第2章通用的高并发架构设计——2.6 高并发写场景方案1:数据分片之数据库分库分表

第2章通用的高并发架构设计——2.6 高并发写场景方案1:数据分片之数据库分库分表
John Yaml数据分片是指将待处理的数据或者请求分成多份并行处理。在现实生活中,有很多与数据分片思想一致的场景,例如:
- 为了减少患者与家属的排队时间,医院会开通多个挂号/收费窗口;
- 为了提高乘客进站的速度,人流量大的火车站、地铁站会设置多个闸机口,同时为乘客检票。
互联网应用在应对高并发写请求的架构设计中,数据分片也是一种常用方案。数据分片有多种表现形式,其中被广泛提及的是数据库分库分表。由于数据库分库分表已经可以充分体现数据分片的主要技术要素,所以本节会以数据库分库分表形式为主、其他数据分片形式为辅展开介绍。
2.6.1 分库和分表
数据库的分库和分表其实是两个概念:
分库指的是将数据库拆分为多个小数据库,原来存储在单个数据库中的数据被分开存储到各个小数据库中;
分表指的是将单个数据表拆分为多个结构完全一致的表,原来存储在单个数据表中的数据被分开存储到各个表中。
由于数据库的分库操作和分表操作一般会同时进行,所以通常将它们合并在一起称为“数据库分库分表”。
大部分互联网应用都绕不开数据库分库分表,因为随着业务的不断发展和用户活跃度的提高,数据库会面临诸多挑战。
- 数据量大:当业务发展到一定阶段时,数据库中已存储了海量的存量数据,每个数据表中都存储了千万行甚至上亿行数据,业务方对数据表执行SQL语句时扫描的数据行增多,性能开销被严重放大。以MySQL数据库为例,如果单个数据表中的数据量超过2000万行,则会导致表结构B+树的层级增多,数据读/写的磁盘I/O操作次数增加。此外,在涉及数据表结构修改的场景下,DDL语句执行完成消耗的时间令人难以接受。为了解决单表的读/写效率问题,一般会进行分表操作。
