第1章大型互联网公司的基础架构——1.13 多机房:同城双活

第1章大型互联网公司的基础架构——1.13 多机房:同城双活
John Yaml既然处于空闲状态的备机房既浪费资源又不确定可用,那么让备机房也与主机房一样日常对外提供服务不就好了吗?这样一来,机房资源被利用起来,也有了承接用户流量的实战经验,这就是“同城双活”架构。
1.13.1 存储层改造
“同城双活”架构与主备机房架构类似,只不过我们需要做一些改造:将两个机房的接入层IP地址都配置到DNS。这样做的效果是两个机房都能负责一部分用户请求,形成 了“双活”的局面。
如图1-58所示,A机房与B机房组成“双活”机房,并由DNS负责决定将用户请求分流到哪个机房。从对外提供服务的角度来说,两者是对等的。此外,两个机房的服务可以通过专线实现互相访问,即“跨机房调用”。

但是这里有一个核心问题还没有解决:在主备机房架构下,备机房(即B机房)存储层的数据库是A机房的从库,从库意味着只能读数据,不可写数据,也就是B机房无法处理写请求,这样的“双活”无法达到我们的预期。
我们接着对存储层的访问做一些改造:B机房的所有写数据请求在访问存储层的数据库时,直接跨机房访问A机房对应的主库——无论是将数据写入Redis、MySQL、MongoDB还是写入其他存储系统,如图1-59所示。
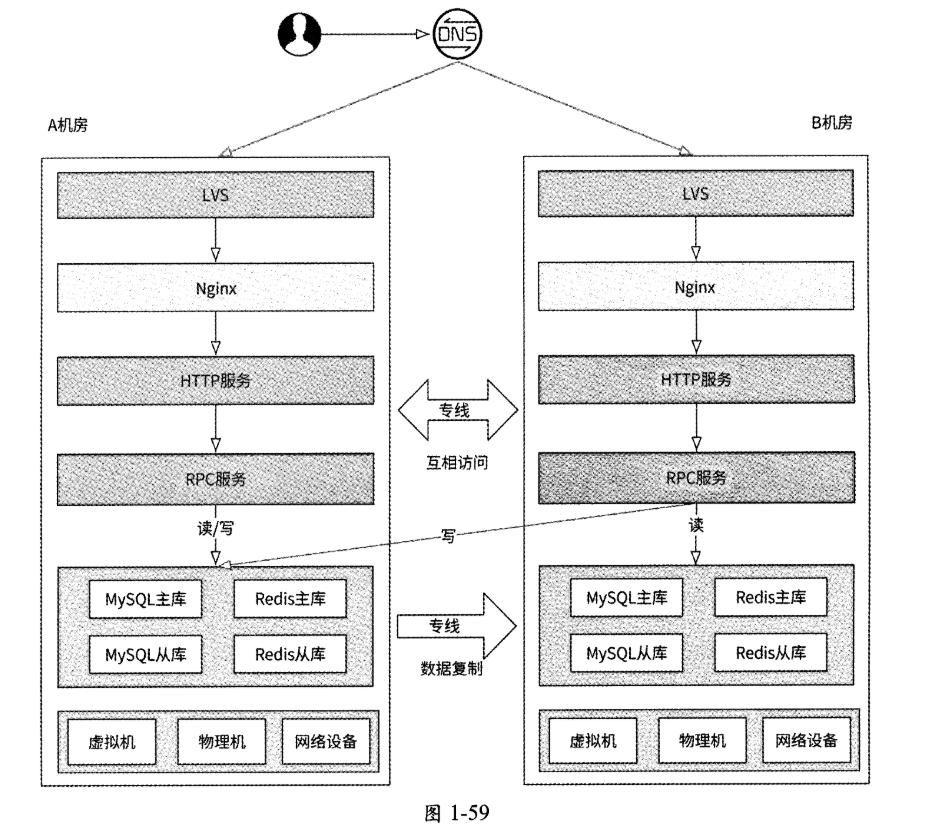
同一机房内网络通信的性能开销极小,可以忽略不计,而跨机房网络通信则会带来一定的网络延迟,因为机房之间有一定的物理距离。因为B机房的写数据请求需要跨机房访问A机房,所以这些写请求的延迟必然会增大。这是否是“同城双活”的潜在缺点?其实并不是。
- 首先,对于绝大多数互联网应用来说,写数据场景远远少于读数据场景,也就是写请求的用户流量占比极低;
- 其次,两个机房被部署在同一个城市,即两者的物理距离很近,在专线通道的加持下跨机房请求的代价极低,延迟只会增加5ms左右。
- 所以,在逻辑上,我们可以把“同城双活”机房当作单机房来使用,不用过度在意跨机房访问的延迟问题。
1.13.2 灵活实施
虽然名为“同城双活”,但是我们在应用此架构方案时应该清楚其思想,而不局限于名字。
首先,同城主要强调机房间的物理距离很近,而不是非要将机房限定在同一个行政区域内。我们固然可以在北京市昌平区部署A机房,在北京市怀柔区部署B机房,但是也可以在北京市延庆区部署A机房,在河北省张家口市部署B机房,因为延庆和张家口的物理距离足够近。保持双机房有较近的物理距离,是为了极大地缓解跨机房访问数据库带来的网络延迟。然而,物理距离也不能近得“离谱”,比如A机房和B机房都被部署在张家口某数据基地,虽然跨机房访问的网络延迟小了,但是这样的双机房架构和单机房并无区别,A机房遭遇断电、火灾等意外事故,隔壁的B机房大概率也是“难兄难弟”。
