第1章大型互联网公司的基础架构——1.14 多机房:异地多活

第1章大型互联网公司的基础架构——1.14 多机房:异地多活
John Yaml大部分互联网应用使用“同城双活”架构就可以承担海量用户请求与保障后台高可用了,但是如果你的应用不是仅面向一个国家,而是面向全球(如Facebook、Instagram等), 那么“同城双活”架构就会带来一些问题。
- 用户访问延迟问题。比如我们在泰国曼谷建设了“同城双活”机房,泰国、日本、 韩国、马来西亚等附近国家用户的访问请求能被快速响应,而欧洲用户的访问请求只能“跨越山河大海”才能接入机房(因为欧洲距离曼谷物理位置太远),这就会造成访问延迟大大增加,用户会明显感觉到应用卡顿。
- 数据合规问题。很多国家非常注重互联网用户隐私数据安全,它们通常要求应用将本国用户的数据独立存储到本国机房。“同城双活”架构最多只能满足一个国家的数据合规要求。
- 灾难问题。如果部署机房的国家发生了战争、暴乱、自然灾害等,则可能导致机房被破坏,进而导致整个应用在全球范围内不可用。
全球级互联网应用后台一般采用多国部署机房的架构:在全球范围内筛选几个国家和城市部署机房并负责接入附近国家用户的访问请求,各个机房之间通过数据复制保证它们都有全球全量数据,这就是“异地多活”架构。
1.14.1 架构要点
假设我们在全球建设了3个“异地多活”机房,它们的具体分布情况如下。
- 美国机房:选址于美国洛杉矶,服务于美国、加拿大、巴西等美洲国家用户。
- 欧洲机房:选址于德国柏林,服务于欧洲、中东各国的用户。
- 马来西亚机房:选址于吉隆坡,主要服务于印度、日本、韩国、东南亚各国的用户。其他人口较少的国家与地区的用户也默认访问此机房。
在“同城双活”架构下,会选择一个机房的数据库作为存储层的主库,其他机房的写数据请求会跨机房写入主库,而读数据请求则依赖各存储系统自带的主从复制功能,实现机房间数据的复制。但是“异地多活”架构无法照搬这种存储层设计,其原因就是“异地”意味着机房间物理距离太远,使得网络通信产生巨大延迟,网络访问的成功率无法得到保证。最终的结果如下。
- 用户写请求卡顿明显,容易请求失败。
- 各存储系统的从库经常与主库断连,数据复制延迟巨大。
所以,“异地多活”架构的第一个要素是应该让每个机房都在本机房内处理写数据请求,即每个机房都独立部署各存储层的主库,各个机房的存储层之间不再有主从关系。