- 并发量大:海量用户访问单个数据库,很快会达到数据库处理能力的上限,无论是数据库的最大请求连接数、CPU资源、内存资源还是网络带宽均有可能成为性能瓶颈。为了解决数据库性能问题,一般会进行分库操作。
分库和分表的目的:
- 分库的目的是充分利用多台服务器资源
- 分表的目的是提高一台服务器的单数据库处理能力
接下来讨论怎样做分库分表。在拆分维度上,分库分表可以分为两类:
- 垂直拆分(侧重基于业务拆分)
- 水平拆分(侧重基于数据拆分)
2.6.2 垂直拆分
垂直拆分包括垂直分库与垂直分表。
垂直分库指的是按照业务归属将单个数据库中的数据表进行分类,与不同业务相关的数据表被拆分到不同的数据库中,其核心是“专库专用”。以电商产品为例,在业务起步时期,为了快速上线,可能使用单个数据库存储商品表、物流表、商家表、订单表;当业务达到一定量级时,再按照电商业务维度垂直拆分出商品库、物流库、商家库、订单库,如图2-10所示。
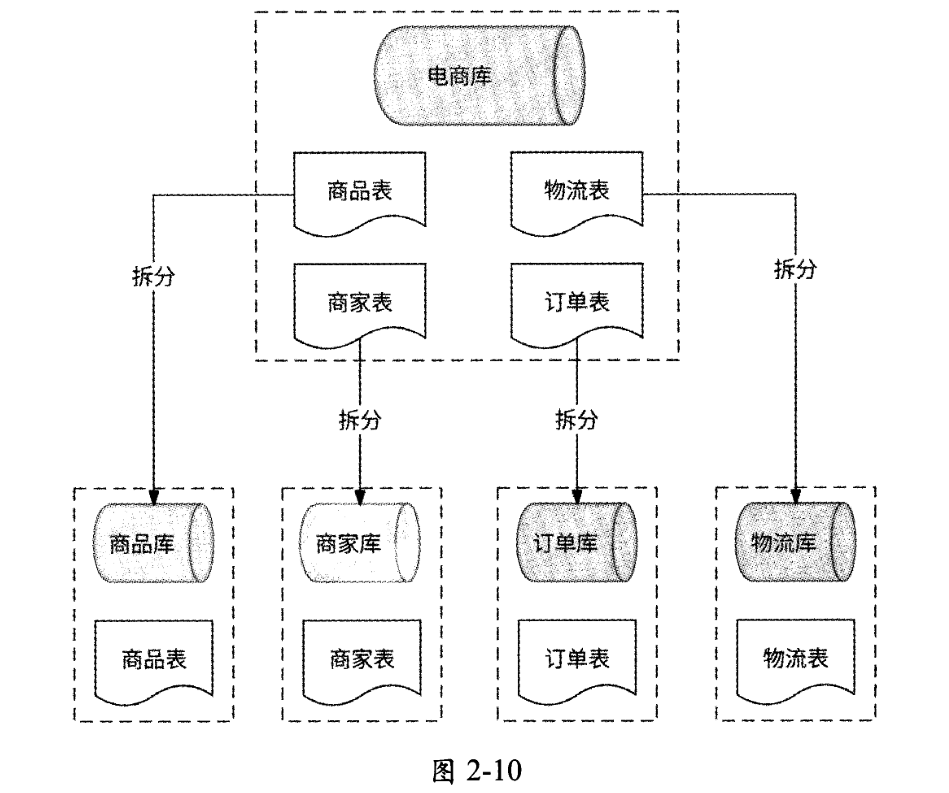
垂直分库可以实现不同业务归属的数据解耦,将不同业务数据交给各业务研发团队独立维护,有效保证了各团队的职责单一。在高并发场景下,由于垂直分库使用不同的服务器维护不同业务的数据库,数据库并发量得到一定程度的提升。
垂直分表指的是将一个数据表按照字段分成多个表,每个表存储其中一部分字段。分表的依据可以是字段被频繁访问的频率、字段值大小等。还是以电商产品为例,最初的商品表可能有名称、商品图片、价格、限购数、商品描述、售后说明等字段,但是这些字段的曝光率有较大的差距:在用户搜索商品、商品推荐或商家全部商品列表等高频访问场景下,仅需要名称、商品图片和价格字段,而限购数、商品描述和售后说明字段仅在用户点击进入商品详情页后才会被读取,而且商品描述和售后说明字段的值比较大,于是商品表可以被垂直拆分为商品基本信息表和商品详情表,如图2-11所示。
