团队形象地用一个等待队列(queue)来表述服务与请求之间的关系,无法立即被处理的请求在这个等待队列中排队,如图3-22所示。
如图3-23所示,如果不对等待队列加以限制,那么随着越来越多的请求在等待队列中排队,请求延迟逐渐增加,直到所有请求都超时未响应,服务最终也会因为内存耗尽而崩溃。当服务有逐渐崩溃的趋向时,我们认为服务“过载”。
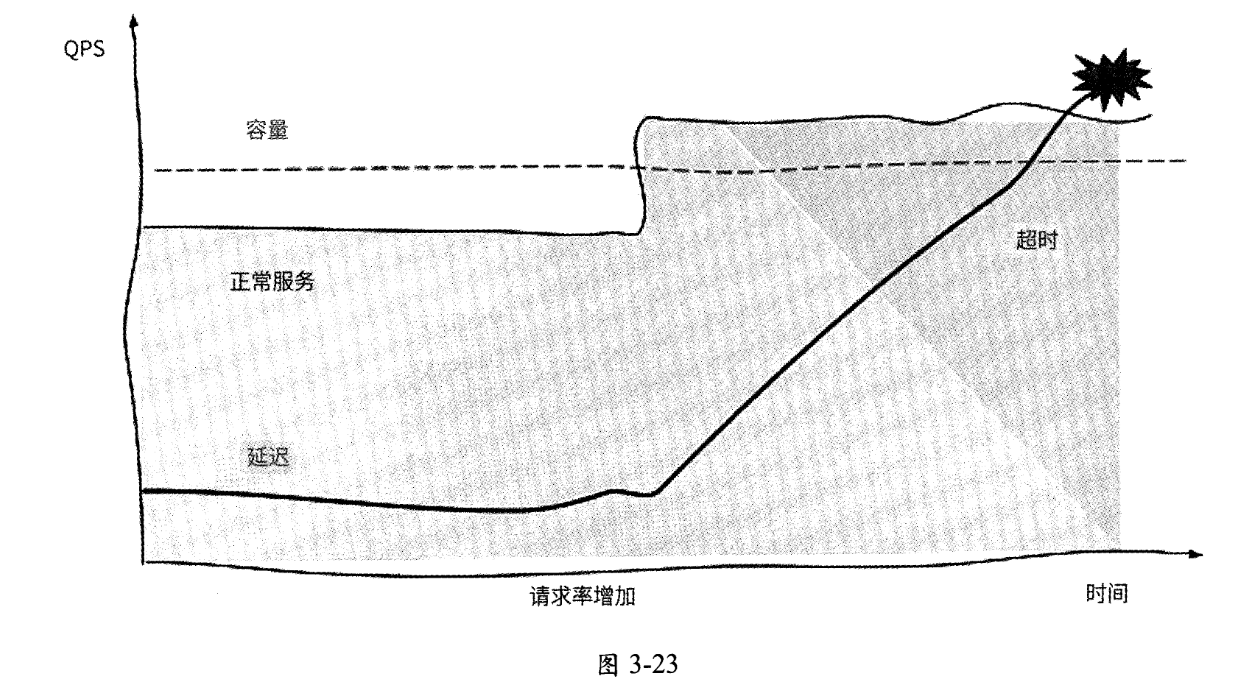
限流不是新鲜事,但是如何在并发请求量和请求延迟不断动态变化的服务中找到最合适的限流阈值,防止服务过载却是一件难事。最合适的限流阈值指的是在请求延迟开始升高前服务允许通过的最大请求并发数,而自适应限流就是为了自动识别这个最合适的限流阈值,且应该具有如下特点。
- 研发工程师无须手动设置限流阈值,无须引入人为经验和推断等不稳定因素。
- 能适应服务性能变化,或服务所在服务器的性能与资源变化。
- 限流决策易于计算和执行,能精准防止服务过载。
相信有些读者曾经接触过“过载保护”这个概念,实际上,服务防止自身过载的场景与自适应限流是一回事:自适应限流是防止服务过载的方法。很多公司设计了各种自适应限流方案,其原理也各不相同,接下来我们介绍3种较有影响力的自适应限流方案。
3.5.2 基于请求排队时间
Dagor是微信团队研发的微服务过载控制系统,它提供了服务过载检测、准入控制等能力。准入控制指的是服务处于过载状态时,服务进一步细分哪些请求可以通过。Dagor的设计思路是优先保证业务优先级或用户优先级更高的请求被允许通过,而低业务优先级、低用户优先级的请求被丢弃。准入控制属于自适应限流的上层高级应用,我们需要重点关注的是Dagor如何检测服务过载。
Dagor使用等待队列中请求的平均等待时间(即排队时间)来判断服务是否过载。一个请求的排队时间的计算公式如下:
排队时间 = 请求开始被处理的时间 - 请求到达服务的时间
微信团队设置的平均等待时间的阈值为20ms。如果请求在被服务处理前平均等待时间超过20ms,则认为服务已经过载。据说这个阈值配置已经在微信业务系统中应用了很多年,微信业务服务的稳定性已经验证了这种过载检测方式和阈值配置的有效性。
为什么Dagor不使用CPU使用率作为服务过载的检测标准?这是因为CPU使用率过高固然可以反映出一个服务是否处于高负载的状态,然而,它只是一个必要不充分条件,只要服务可以及时处理请求,即使CPU使用率再高,我们也不应该认为服务过载,此时不宜限流。
3.5.3 基于延迟比率
Netflix技术团队实现了自适应限流组件concurrency-limits,它的算法借鉴了TCP拥塞控制的部分思想,通过检查请求最小延迟和采样延迟之间的比值动态调整限流窗口。
此算法有两个核心公式,其中第一个核心公式用于计算请求延迟比率,并将其作为延迟变化的梯度:
gradient = RTT_noload ÷ RTT_actual
这里有两个变量:
RTT_noload变量表示服务无负载时的最佳请求延迟,concurrency-limits组件用最近一 段时间内最小的请求延迟作为它的值;RTT_actual变量表示当前采样请求的实际延迟。
这两个变量之间的比值被称为梯度(gradient):