如此一来,“异步多活”架构的存储层设计如图1-62所示。
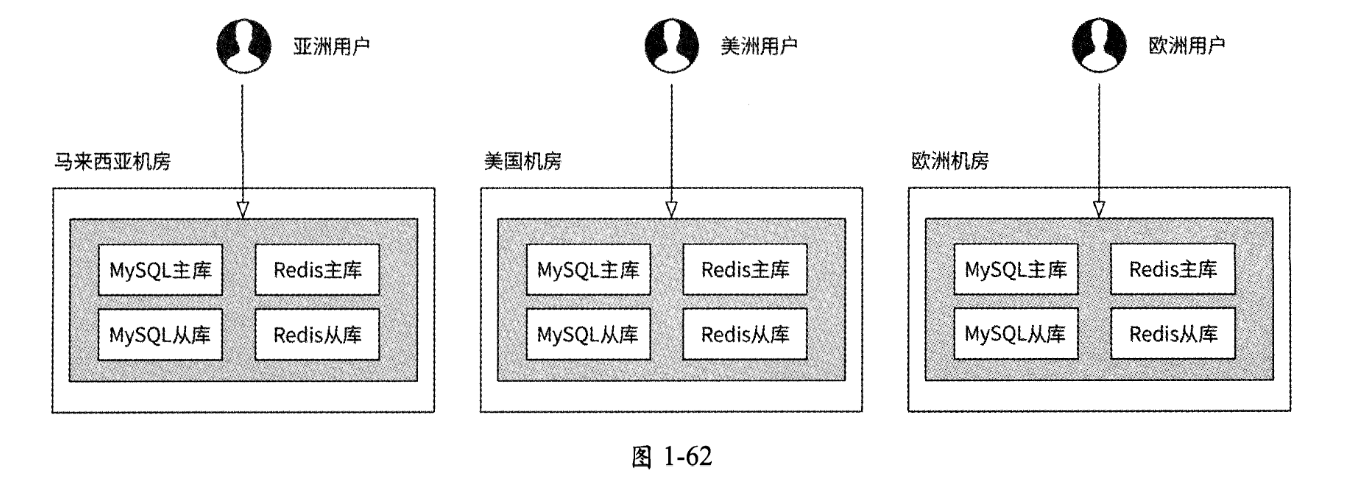
从图1.62中可以看出,各国用户的数据读/写请求都只在相关机房的存储层内独立处理,各机房间完全独立。每个用户的读/写请求均可以得到较快的响应。但是,这个架构有一个明显的缺点:每个用户只能看到一个机房的数据,在应用表现层面,日本用户只能与日本、韩国、东南亚各国的用户互动,而无法感知到美洲、欧洲等地区用户的存在,更无法与这些用户建立关系。这对于任何一个全球互联网应用来说都是完全不符合产品预期的。
所以,“异地多活”架构的第二个要素是数据互通,即每个机房都应该将本机房写入的数据复制到其他机房,这样才能实现任何用户都可以与任何国家的用户互动。在“异地多活”架构下,每个机房存储层的主库都可以通过跨国专线向其他机房存储层的主库复制数据,最终架构如图1-63所示。
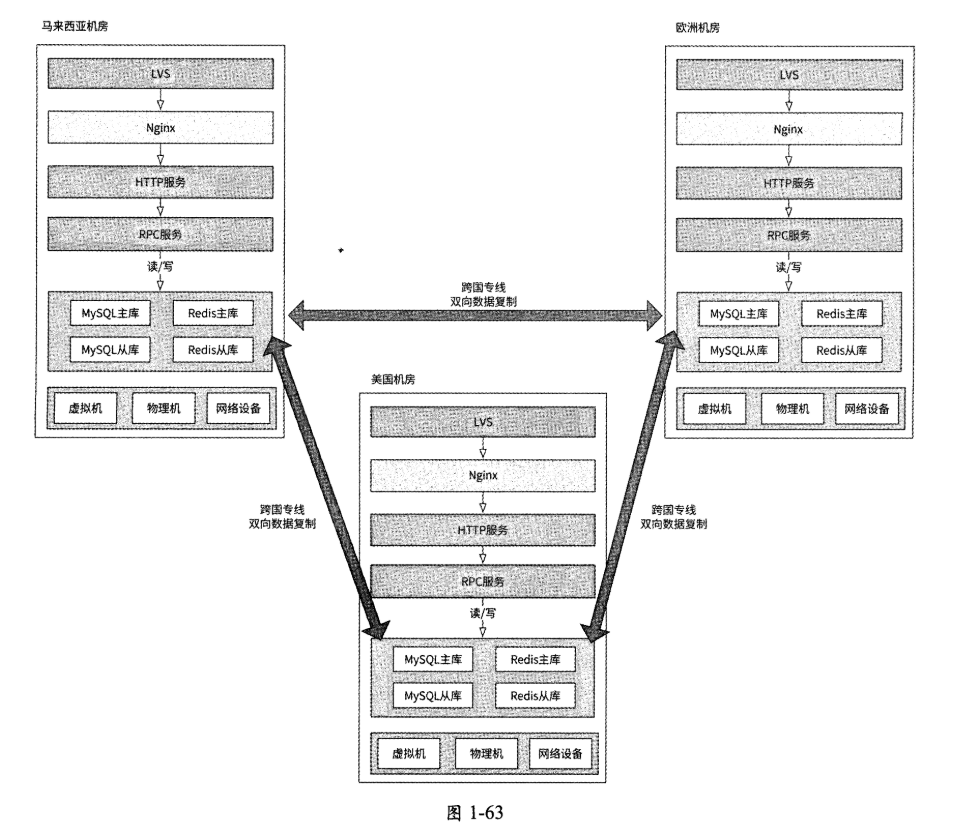
无论是MySQL、Redis还是其他存储系统,官方都不支持主库与主库之间复制数据(简称“主主复制”),所以构建“异地多活”架构需要我们对各种存储系统进行一定的改造。
在这方面业界有较多成熟项目,比如阿里巴巴分别为MySQL、Redis、MongoDB开发的“主主复制”中间件Otter、RedisShake、MongoShake。携程公司的Redis多数据中心复制管理系统XPipe,它们都是在“异地多活”场景下存储层跨机房“主主复制”的优秀工具。这种负责存储系统双向数据复制的工具一般被称为DRC (Data Replicate Center)。
1.14.2 MySQL DRC 的原理
MySQL DRC工具的组成结构一般如图1-64所示。
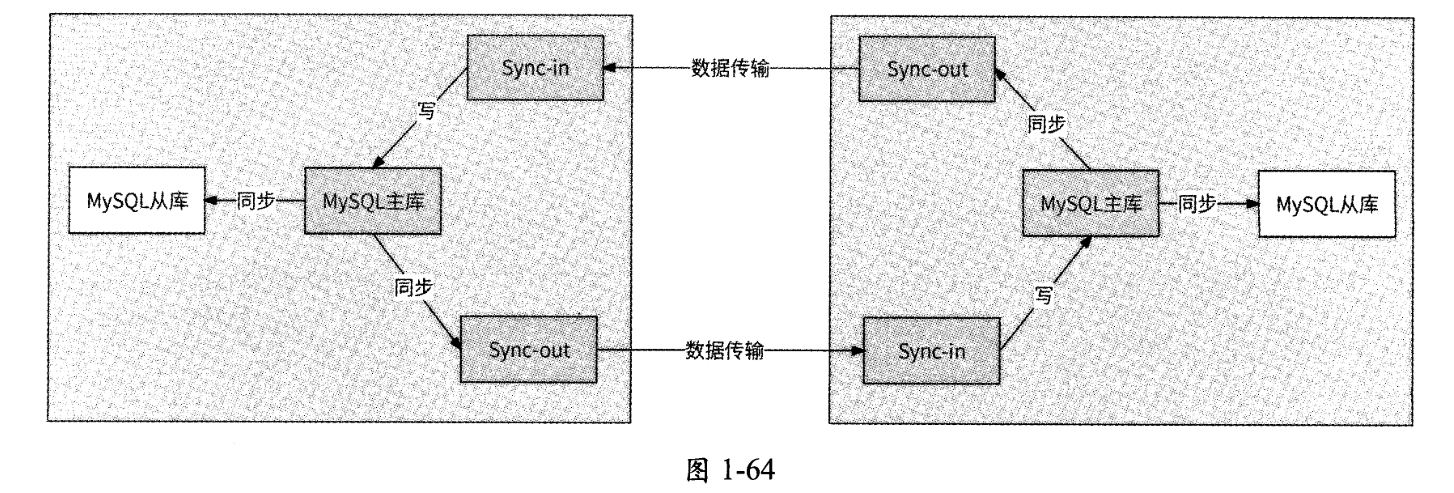
- Sync-out:负责将本机房MySQL主库的数据复制到另一个机房,扮演从库的角色。它会模拟MySQL从库与主库的交互协议,将自己伪装成一个从库来访问主库,于是主库会将binlog数据发送给Sync-out,最后Sync-out实时得到了主库的数据变更记录。这种实时获取主库数据的技术被称为“伪从”,相关开源项目包括阿里巴巴的Canal、LinkedIn公司的Databus等。