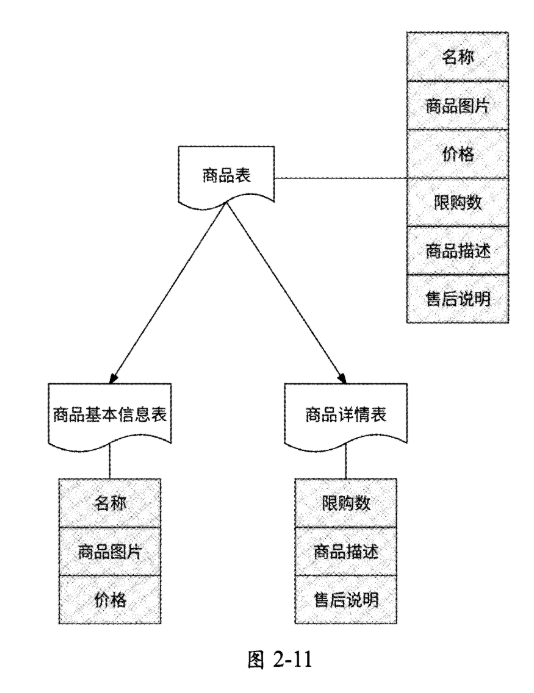
垂直分表可以很好地隔离核心数据和非核心数据。数据库是以行为单位将数据加载到内存中的,通过垂直分表拆分以后核心数据表的字段大多访问频率较高,且字段值也都较小。因此可以将更多的数据加载到内存中,来提高查询的命中率,减少磁盘I/O,以此来提升数据库性能。不过,垂直分表仅适合数据量不大但字段较多的数据存储场景。由于拆分后各表的数据行没有变化,因此垂直分表并没有消除单表数据量过大的问题。
2.6.3 水平拆分
水平拆分包括水平分库与水平分表。
水平分库是指将同一个数据库中的数据按照某种规则拆分到多个数据库中,这些数据库可以被部署在不同的服务器上。并且每个数据库拥有哪些表以及每个表的结构都与拆分前的数据库完全一致。
如图2-12所示,以存储已注册用户的“用户库”为例,将“用户库”水平拆分为3个数据库:
- 用户库-1
- 用户库-2
- 用户库-3
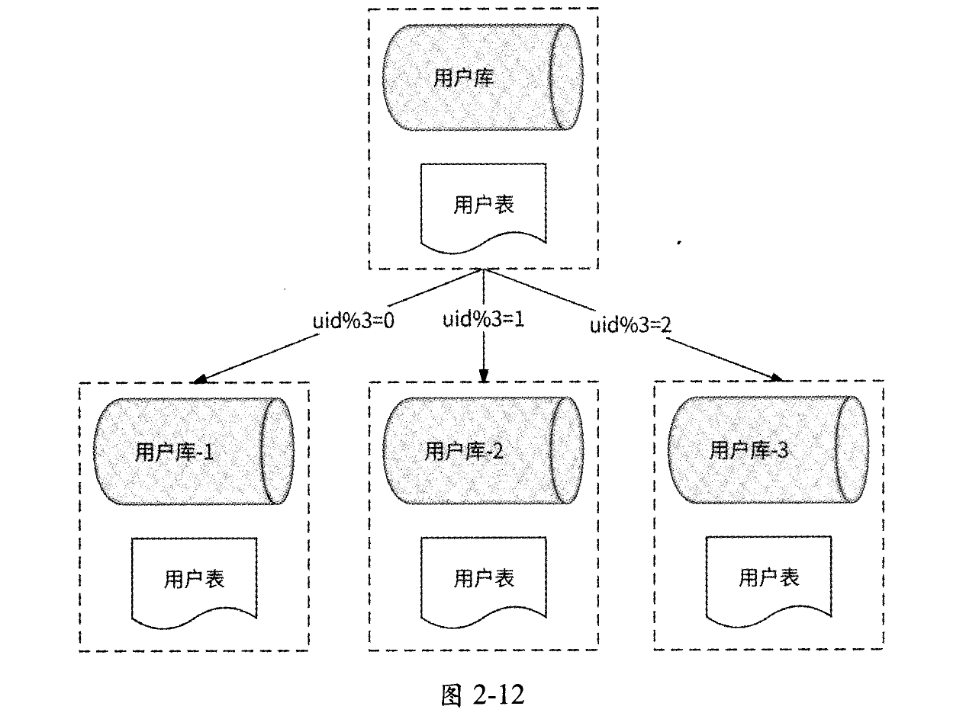
这3个数据库内有完全相同的“用户表”。对于一条用户数据,按照uid(用户ID)与3取模的结果来决定将其拆分到哪个数据库中。水平分库通过利用多服务器资源充分提高了数据库并发处理能力,且拆分后每个数据库内的单表数据量也得到了有效控制。
水平分表是指在同一个数据库内,将一个数据表中的数据按照某种规则拆分到多个表中,每个表的结构都与拆分前的表完全一致。如图2-13所示,还是以“用户库”为例, 在“用户库”中将“用户表”拆分为3个结构一样的表:
- 用户表-1
- 用户表-2
- 用户表-3
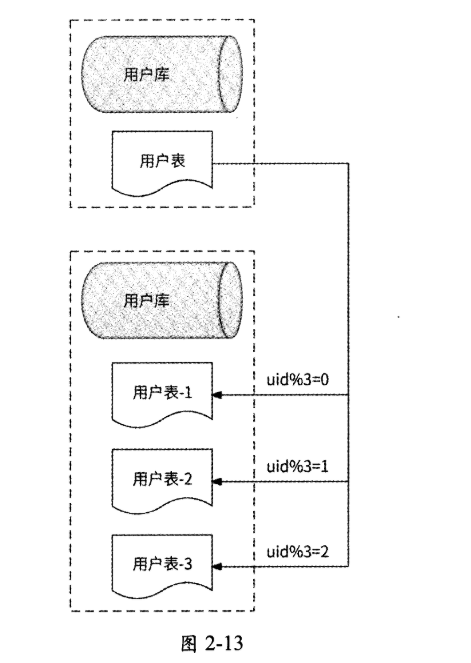
对于一条用户数据,同样按照uid(用户ID)与3取模的结果来决定将其拆分到哪个表中。
水平分表解决了单表数据量过大的问题。但是由于拆分后的表还在同一个数据库中,所以依然在竞争同一台服务器的请求连接数、CPU、内存、网络带宽等资源。为了进一步提升数据库性能,水平分表还可以结合水平分库,即“水平分库分表”,将拆分后的表分散到不同的数据库中,达到分布式效果,如图2-14所示。
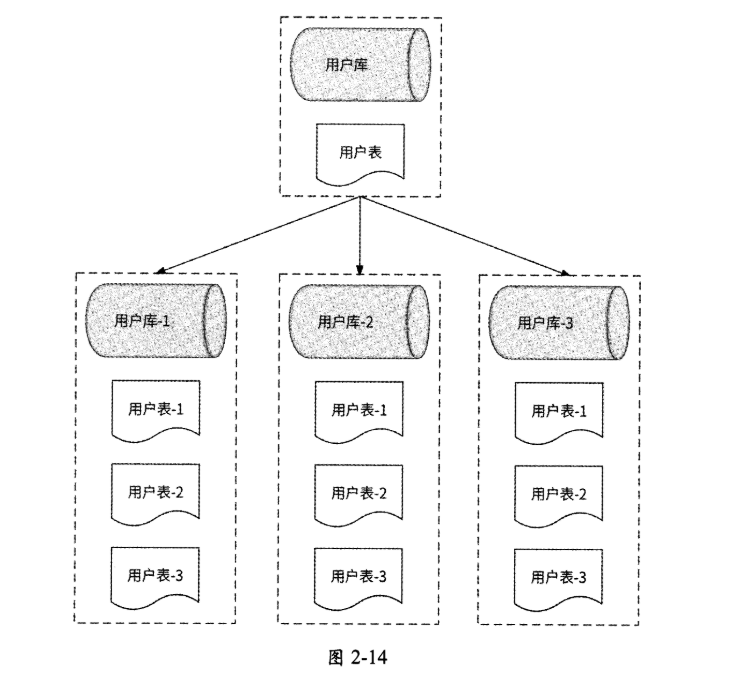
水平分库使数据库拥有分布式能力,水平分表使数据量过大的单表SQL语句的执行效率得到提升,我们可以根据业务需要来选择是水平分库、水平分表还是水平分库分表。
- 如果在业务场景中用户并发量很大,但是数据量较小,则可以只选择水平分库, 不选择水平分表。
- 如果在业务场景中用户并发量很小,但是数据量较大,则可以不选择水平分库, 只选择水平分表。
- 如果在业务场景中用户并发量很大,数据量也很大,则可以选择水平分库分表。
2.6.4 水平拆分规则
在2.6.3节中提到按照某种规则水平拆分,并以取模运算作为示例。实际上,水平拆分规则是指数据路由算法,用于决定一条数据应该被拆分到哪个库和哪个表中。更广泛的说法是,一条数据应该被拆分到哪个数据分区。在最理想的情况下,数据路由算法应该保证每个分区有均等的数据量和数据读/写请求量。
- 如果某个数据分区存储的数据量远大于其他数据分区,我们就称此情况为“数据偏斜”;
- 如果某个数据分区的读/写请求量远大于其他数据分区,我们就将这个数据分区称为“数据热点”。
一种适合的数据路由算法应该避免出现数据偏斜与数据热点。接下来介绍几种常见的数据路由算法。