其次,“同城双活”可以被灵活应用为“同城多活”,我们不一定只部署两个机房,而是可以部署更多的机房,只要保证在存储层选出唯一的主机房就好。比如可以分别在北京市的昌平区、延庆区、怀柔区建设A、B、C三个工作机房,只要保证A机房存储层的数据库是主库,B、C机房存储层的数据库作为从库,并且B、C机房可以向A机房复制数据,以及写请求跨机房访问A机房即可。
1.13.3 分流与故障切流
用户的请求从客户端发起,这个请求应该访问哪个机房由分流策略来决定。因为可以将“同城双活”简单地当作单机房来用,所以分流策略也没有考虑太多因素,只要控制部分用户访问A机房、部分用户访问B机房即可。其实现方式是可以根据用户ID(UserID)或客户端设备ID(DevicelD)将用户请求哈希映射到不同的机房。笔者建议使用DevicelD来做哈希映射,这样可以使得未登录账号的设备也能被分流。
接下来讨论在哪个环节实施分流策略。上文中介绍过,我们可以将双机房接入层IP地址配置到DNS来实现将用户请求分流到不同的机房。但是这种分流方式相对粗糙——由于域名解析结果的不确定性,很有可能出现同一个用户的请求时而被分流到A机房、时而被分流到B机房的情况,且分流策略变更的生效时间会因为DNS缓存的存在而变长。
实际上,我们还可以在客户端、HTTP DNS或其他接入层组件中实现分流。这里先介绍客户端分流,它需要服务端与客户端配合来实现准实时分流。
首先创建一个分流配置平台并将其部署在各机房,工程师可以在这个平台上配置各个域名的分流比例。一个域名的分流配置项可以被设计为如下结构:
1 | "api.friendy.com": { |
各个字段的含义如下。
- sharding:表示DevicelD经过哈希运算后的取模值。
- ide:表示涉及的多活机房配置,每个机房都有唯一专用名称,比如changping表示昌平机房,yanqing表示延庆机房。为每个机房都配置了如下字段。
- lower upper:如果DevicelD哈希取模值在[lower, upper)区间,则表7K需要将请求发送到对应的机房。
- domain:机房的专用域名,这个域名只会被解析到对应的机房。
接下来,客户端需要支持拉取分流配置,并根据配置内容执行分流策略。我们以上述配置内容为例,介绍客户端分流的工作流程。
- 当客户端向域名
api.friendy.com发起请求时,如果发现此域名有分流配置,则尝试执行分流策略。 - 客户端使用DevicelD进行哈希运算,并以sharding取模值:hash(DeviceID)%100,假设得到计算值为30。
- 客户端发现DevicelD哈希取模值在changping的[0, 50)区间,说明此请求应该被分流到昌平机房。
- 客户端将请求域名替换为
api-cp.friendy.com后再发送请求,经过DNS解析后请求被分流到昌平机房。
