第3章通用的服务可用性治理手段——3.6 降级策略

第3章通用的服务可用性治理手段——3.6 降级策略
John Yaml在3.4节中,我们曾列举著名景区在节假日期间限制游客数量的例子来表述限流,而景区在节假日期间将不重要的、安全风险较大的或难以管理的游玩项目暂时关闭叫作“降级”,其目的是保障游客的游玩核心体验。与此类似,服务降级的目的是重点保障用户的核心体验和服务的可用性。在异常、高并发的情况下可以忽略非核心场景或换一种简单处理方式,以便释放资源给核心场景,保证核心场景的正常处理与高性能执行。服务降级的实施方案灵活性较大,一般与业务场景息息相关,接下来我们介绍几种思路。
3.6.1 服务依赖度降级
一个服务虽然会有多个下游服务,但是每个下游服务的重要程度对它来说都是不一样的。例如,3.1节中提到的用户信息服务、内容列表服务对于个人页服务来说很重要,而地址位置服务和关系服务就不是很重要。
如果B服务是A服务的下游服务,那么B服务对A服务的重要性被称为“依赖度”。依赖度越高,表明下游服务越重要。依赖度可以用如下两种(但不限于)表示形式来反映下游服务对上游服务的重要程度。
二元:强依赖(出现故障时业务不可接受)和弱依赖(出现故障时业务可暂时接受)
三元:一级依赖(故障导致服务完全不可用)、二级依赖(故障基本不影响服务的可用性,会有少许可接受的用户投诉)和三级依赖(故障不影响服务的可用性,没有用户投诉)
在判断出某服务的各下游服务的依赖度后,便可以明确地知道请求量暴增时应该优先切断哪些下游服务调用,使得服务资源能够向更重要的下游服务倾斜,保障核心场景的可用性。假设出于拉新的目的,在年底针对某产品立项了一个盛典活动,并会在春节除夕夜20点整正式开启,于是研发团队开始了忙碌的备战与活动保障工作。
- 在项目筹备初期,架构师团队盘点盛典活动涉及的服务,以便提前发现风险,对每个服务进行改造。
- 架构师预测在活动期间A服务的QPS会高达100万,A服务成为此次活动的重点关注对象。
- 项目启动后,SRE工程师对A服务进行了扩容与全链路压测,经过反复的容量调整,初步认为在正常情况下,A服务已经可以应对100万QPS的请求量。
- 为了防止出现非预期故障,研发工程师重新梳理了 A服务的全部下游服务,并使用三元依赖度给出了梳理后的依赖度视图。如图3-26所示,B、D、H、J服务是一级依赖,C、G服务是二级依赖,E、F、I、K服务是三级依赖。
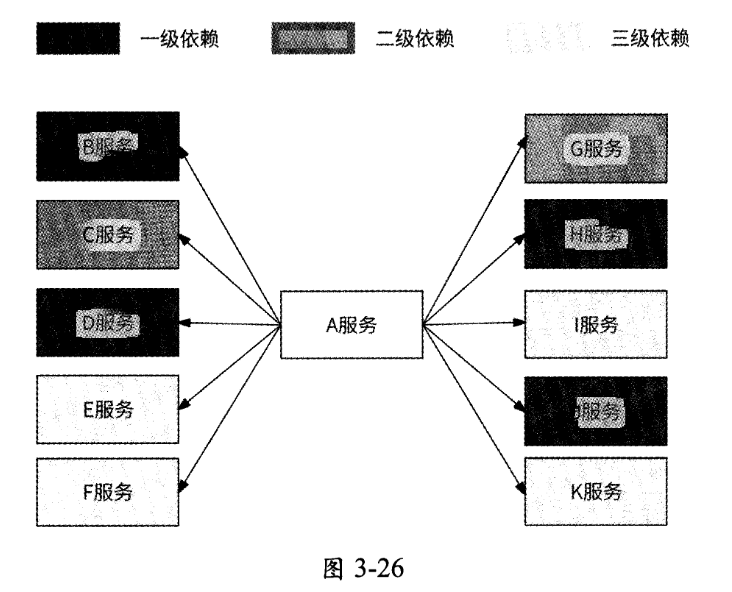
- 研发工程师根据依赖度,在A服务的动态配置中心为不同的下游服务设计了如下配置规则:
1 | { |