(1)范围分区法
将数据以可排序字段值的区间为依据进行数据分区,比如数据唯一ID、数据创建时间等。
例如,如图2-15所示,按照数据创建时间将每半年作为一个区间进行数据分区:
- 将2020年7月至12月的数据存储到数据库DB1中
- 将2021年1月至6月的数据存储到数据库DB2中
- 将2021年7月至12月的数据存储到数据库DB3中
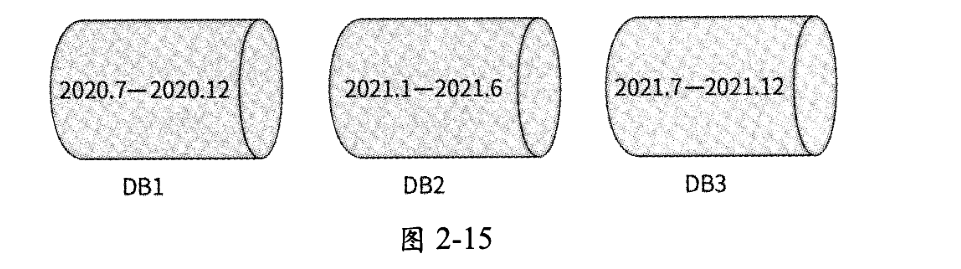
按照数据唯一ID进行数据分区同理。
范围分区法可以很方便地支持分区查询,比如上面的例子,可以轻松地得到某个月所有的数据。另外,范围分区法对分区扩容很友好,比如增加数据分区时,只需要设置更多的数据范围,而基本上不会变更已有的分区数据范围。
但是,范围分区法是否可以保持各数据分区的数据量均匀分布非常依赖分区字段的属性。
- 如果分区字段有自增属性,比如“用户表”使用用户id作为分区依据,那么由于用户id自增,每个分区保持范围等长即可保证数据量的均匀分布;
- 而如果“用户表”使用用户昵称这种具有随机性质的字段作为分区依据,那么由于用户昵称的值随机,每个分区的范围长度可能不同,即数据分区之间难以保证数据量的均匀分布,容易造成数据偏斜。
此外,如果使用带有时间属性的字段作为分区依据,数据范围是近半年的数据分区的读/写频率更高,则容易出现数据热点。
(2)哈希分区法
为了防止出现数据偏斜与数据热点的问题,很多分布式存储系统都会采用哈希函数来确定数据分区。最简单的哈希分区法是取模法:先计算出所选数据字段的哈希值,再与数据分区数目N取模,即hash()%N,取模结果对应数据分区0~N-1。此方法最大的优势是实现简单,但是对于数据分区扩容缺少灵活性,一旦数据分区数目N有变化,所有的数据就都需要重新分区。更好的做法是与对数据分区扩容友好的范围分区法相结合,即对哈希值进行范围分区,每个数据分区接收哈希值在指定范围内的数据,如图2-16所示。