- gradient的值为1,表示没有请求在等待队列中排队,可以适当放宽限流窗口;
- gradient的值小于1,表示可能已有请求排队,为了防止过多的请求排队,需要逐渐收紧限流窗口。
第二个核心公式就是用gradient控制限流窗口的具体方式:
new_limit = current_limit x gradient + queue_size
这里有两个变量:
- current_limit变量表示当前限流窗口的大小,通过其与gradient相乘来上下调整限流窗口,current limit在服务初始状态时以较小的初始值开始运行;
- queue_size变量表示允许一定程度的排队,此变量的值一般是当前限流窗口大小current limit的平方根。
在没有请求排队时,这个公式可以产生限流窗口很小则增长很快、限流窗口过大则增长缓慢的效果,与TCP拥塞控制很像。通过反复调整限流窗口,算法逐渐趋于稳定,不仅能让请求延迟保持在较低的状态,而且允许一定程度的突发流量。
这种自适应限流算法在concurrency-limits组件中的实现被称为gradient算法。实际上,我们查看concurrency-limits组件的源码就能发现,Netflix技术团队还提供了其他自适应限流算法,如gradient2算法、vegas算法等。从名称上看,就可以知道gradient2算法是对gradient算法的改进,而vegas算法则参考了TCP vegas拥塞控制算法。无论何种算法,其原理归根结底都是根据等待队列的长度或请求延迟情况不断地对限流窗口进行上下调整, 最终收敛到一个合理的范围内,如图3-24所示。
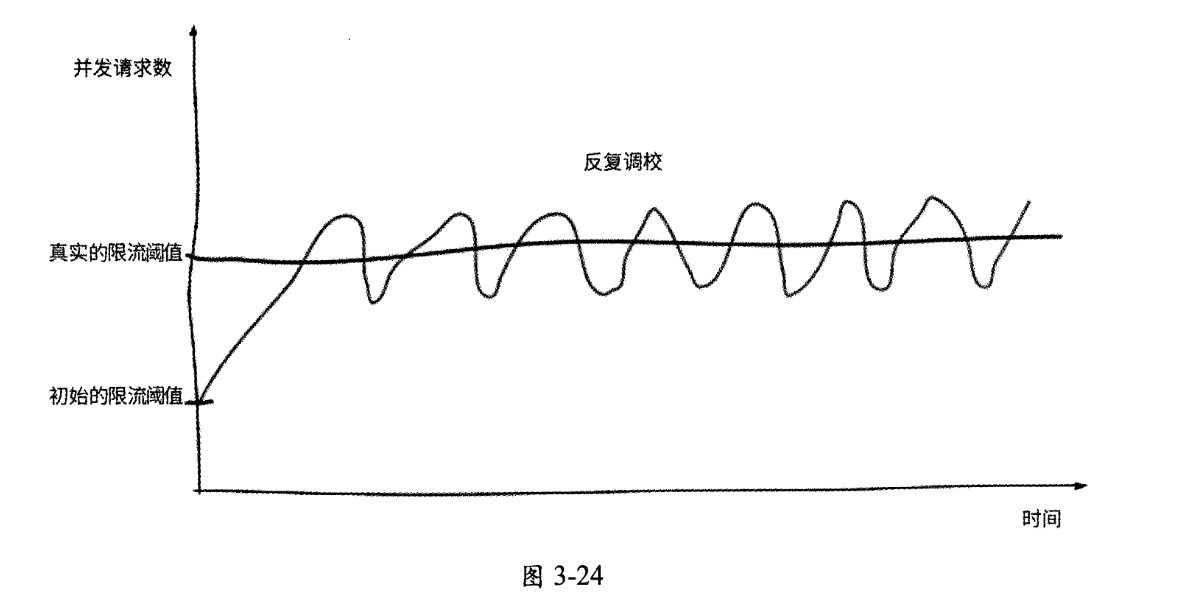
在采用了自适应限流算法后,Netflix技术团队在官方技术博客中也开心地表示,再也不需要“保姆式”地人工干预服务限流阈值的决策了,服务的稳定性和可用性也因此得到了进一步提升。
3.5.4 其他方案
Kratos是由bilibili公司开源的一套轻量级Go语言微服务框架,其中包含大量微服务相关工具。值得称赞的是,Kratos实现了较多保障服务可用性的中间件,其中就包括使用了BBR limiter算法的自适应限流器。
简单来说,BBR limiter算法使用CPU负载做启发阈值。
- 如果CPU负载超过80%,则获取最近5s的最大吞吐量;
- 如果此时服务中正在处理的请求数大于最大吞吐量,则丢弃新请求。
我们先来看BBR limiter算法的BBR结构体:
1 | type BBR struct { |
其中几个主要字段的含义如下。
- cpu:用于从系统所在的服务器中获取当前CPU使用率。
- passStat:系统处理过的请求数采样数据,使用滑动窗口统计。
- rtStat:请求响应时间的采样数据,同样使用滑动窗口统计。
- inFlight:当前系统中正在处理的请求数。
- bucketPerSecond:滑动窗口中一个槽的时间长度。
- prevDropTime:上次触发请求限流的时间。
BBR limiter算法使用如下函数判断请求是否可以通过:
1 | func (l *BBR) Allow(ctx context.Context) (func(), error { |
shouldDrop是最核心的函数,用于判断请求是否可以被执行:
1 | func (l *BBR) shouldDrop() bool { |
maxInFlight函数用于获取服务最近5s的最大吞吐量。在阅读源码前,我们先思考一下,一个服务的最大吞吐量应该如何计算?这里举一个例子:某大学每年招生2000人,每个学生需要4年时间才能毕业离校,那么此大学的总人数是多少?答案是8000人(2000x4)。因为每个学生在学校停留4年,而每年有2000个学生入校和离校。同理,假设入表示一个物体进入某系统的速率,不是此物体在系统中的平均停留时间,那么系统中平均持有的物体数量L的计算公式如下:
$$L = \lambda \times W$$
这就是利特尔法则。结合上例,$\lambda$是大学每年招生的人数,不是每个学生在学校停留的时间,W是大学里学生的总人数。
服务的吞吐量也可以利用利特尔法则来计算,将QPS作为$\lambda$,将请求响应时间RT (response time)作为W,则QPS x RT就可以代表服务的吞吐量。通过BBR limiter算法计算服务最近最大吞吐量的源码如下:
1 | func (l *BBR) maxFlight() int64 { |
这里l.maxPASS() * l.bucketPerSecond / 1000表示用最近最大请求数来计算每毫秒处理的请求数,l.minRT()表示最近请求的最小响应时间,基于利特尔法则,两者相乘的结果可以认为是服务最大吞吐量。源码最后的+0.5表示将浮点数向上取整。
请求是否被丢弃的完整逻辑(shouldDrop函数)如图3-25所示。

判断当前CPU使用率是否已经达到阈值(默认为80%)。
如果达到阈值,则进一步判断服务当前正在处理的请求数是否大于服务最近最大吞吐量。
a. 如果是,则请求应该被丢弃。
b. 否则,请求可以被处理。
如果没有达到阈值,则进一步判断上次请求被丢失的时间距现在是否超过1s。
a. 如果超过1s,则请求可以被执行。
b. 否则,继续判断服务当前正在处理的请求数是否大于服务最近最大吞吐量;如果是,则请求被丢弃。
总结
什么是自适应限流?
服务实例可以根据自身的负载情况自动判断是否可以继续处理请求,我们不再基于人工观测和个人经验设置限流阈值,而是把限流这件事交给服务自己来做,这就是自适应限流。
无论服务怎样迭代,无论网络状况和下游服务状况怎样,自适应限流都可以使服务根据自身当下的负载情况对新来的请求做合理取舍。
什么是等待队列?
- 每个服务都有一定的并发度(concurrency),对于一定范围内的并发请求,服务能立即处理这些请求,而当到达服务的请求量级大于服务并发度时,请求就会排队等待。这个队列就是等待队列。
自适应限流具备哪些特点?
- 研发工程师无须手动设置限流阈值,无须引入人为经验和推断等不稳定因素。
- 能适应服务性能变化,或服务所在服务器的性能与资源变化。
- 限流决策易于计算和执行,能精准防止服务过载。
自适应限流方案有哪些?
- 基于请求排队时间
- 基于延迟比率
怎么计算服务的吞吐量?
- QPS * RT