当工程师修改了分流配置时,分流配置平台应该及时告知客户端分流策略有变更。一种可行的做法是在接入层Nginx上记录最新分流配置的版本号,任何客户端请求被响应前经过Nginx时都会在HTTP响应报文的Header中添加这个信息;客户端收到请求响应后,一旦发现HTTP Header中恢复的分流配置版本号大于本地的,就主动向分流配置平台拉取最新的分流配置。如此一来,分流配置的变更可以达到近实时生效的效果。客户端与服务端获取分流配置的交互如图1-60所示。

当某机房发生内部故障,需要将全部用户切流到另一个机房时(比如切流到昌平机房),分流配置平台可以下发如下配置项:
1 | "api.friendy.com": { |
将昌平机房的DevicelD哈希取模值范围设置为[0, 100),将延庆机房的DevicelD哈希取模值范围设置为[0, 0),保证全部客户端设备都被分流到昌平机房。
客户端分流依赖服务端下发的分流配置,如果发生机房掉电等大面积故障,则会导致接入本机房的客户端无法获取到最新的分流配置。可见,客户端本身也需要有主动容灾的策略:
- 客户端接入A机房后,当连续N次访问A机房均发生网络错误时,客户端猜测A机房已不可用。
- 客户端主动拉取最新的分流配置,此时拉取动作访问的依然是A机房。
- 如果A机房已经掉电,或者机房接入层故障,那么客户端拉取分流配置当然也会失败。
- 客户端转而向此时正常工作的B机房拉取分流配置,得到“将请求全部切流到B机房”的最新分流配置。
- 客户端应用最新的分流配置,其发出的请求全部流入B机房,机房切流完成。
我们也可以使用HTTP DNS实施分流策略:
- 客户端向HTTP DNS发起域名解析请求时携带DevicelD;
- HTTP DNS根据域名的分流配置计算出对应的机房;
- 然后将此机房的一个入口 IP地址返回给客户端,客户端就会接入此机房。
其他接入层技术也都很容易支持机房分流,比如CDN动态加速、公有云机房网关,甚至是使用机房内的Nginx分流,它们的实施思路大差不差,这里不再赘述。
最后需要说明的是,当A机房发生故障时,我们需要做的不一定只有切流到B机房这一件事情,还要看A机房的存储层属性:
- 如果A机房存储层的数据库是从库,那么切流到B机房就好;
- 如果A机房存储层的数据库是主库,B机房存储层的数据库是从库,那么切流到B机房会造成写数据请求无法执行。所以,我们还需要将B机房的所有存储数据库提升为主库。
1.13.4 两地三中心
“同城双活”架构大大提升了机房的高可用性,同时兼顾了机房资源的利用率,它有较好的实用价值。不过,“同城”有一些潜在风险,比如水灾、龙卷风、地震等城市级自然灾害会让距离相近的两个机房全军覆没,机房高可用性保障似乎做得还不够好。于是,业界的一些公司提出了 “两地三中心”架构方案来优化“同城双活”。
在正式介绍这个架构方案之前,笔者希望分享一下自己的看法。诚然,城市级自然灾害确实会导致应用彻底瘫痪,但是我们也应该考虑概率问题,即机房所在地遭遇自然灾害的可能性有多大?