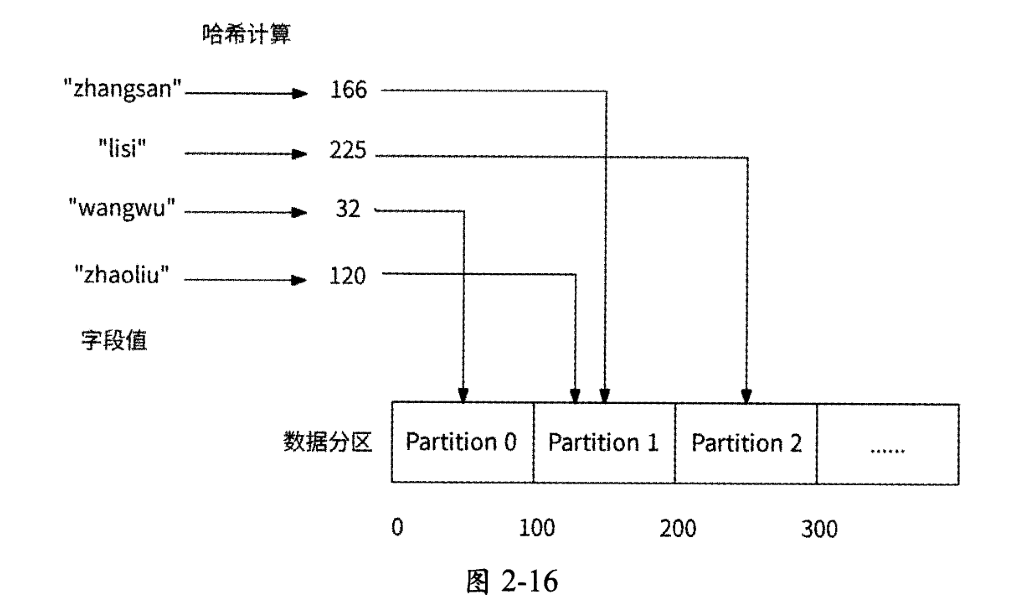
哈希分区法的优势是无视数据字段属性,无论是自增属性还是随机字符串,均可以通过哈希函数转化为数字;而且,使用优秀的哈希函数可以使数据量均匀分布,在很大程度上避免了数据偏斜与数据热点的出现。
(3)一致性哈希分区法
一致性哈希分区法最重要的结构是哈希环,如图2-17所示,数值$[0, 2^{32}-1]$作为$2^{32}$个节点依次排列在哈希环上并首尾相连。
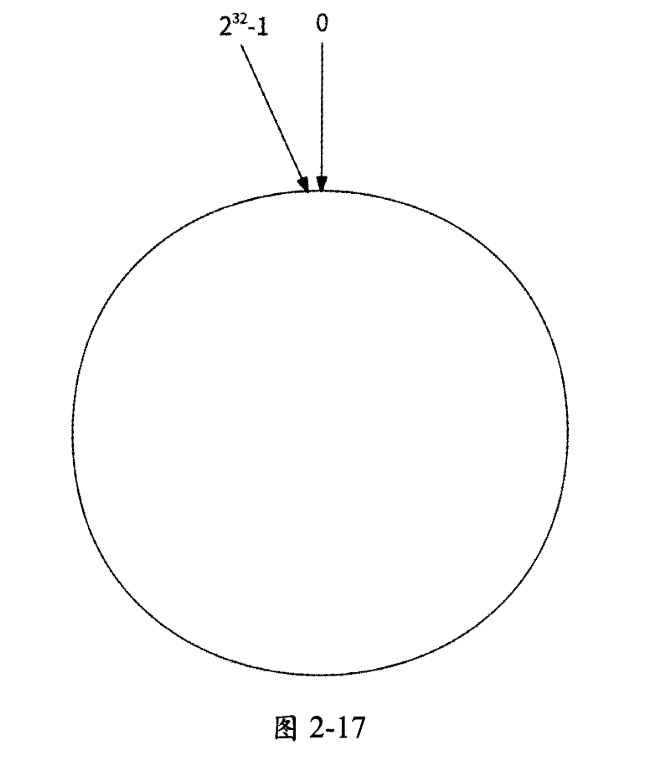
哈希环维护了每个哈希值与其数据分区的路由关系。
每个数据分区都通过哈希计算,所得到的哈希值与$2^{32}$取模后被映射到哈希环的某个节点。
每条数据都以某个字段进行哈希计算,所得到的哈希值也与$2^{32}$取模后被映射到哈希环的某个节点,然后从这个节点出发,在哈希环上顺时针查找到的第一个数据分区节点负责存储此数据。如图2-18所示,数据data 1和数据data 2被分配到数据分区Partition 2,数据data 3被分配到数据分区Partition 4。
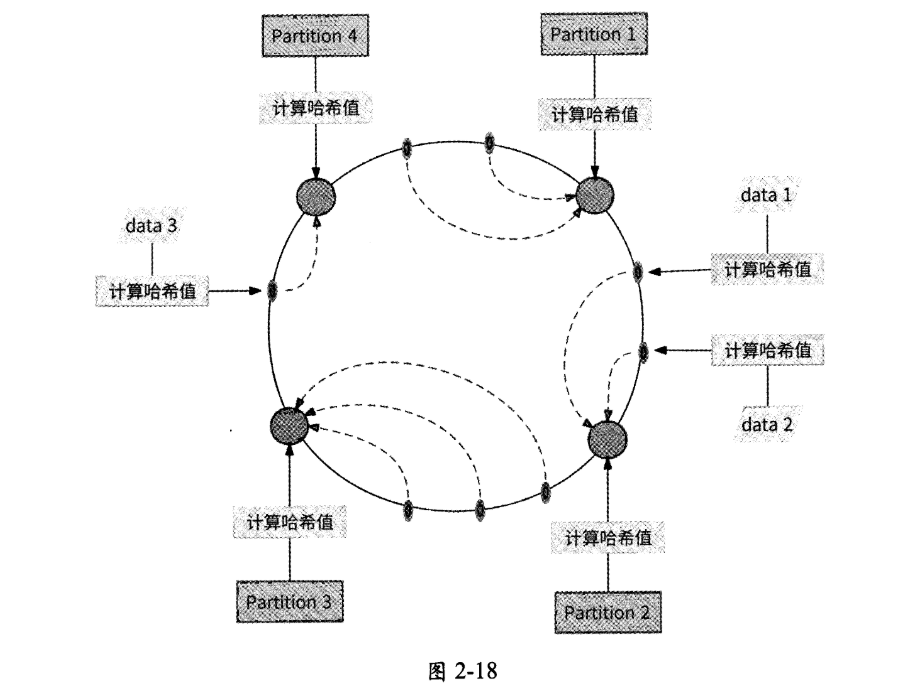
一致性哈希分区法最主要的优点是,当增加或移除一个数据分区时,只有其在哈希环上逆时针相邻的数据需要重新分区。比如图2-18中的数据分区Partition 4被移除后,只有其原本存储的数据data 3需要被迁移到新的数据分区Partition 1,其他数据不会受到影响。
