第2章通用的高并发架构设计——2.7 高并发写场景方案2:异步写与写聚合

第2章通用的高并发架构设计——2.7 高并发写场景方案2:异步写与写聚合
John Yaml数据分片本质上是通过提高系统的可扩展性来支撑高并发写请求的,每当写请求量达到一个新高度时,系统就需要数据分片扩容。从产品发展的角度来讲,这本无可厚非,但是扩容就意味着需要更多昂贵的服务器资源,经济成本较高;况且扩容不是一个实时操作,对临时的突增流量很难及时应对。实际上,我们还可以从业务的角度和数据特点的角度来思考高并发写场景的应对之道,本节就来介绍两种常见的方案:
- 异步写
- 写聚合
2.7.1 异步写
异步写是一个泛化的概念,并不局限于实现形式。异步写把写请求的交互流程从“用户发起写请求并同步等待结果返回”转变为“用户提交写请求后,异步查询结果”的两阶段交互。一般而言,异步写的技术实现有如下特点。
- 将用户写请求先以适当的方式快速暂存到一个数据池中,然后立刻响应用户,告知其请求提交成功,以便缩短写请求的响应时间。
- 真正的写操作由后台任务不断地从数据池中读取请求并真正执行。
- 写操作结果依靠用户主动查询,有的业务场景为了提高实时性,也会在写操作执行完成后王动将结果通知给用户。
异步写非常适合写请求量大,但是被请求方的系统吞吐量跟不上的场景——写请求先排队,被请求方以正常的速度处理请求,就像火车检票口一样。接下来列举几个场景介绍异步写的实现。
(1)跨公网调用
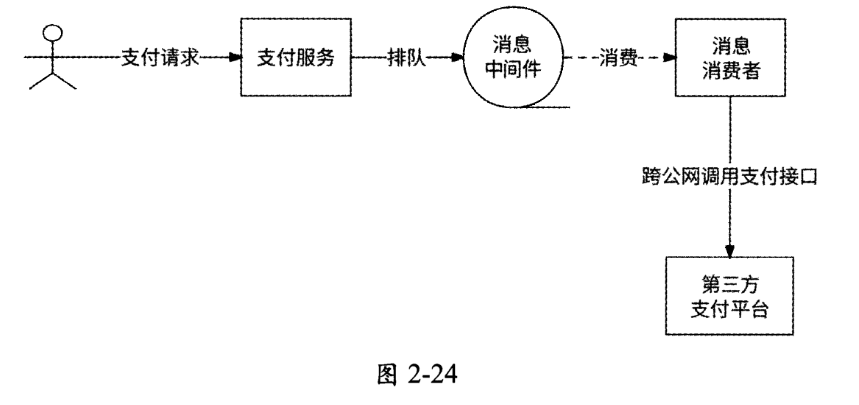
某电商类产品接入微信支付、支付宝等渠道来做支付功能,这些渠道都属于第三方平台,即不属于本产品的后台服务,这就意味着需要跨公网调用第三方平台的支付接口。而公网调用的网络耗时和网络抖动很严重,同时大量的用户支付请求到来会导致跨公网调用发生阻塞。由于跨公网调用的速度无法匹配支付请求的速度,所以使用异步写方案可以很好地解决问题。如图2-24所示,使用消息中间件对用户支付请求进行排队操作,并通过消息消费者不断地消费用户支付请求,逐个跨公网调用第三方平台的支付接口。
(2)秒杀系统异步化
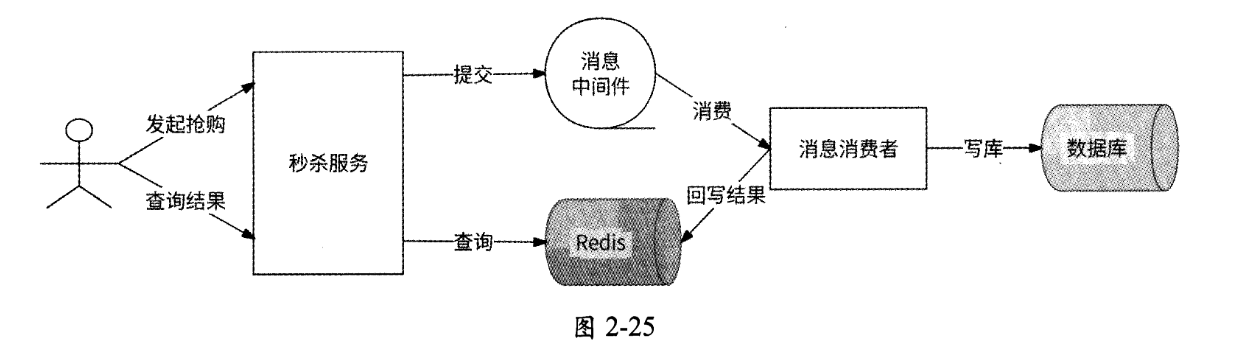
在产品秒杀活动中,对于某电商产品,在同一时间会有大量的用户抢购请求涌入服务器,如果每个请求都直接访问数据库进行扣减库存和写入订单的操作,那么数据库将会承受巨大的压力。我们可以通过异步写方案将抢购动作变成异步形式:
- 用户点击“抢购”按钮,秒杀服务将抢购请求提交到消息中间件,而后立即响应用户——“抢购中”;
- 消息消费者按照数据库的真实处理能力,低频甚至串行地消费抢购请求并交给数据库处理;
- 数据库处理请求完成后,将处理结果保存到Redis中;
- 用户可以刷新订单页向Redis查询抢购结果。
秒杀系统的异步化架构大致如图2-25所示。
2.7.2 写聚合
写聚合将若干写请求聚合为一个写请求,减少了写请求量。这种方案比较简单、易懂,业界也有较多的应用场景,这里举两个例子。
(1)Kafka Producer 批量生产