depend_map字段表示每个下游服务所对应的依赖级别(level_1、level_2、level_3),而level_2和level_3字段的值为布尔类型,表示在此依赖级别下是否可以执行下游服务调用。
- 在A服务调用某个下游服务前,先检查动态配置规则是否允许执行调用,如果不允许则不执行调用。研发工程师对动态配置中心的功能进行了演练测试。
- 在盛典活动开始前1分钟,研发工程师在动态配置中心控制开关,即设置
"level_3"=true,将A服务三级依赖的调用关闭,A服务降级。 - 盛典活动开始,研发工程师时刻监控A服务的性能指标,如果发现A服务的性能劣化,则将二级依赖的调用关闭,即在动态配置中心设置
"level_2"=true, A服务进一步降级。
此时A服务的全部资源都已经留给其一级依赖的调用,A服务降级到仅保障最核心功能的可用性,仅对B、D、H、J服务进行调用,这就是服务依赖度降级在活动属性的高并发场景中的应用。
其实服务依赖度不仅仅可以在高并发场景中应用,前面讲述的重试、熔断、限流也都 可以基于服务依赖度做更高级的增益精细化处理。
- 重试:仅对强依赖的下游服务进行重试。
- 熔断:把弱依赖的下游服务的熔断阈值设置得比强依赖的下游服务高一些,以便较早地停止调用弱依赖的下游服务,以及在确定强依赖的下游服务不可用时熔断它。
- 限流:如果上游服务认为下游服务是强依赖的,则优先保证其请求被执行;而如果认为下游服务是弱依赖的,则及时对其限流,将限流窗口更多地留给那些认为下游服务更重要的上游服务。
3.6.2 读请求降级
读请求降级策略与第2章介绍的高并发读场景的方案很类似,读请求的服务降级策略主要是缓存(Cache)和兜底数据。
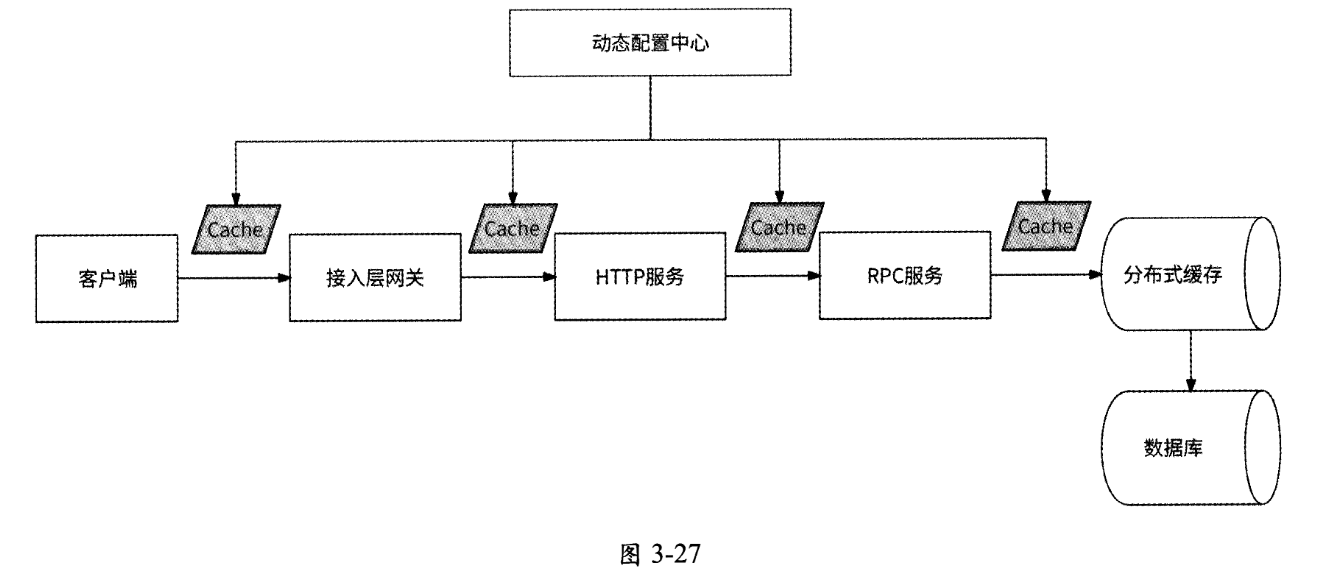
一个请求从客户端发起到最终数据响应一般会依次经过客户端、接入层网关、HTTP服务、RPC服务、分布式缓存、数据库,我们可以在客户端、接入层网关和HTTP/RPC服务中设置本地缓存,并在动态配置中心动态控制各层是否使用缓存,以及缓存的过期时间,如图3-27所示。
除缓存方式外,我们还可以应用兜底数据的思想:如果访问某数据失败,则降级为访问另一份基本可用的数据,其形式可以是静态数据,也可以是来自另一个数据源的数据。下面举两个例子。
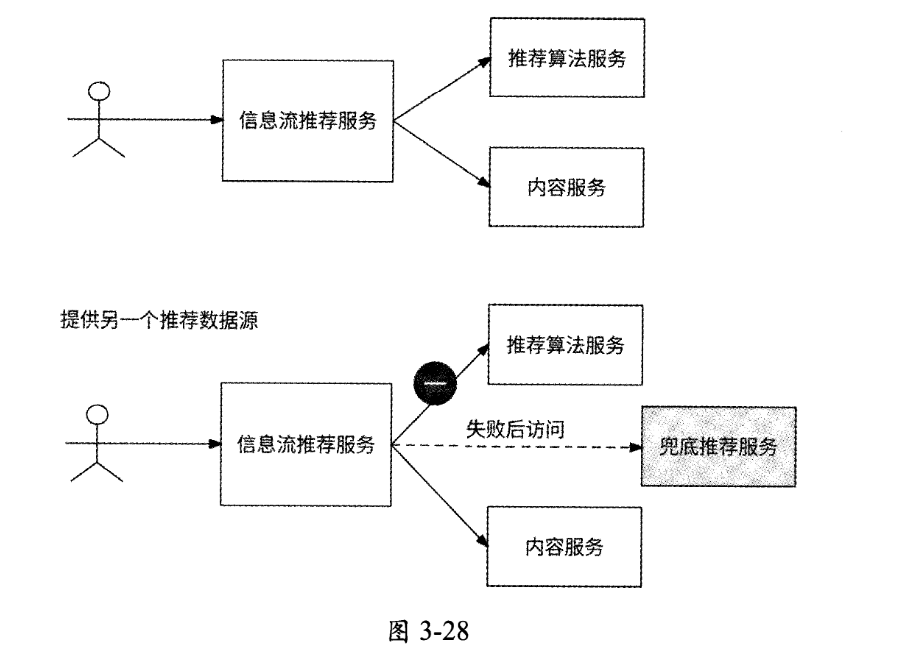
(1)将另一个数据源的数据作为兜底数据。近年来,很多互联网应用都内置了非常流行的内容推荐功能,由信息流推荐服务负责提供服务。信息流推荐服务有两个核心的下游服务:推荐算法服务和内容服务。推荐算法服务先根据用户爱好计算出一批内容ID,再由内容服务对完整的内容进行打包。不过,推荐算法服务是典型的计算密集型场景,它的可用性和性能表现一般,如果它不可用了,那么信息流推荐服务也就不可用了。解决方法是应用兜底数据的思想:每天零点离线计算出一批用户可能感兴趣的内容或热门内容的ID列表,由兜底推荐服务维护,当信息流推荐服务调用推荐算法服务超时或推荐算法服务不可用时,就转而调用兜底推荐服务获取内容ID列表,如图3-28所示。