由于一致性哈希分区法并不指定每个数据分区的哈希值范围,所以数据分区在哈希环上分布越均匀,各个数据分区的数据量就越均衡。但是,当数据分区较少时,有很大的可能是它们在哈希环上的分布较为集中,进而造成数据偏斜,如图2-19所示。
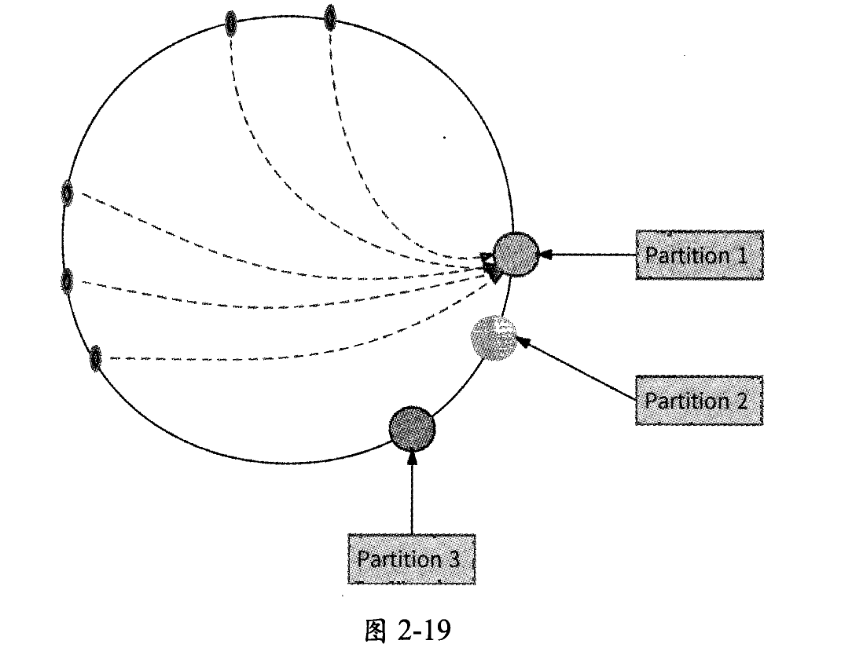
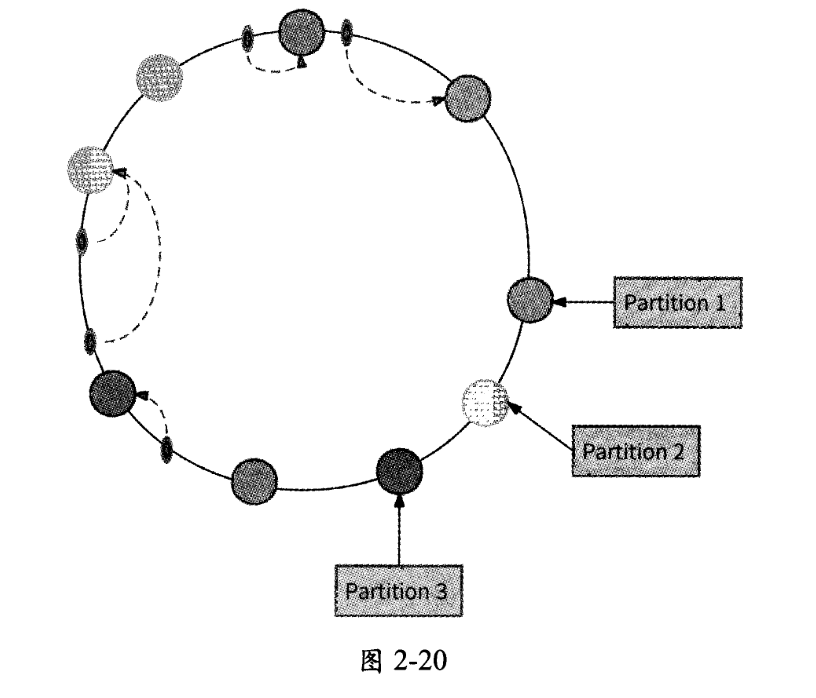
从图2-19中可以看出,由于3个数据分区的分布较为集中,所以产生了数据偏斜问题,Partition 1存储的数据量远远大于Partition 2和Partition 3。为了避免出现这种情况,一致性哈希分区法引入了虚拟节点机制。对于每个数据分区,计算出多个哈希值,每个计算结果都被放置到哈希环的对应节点上,这些节点被称为“虚拟节点”。一个实际的数据分区可以对应多个虚拟节点。通过虚拟节点机制可以将数据分区数目放大,数据分区对应的虚拟节点越多,哈希环上的节点就越多,它们也更容易在哈希环上均匀分布,数据偏斜的影响就会越来越小。如图2-20所示的是每个数据分区有3个虚拟节点的哈希环映射情况。
2.6.5 扩容方案
当某个分库承载的数据量或请求量远高于其他分库,或者现有的分库分表架构的数据量已经趋于饱和时,都需要进行扩容操作。这里推荐的平滑扩容方案是从库升级法。
我们先来介绍单个分库的扩容步骤。如图2-21所示,假设某数据库被拆分为3个库和6个表,各个分库存储的数据范围分别为
- r0~r1
- r1~r2
- r2~r3
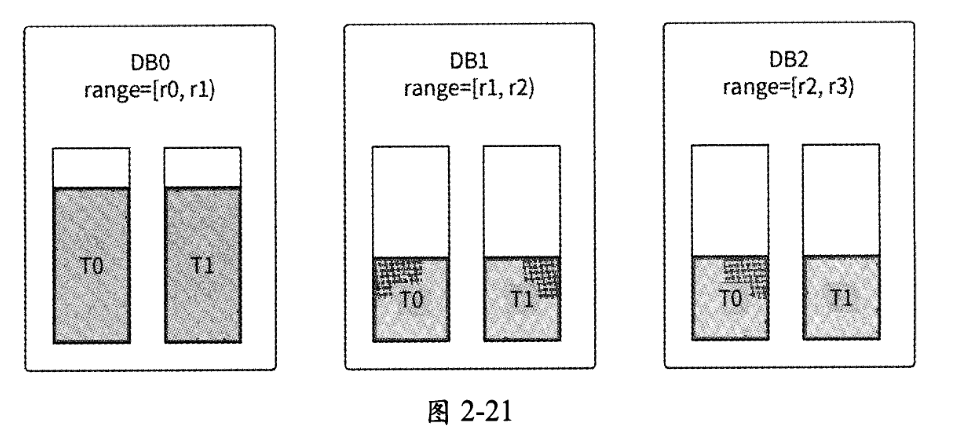
此时分库DB0的数据量和资源压力过大。
使用从库升级法对DB0分库扩容的步骤如下。