- Sync-in:负责接收从另一个机房复制过来的数据并写入本机房的MySQL主库。
为了将数据复制到其他机房,Sync-out会与远端机房的Sync-in建立TCP长连接,Sync-out收到主库的binlog记录后解析保存到本地磁盘,同时会不断传输数据到远端Sync-in,Sync-in收到。Sync-out宕机、传输网络连接断开都会导致数据传输中断,DRC工具可以借助MySQL GTID实现断点续传能力:Sync-out在数据传输过程中会记录最新的已传输成功的数据GTID,在Sync-out宕机重启或者传输网络断线重连后,都可以根据GTID迅速定位到binlog文件的某个位置,而后Sync-out继续传输此位置之后的数据。
GTID (Global Transaction Identifier)是MySQL对每个已提交事务的编号,并且是MySQL主从集群中全局唯一的编号。GTID和事务会被记录到binlog文件中,用来标识事务。根据GTID可以准确定位到一个事务在binlog文件中的位置。
Sync-in扮演了数据库客户端的角色。Sync-in收到远端Sync-out复制过来的数据后,还原写数据SQL语句并在本机房的主库中执行。
断点续传可能造成数据被重复传输,我们需要避免重复数据被写入远端机房。具体的处理方式也是应用GTID: Sync-in保存已写入数据GTID的集合用于数据防重。当Sync-in收到远端Sync-out传输过来的数据时,先检查此GTID是否已在GTID集合中,如果在,则说明此数据被重复传输了,Sync-in直接忽略此数据。
使用DRC工具还可以防止数据回环。数据回环指的是数据变更记录被从A机房复制到B机房,又被从B机房复制回A机房的现象。例如,在A机房对数据D进行修改(将其值从v0修改为v1),binlog会产生类似于“D: v0->v1”的变更记录,于是这条记录会被Sync-out复制到B机房;B机房的Sync-in将此记录写入数据库,从而造成“D: v0->v1”又被B机房主库的binlog文件记录,于是Sync-out又将这条记录复制到A机房,这就使得“D: v0->v1”产生了数据回环。
数据回环根据结果具体分为两种情况。