(2)将静态数据作为兜底数据。例如,很多直播平台都提供了打赏功能,用户打开礼物列表选择礼物送给主播,主播根据礼物的价值获得收入。如果礼物列表服务不可用,那么用户想打赏时就会发现没有礼物可选,进而导致直播平台收入受损。解决方法是事先在接入层网关配置几个常见礼物数据,如果在接入层网关访问礼物列表服务失败,则可以直接返回配置的礼物数据,这样用户打开礼物列表至少可以看到几个礼物,提高了用户打赏的可能性。
3.6.3 写请求降级
写请求降级策略有异步写和写聚合,这些内容在第2章中有详细介绍,这里不再赘述。在某些业务场景下,我们还可以直接丢弃写请求,一个值得介绍的例子就是直播间弹幕自见。
用户可以在直播间内发送弹幕与主播进行文字互动。在正常流程下,用户发送弹幕到对应的弹幕服务,然后弹幕服务将用户的弹幕消息广播到直播间的所有用户。如果直播间热度较高,则会有海量用户参与发送弹幕。假设某直播间有100万个在线用户,每秒有100个用户发送弹幕,为了让100万个用户都能看到这100条弹幕消息,弹幕服务每秒需要下发1亿条消息,服务器网络带宽被占满。
一种可能的降级方案是直播间弹幕自见。
- 用户A发送弹幕,客户端直接在直播间展示这条弹幕消息,用户A认为弹幕发送成功。
- 在动态配置中心配置客户端消息丢弃比例,客户端按比例决定是否把这条弹幕消息发送到服务端。
- 弹幕服务不再直接把弹幕消息广播到直播间的全部用户,而是根据动态配置中心 配置的消息广播比例,将弹幕消息随机广播到一部分直播间用户。
- 研发工程师根据弹幕服务的性能,实时调整客户端消息丢弃比例和消息广播比例。
这种降级方案的可行性在于:热门直播间弹幕量大,一个用户发送的弹幕本来就会被淹没在不断刷屏的新弹幕中,用户也并没有执念一定要让直播间的其他用户看到自己发送的弹幕,所以这个场景的写请求很适合做请求丢弃和广播控制。
本章小结
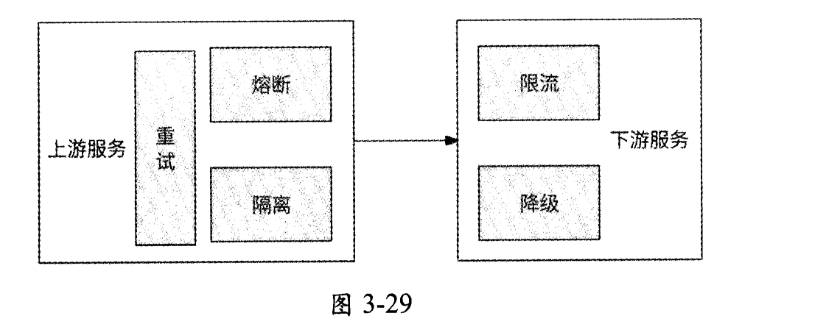
微服务架构最大的特点就是通过错综复杂的网络调用串联起各司其职的微服务,网络的健壮性和请求流量的变化都会影响每个服务的质量。如图3-29所示,通过在网络调用链路上引入重试、熔断、隔离、限流、降级,可以有效控制流量和保证各服务的可用性。
下面我们逐个复习本章的主要技术点。
(1)重试:提高单次请求的成功率。
- 只有幕等接口可以被重试,读接口天然满足幂等性,而写接口需要做幂等性接口设计。