在机房的选址上,我们会刻意避开洪涝、龙卷风、地震高发的地带,这就已经使得机房遇到自然灾害的可能性大大降低了。我们在搭建完“同城双活”架构后,再去担忧会不会有百年一遇的自然灾害,然后又花费大量成本去做防御性建设,最终投入产出比往往非常低。在笔者看来,“两地三中心”就是一个投入产出比较低的架构方案,我们简单了解一下它就好。
“两地三中心”架构是在“同城双活”的基础上再增加一个异地备机房,如图1-61所示。
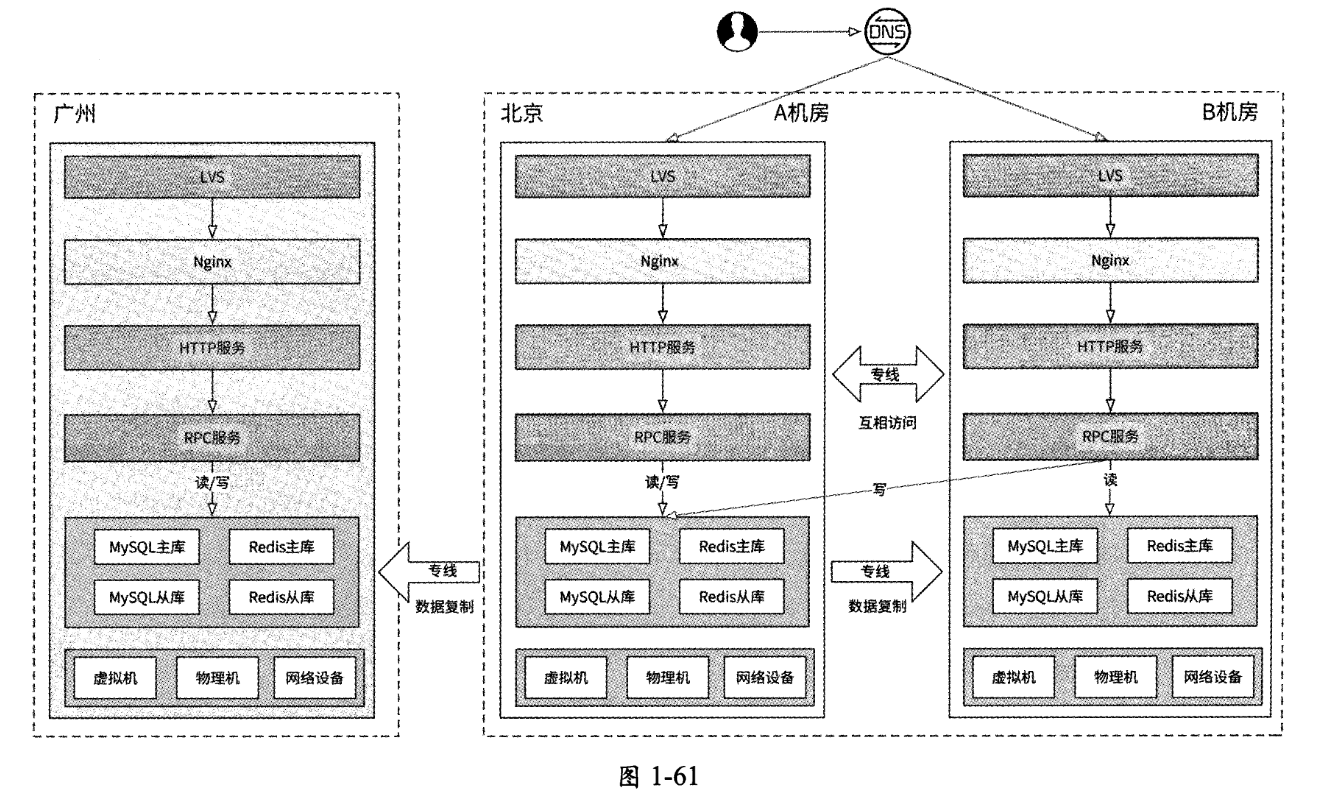
所谓“异地”就是指需要将备机房部署到另一个距离较远的城市,比如“双活”机房在北京,那么备机房可以被部署在广州。备机房只做数据备份,不对外提供服务,所以这种架构方案的问题还是备机房的资源浪费和可用性存疑。