- A机房的“D: v0->v1”回环一次回到A机房。由于A机房数据D的值早已是v1,被回环的数据变更记录并没有修改数据值,所以不会产生binlog记录,回环结束。这种情况只会造成数据变更记录被回环一次。
- 在A机房,在很短的时间内对数据D进行了两次修改:“D: v0->v1”和“D: v1->v0”,这两条变更记录回环一次回到A机房。由于A机房数据D的值为v0,所以“D: v0->v1”和“D: v1->v0”被相继执行并再次记录到binlog文件中,从而产生了新的回环,并进入无限回环的局面。这将严重占用机房间数据传输通道的带宽。
防止数据回环的方案并不复杂:
- 在主库中创建一个辅助表,用于记录哪些数据变更事务来自其他机房;
- Sync-in在将数据写到主库时利用事务机制在辅助表中插入一条数据;
- Sync-out解析主库发送的binlog数据,检查每个事务是否有写辅助表,如果有,则说明数 据变更事务来自其他机房,不传输此数据。
这里还需要考虑的一个问题是数据冲突。在A机房和B机房几乎同时修改了数据D,A机房的数据变更记录是“D: v0->v1”,B机房的数据变更记录是“D: v0->v2”; A机房将数据变更记录发送到B机房时,发现数据D的值为v2,产生了数据冲突。
数据冲突很难解决,我们只能使用一些策略来决定在数据冲突时选择哪一方的修改结果。一种可能的策略是Last Write Wins(LWW),即最后写入者胜利策略:主库在数据变更时自动记录每行数据的最新修改时间,当B机房的Sync-in收到“D: v0->v1”的变更记录,却发现本机房的数据D的值为v2时,对比“D: v0->v1”的修改时间与数据D的最新修改时间——如果前者更晚,则执行写入,否则“D: v0->v1”被忽略。LWW依赖时间戳,其本意是让更晚发生的数据变更记录作为最终结果,但是不同机房同一时刻的时间戳并不一定相同,这就使得数据变更的时间早晚顺序并不准确,所以这种策略并不准确。
要想真正解决数据冲突,只能尽量避免数据冲突。比如在订单系统中,如果在数据库中创建订单时使用自增主键作为订单ID,那么不同机房创建的不同订单就有了相同的订单ID,机房双向复制时就会产生大量数据冲突。所以,如果某服务需要异地多活,那么这个服务的业务逻辑就不能对数据库自增主键有任何依赖,而是应该采用分布式唯一ID 等方案(见第4章)。