- 幂等性接口设计方案包括Redis分布式锁、数据库防重表、token方案。
- 根据调用失败的原因决定是否需要重试。如果重试、则需要使用合适的退避策略决定请求重试的时机。
- 为了防止重试风暴,可以控制最大重试次数和重试请求比。
(2)熔断:上游服务保护下游服务不被打垮。
- 熔断器可以自动感知下游服务的故障状态并开启熔断,停止下游服务调用。
- Hystrix熔断器基于时间窗口失败率的策略开启熔断,是最基本的熔断器。
- 在开启熔断一段时间后,Hystrix熔断器通过半开状态探测下游服务是否已经恢复。
- Resilience4j熔断器还采用了慢调用比例策略开启熔断:慢速请求在总请求量中的比例是否达到阈值。
- Sentinel断器还基于错误计数的策略开启熔断:最近1分钟的请求失败数超过阈值。
(3)隔离:防止下游服务调用相互影响。一般使用线程池隔离或信号量隔离策略对每个下游服务的调用做并发控制。
(4)限流:下游服务保护自己不被上游服务打垮。
- 频控是一种特殊的限流,对单个用户限制操作频率,基于Redis实现。
- 单机限流有滑动时间窗口算法、漏桶算法、令牌桶算法,限流阈值依赖人工设置,令牌桶算法表现最优。
- 全局限流通过引入限流服务,业务服务的各个实例共享限流配额,只有涉及共享资源并发控制时才建议使用此策略。
- 服务处理请求的流程可以被抽象为请求在等待队列中排队等待执行。
- 自适应限流不需要人工设置限流阈值,而是根据服务实例的当前服务能力动态限流。业界采用的方案有基于请求排队时间和基于延迟比率的自适应限流,以及BBR limiter算法等。
(5)降级:保障服务核心功能的可用性,具体的实施方案比较灵活。
- 使用服务依赖度表示下游服务的重要程度,当服务压力升高时可以切断不重要的下游服务调用,将服务资源倾斜给重要的下游服务。
- 对于海量的读请求,可以使用多级缓存数据或兜底数据做降级策略,兜底数据可以是静态数据,也可以是来自另一个数据源的数据。
- 对于海量的写请求,异步写和写聚合是较为通用的降级策略,在某些业务场景中也可以丢弃写请求,减小写请求量级。
总结
服务降级的目的是啥?
- 重点保障用户的核心体验和服务的可用性。
什么是依赖度?
- 反映下游服务对上游服务的重要程度。
依赖度的表现形式?
- 二元:强依赖(出现故障时业务不可接受)和弱依赖(出现故障时业务可暂时接受)
- 三元:一级依赖(故障导致服务完全不可用)、二级依赖(故障基本不影响服务的可用性,会有少许可接受的用户投诉)和三级依赖(故障不影响服务的可用性,没有用户投诉)
一个请求从客户端发起到最终数据响应一般经过哪些过程?
- 一个请求从客户端发起到最终数据响应一般会依次经过客户端、接入层网关、HTTP服务、RPC服务、分布式缓存、数据库