为了提升消息生产者(Producer)的消息发送性能,消息中间件Kafka提供了Micro-Batch概念。Micro-Batch提供了一个名为RecordAccumulator的消息收集器,它会将Producer待发送的消息暂存在内存中,并将相同Topic、相同Partition的消息聚合为一个批次,然后一次性发送到Kafka集群,大大提高了 Kafka发送消息的吞吐量。
(2)AliSQL热点数据优化
由于行锁的存在,在数据库中处理热点数据更新一直是一个难题。对某行热点数据的多个更新请求会相互竞争同一个行锁,性能一直难以得到提升。阿里云深度定制的MySQL分支AliSQL对热点数据更新有专门的优化:将对同一行的多个更新操作聚合为一个批次更新操作,消除了行锁竞争,提高了热点数据的更新效率。
本章小结
本章介绍了高并发架构设计的常用技术方案。
一个系统设计是否满足高并发架构并不是简简单单地看它能承受的QPS是多少。高并发系统有3个可量化的重点指标:
- 高可用性(99.95%的时间可用)
- 高性能(平均响应时间小于200ms,PCT99小于1s)
- 可扩展性(可扩展性大于70%)
高可用性反映了系统可以提供可靠服务的时间,高性能反映了系统吞吐量,而可扩展性反映了系统的韧性。
高并发场景可以分为高并发读场景和高并发写场景。在面对这两种场景时,高并发架构设计往往有不同的思路。
对于高并发读场景来说,可以通过数据库读/写分离、本地缓存、分布式缓存等方案来解决问题。
- 数据库读/写分离方案依赖数据库主从复制机制,并需要格外注意主从延迟问题。
- 本地缓存方案使用服务器本地内存空间来换取网络调用时间,并可以使用如LFU、 LRU、W-TinyLFU等缓存淘汰策略来防止滥用本地内存;同时可以使用类似于SingleFlight的机制来解决缓存击穿问题。
- 分布式缓存方案使用Redis实现,可以通过先更新数据库再删除缓存的方式来保证数据库与缓存数据的最终一致性;同时为了防止缓存失效,需要注意缓存穿透、缓存雪崩等问题。最后我们提出了CQRS模式,用于总结应对高并发读场景的核心思想:读/写分离。
对于高并发写场景来说,可以通过 数据分片、异步写、写聚合等方案来解决问题。
- 采用数据分片(数据库分库分表)将写请求分散到多个数据分区。
- 使用异步写方案,暂时将写请求存储到一个临时缓冲区(典型的代表是消息中间件)
- 还可以按照数据特性对相关的写请求进行写聚合,减少了写请求量。
总结
什么是异步写?
- 异步写是一个泛化的概念,并不局限于实现形式。
- 异步写把写请求的交互流程从“用户发起写请求并同步等待结果返回”转变为“用户提交写请求后,异步查询结果”的两阶段交互。
异步写的技术实现有什么特点。
- 将用户写请求先以适当的方式快速暂存到一个数据池中,然后立刻响应用户,告知其请求提交成功,以便缩短写请求的响应时间。
- 真正的写操作由后台任务不断地从数据池中读取请求并真正执行。
- 写操作结果依靠用户主动查询,有的业务场景为了提高实时性,也会在写操作执行完成后王动将结果通知给用户。
异步写的适用场景?
- 异步写非常适合写请求量大,但是被请求方的系统吞吐量跟不上的场景
什么是写聚合?
- 写聚合将若干写请求聚合为一个写请求,减少了写请求量。