此外,在机房分流上,应该尽量保证不同的用户被分流到不同的机房,这样才能使得与每个用户相关的数据同一时刻仅在一个机房内被修改,而避免了在不同的机房同时修改这个用户数据的可能。
这里做一个总结:MySQL DRC工具的技术核心要点包括实现伪从、断点续传、数据防重,以及防止数据回环和数据冲突。其实不仅仅是MySQL,其他任何存储系统的DRC 工具设计都是围绕这几个要点展开的。
1.14.3 Redis DRC 的原理
Redis DRC工具的设计思路与MySQL DRC工具类似,依然需要Sync-out与Sync-in组件。不过,Redis与MySQL作为存储系统在功能上有较大的差异,实现伪从、断点续传、数据防重,以及防止数据回环和数据冲突需要不同的手段。
(1)伪从
对于伪从:由于Redis自带主从复制功能,所以Sync-out模拟Redis从库向Redis主库复制数据即可,复制的数据形式是Redis写命令。Sync-out将Redis写命令暂存到本地。
(2)断点续传
对于断点续传和数据防重:Redis没有MySQL的GTID机制可以唯一标识一个事务,所以我们只能自己开发一套Redis专用的GTID,使用递增的唯一ID来达到此目的。Sync-out为每个收到的Redis写命令都绑定一个单调递增的ID,并保存目前已成功传输的写命令ID。这样一来,在网络故障恢复或Sync-out重启后,就可以继续传输了。对端机房的Sync-in也保存最近成功写入的写命令ID,如果Sync-in收到的新的写命令ID小于或等于这个ID,则说明收到了重复数据,丢弃即可。
(3)数据回环
对于数据回环:Redis防止数据回环可以通过如下两种思路。
- 改造Redis的写命令格式,让其携带机房信息。
- Redis主库识别Redis客户端的角色,如果是Sync-in发来的写命令,则不复制到Sync-out。
第一种思路需要修改Redis的全部写类型命令,且每当Redis升级到新版本加入新的写命令时,我们都要跟进修改,整体的维护成本和实现成本较高。
第二种思路的实现方式是:Redis服务器使用一个名为redisClient的结构体类型来表示每个客户端的TCP连接信息。其中的flags属性用于记录客户端的角色,以及客户端目前的状态:
1 | typedef struct redisClient { |
flags属性的值可以是单个标志:
1 | flags = <flag> |
也可以是多个标志的二进制或,比如:
1 | flags = <flagl> | <flag2> | ... |
每个标志都使用一个常量表示,其中一部分标志记录了客户端的角色:
- 在主从复制架构下,REDIS_MASTER标志表示客户端代表的是主库,REDIS_SLAVE标志表示客户端代表的是从库。
- REDIS_PRE_PSYNC标志表示客户端代表的是一个版本低于Redis 2.8的从库。
- REDIS_LUA_CLIENT标志表示客户端是专门用于处理Lua脚本中包含的Redis命令的伪客户端。
我们可以增加两个客户端角色标志“REDIS_SYNC_IN”和“REDIS_SYNC_OUT”,分别表示Redis客户端是Sync-in和Sync-out。这样Redis主库便可以轻松识别出客户端角色类型。当Redis主库收到来自Sync-in的写命令时,说明此写命令来自其他机房,因此不会将此写命令复制给Sync-out,数据回环被阻断。防止数据回环的架构如图1-65所示。
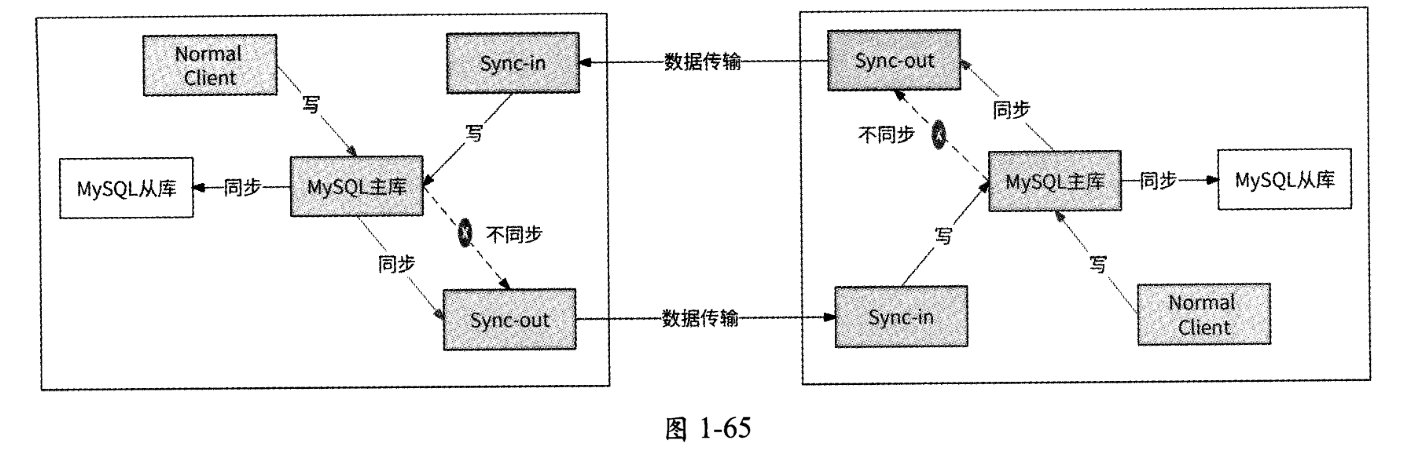
(4)数据冲突
对于数据冲突:Redis没有简单的处理方式为写命令增加时间戳,大多数Redis DRC工具在尝试解决数据冲突时都避免不了引入时间戳的概念,且因机房间时间戳的不一致并不能彻底解决问题。另外,Redis的写命令远比MySQL的丰富得多,为这些写命令实现防止数据冲突的数据结构困难重重,所以Redis也应该如同MySQL一样尽量避免数据冲突。
1.14.4 分流策略
将一个用户的访问请求固定在一个机房可以有效防止存储层数据冲突。虽然通过“同城双活”架构的DevicelD分流策略可以达到这个目的,但是这种策略无视用户的地理位置,必然导致大量用户被分流到距离很远的机房,比如韩国用户被分流到欧洲机房。这会明显降低用户访问体验,所以它并不适合“异地多活”架构。
适合“异地多活”架构的分流策略一定要考虑用户的地理位置,DNS正好支持按地域配置域名解析,我们可以为不同的国家用户配置不同的机房接入层IP地址,保证绝大多数用户可以通过DNS直达目标机房。
DNS分流策略的缺点是用户网络环境会干扰域名解析结果,比如用户使用了VPN、 非本国SIM卡以及用户出国旅行等情况都可能导致用户被分流到其他机房。为了彻底固定一个用户访问的机房,我们需要将用户所在国固定下来,使得用户所访问的目标机房的地址不受其行为的影响。
一种固定用户所在国的方案是用户注册国策略。新用户在应用内注册账号时,客户端携带用户国家信息作为其注册国,后台创建用户初始信息时保存注册国信息;之后用户的任何访问请求都根据注册国来选定目标机房。客户端可以将使用SIM卡国家代码或者IP地址反查得到的国家作为其注册国。
在确定了用户注册国后,用户每次登录应用时都会先从用户信息服务中获取注册国信息,然后根据注册国映射到预先配置好的机房。比如我们配置了日本用户访问马来西亚机房,那么注册国是日本的用户无论是出国还是使用VPN等都将固定访问此机房。
受限于用户注册国策略,日本用户在欧洲旅行期间访问应用会出现卡顿。如果用户是短期旅行尚可接受,但如果用户是出国长居,那么总是出现访问卡顿可能会让用户失去耐心。我们可以对用户访问请求进行国家维度的监控,如果发现某用户访问请求时当前所在国与注册国在连续较长的时间内都不同,则可以将用户注册国改为当前所在国,以及时改善用户体验。
1.14. 5 数据复制链路
“异地多活”架构的“多活”要求每个机房都将主库数据复制到其他所有机房,所以双向数据复制链路数为:
$$C_{N}^{N-1} = \dfrac {N \times (N-1)}{2}$$
例如,在有3个机房的情况下,需要3条双向数据复制链路,如图1-66所示。
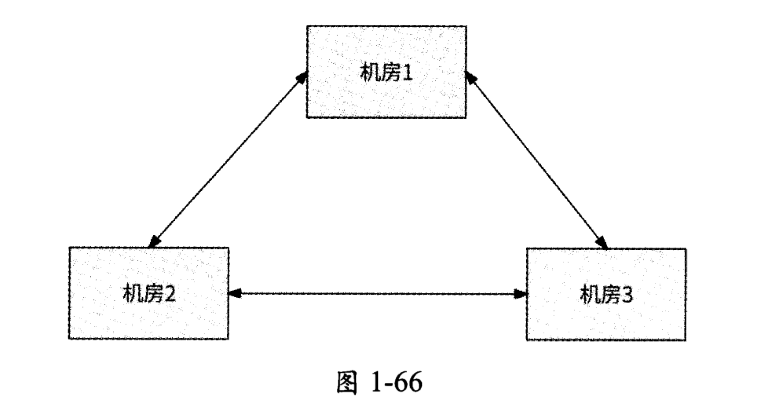
3个机房需要3条双向数据复制链路看起来没什么问题,那如果“异地多活”架构有6个机房呢?双向数据复制链路将达到15条,如图1-67所示。
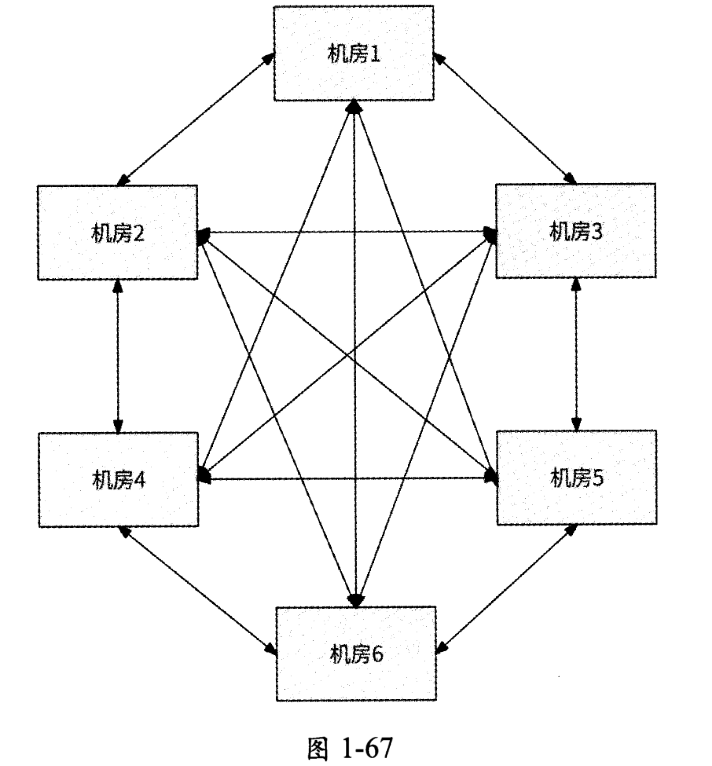
这种网状结构表明,稍稍增加机房数量就会使得双向数据复制链路激增,这将导致机房维护成本也骤然升高。对于这种情况,我们可以进一步优化:约定某个机房为中心机房,其他机房的主库数据仅被复制到中心机房,再由中心机房将其复制到全部机房,形成如图 1-68所示的星状结构。
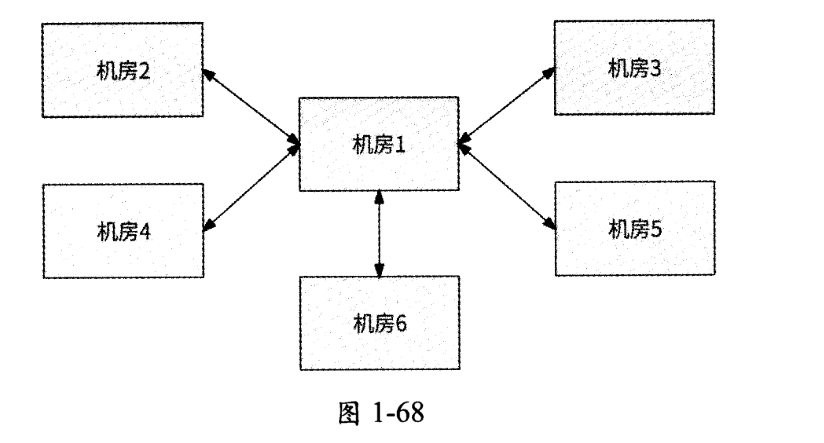
从图1-68中可以看出,同样的6个机房,星状结构只需要5条双向数据复制链路,机房架构的复杂度大大降低。在网状结构下,如果机房数量远大于双向数据复制链路数,则适合改造为这样的星状结构。
本章小结
在一个互联网应用内,用户在PC端、移动端的任何点击行为几乎都会通过互联网发出网络请求到应用后台机房,从发出请求到请求被响应的时间虽然非常短,但在这短短的时间内却涉及很多事情。
- 用户请求以HTTP形式发出,并通过域名指定应用所在机房的地址;DNS、HTTP-DNS等技术提供了域名解析服务,使得用户请求的目的地指向应用机房的接入层IP地址。
- 用户请求进入机房后到达四层负载均衡器LVS,LVS将用户请求进一步转发到七层负载均衡器Nginx。
- Nginx根据用户请求的URL与已配置的URL转发规则进行匹配,将用户请求进一步转发到相关业务层的HTTP服务。
- HTTP服务处理用户请求,并根据业务逻辑继续向相关业务层的RPC服务发起调用。
- RPC服务处理请求,在处理逻辑中可能需要调用其他RPC服务,或者从存储层的Redis、MySQL等中获取相关业务数据。
后台机房最初以单机房的形式提供服务,但是随着用户量级的增长和机房故障影响面的扩大,很多公司开始构建各种类型的多机房架构。
- 主备机房架构。主机房对外提供服务,备机房完全复制主机房的架构与数据;当主机房发生故障时,将用户切流到备机房。这种架构方案不仅浪费资源,而且可用性存疑,所以很少有互联网公司采用。
- “同城双活”架构。在距离较近的地理位置上搭建两个机房,每个机房都对外提供服务;在存储层选择一个机房作为主机房,另一个机房的数据库作为主机房数据库的从库,读数据请求由本机房存储层处理,而写数据请求均被转发到主机房存储层处理,主机房使用各存储系统提供的主从复制技术将最新数据传输到另一个机房。绝大多数互联网应用后台使用“同城双活”架构就可以达到机房高可用的目的。
- “异地多活”架构。对于服务于全球用户的世界级应用而言,“同城双活”架构只会考虑到机房所在城市附近国家的用户体验,而对于跨海、跨洲的其他用户会有明显的访问延迟。所以,此类应用更适合采用“异地多活”架构一在全球若干有代表性的城市和地区建设机房,每个机房都服务于附近国家的用户。在“异地多活”架构下,存储层要求每个机房都闭环承接自己的写数据请求,以防止跨机房访问;同时要做到各机房数据全球可见,所以相关的存储系统需要借助DRC工具实现双向数据复制。