- 为DB0增加Slave节点(即从库),开始主从复制操作,将DB0的数据同步到从库。这一步不一定需要专门来做,因为在常见的数据库分库分表方案中,分库都会使用主从复制架构来保证每个分库高可用,从库是本来就存在的。
- 主从复制完成后,DB0主库临时封禁写请求操作,保证不再有增量数据。
- 检查主从库数据,如果数据完全一致,则表示数据已经完全被同步到从库,此时断开主从关系。
- 修改DB0的数据范围为r0~(r0 + r1) / 2,即DB0负责原来数据范围的前一半。
- 将DB0从库提升为主库并命名为DB3,同时设置数据范围为(r0 + r1) / 2~r1,即DB3负责原DB0数据范围的后一半。
- 确认上游业务均已感知到分库数据范围的变更后,解封DB0的写请求操作,此时分库扩容已经完成,业务已经恢复正常写数据库。
- 启动离线任务,将DB0和DB3的数据范围外的另一半冗余数据删除,最终DB0被扩容为图2-22所示的分库。
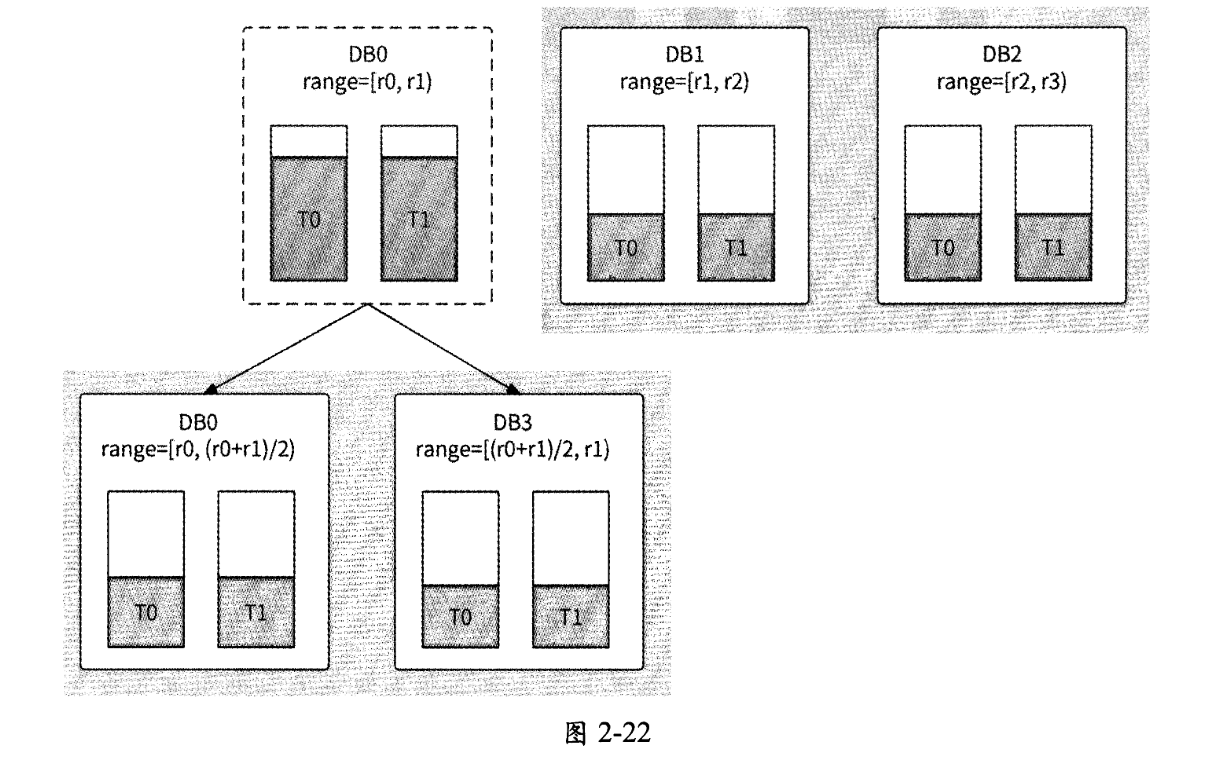
对整个数据库基于从库升级法扩容时,分库数量会翻倍,所以这种扩容方式也被称为“翻倍扩容法”。其扩容步骤与单个分库的扩容步骤类似,只不过是对每个分库都执行从库升级。
- 对于每个分库增加从库,开始主从复制操作。同样,这一步不一定需要做。
- 各分库主从复制完成后,主库临时封禁写请求操作。
- 检查各分库的主从库数据,如果数据完全一致,则断开全部主从关系。
- 修改原分库的数据范围为原数据范围的前一半。
- 将各分库的从库提升为主库,同时设置其数据范围为原数据范围的后一半。
- 确认上游业务均已感知到分库数据范围的变更后,解封全部分库写请求操作,数据库恢复对外提供服务。
- 启动离线任务,将原分库和新分库的数据范围外的另一半冗余数据删除,最终 DB0和DB1的分库如图2-23所示。
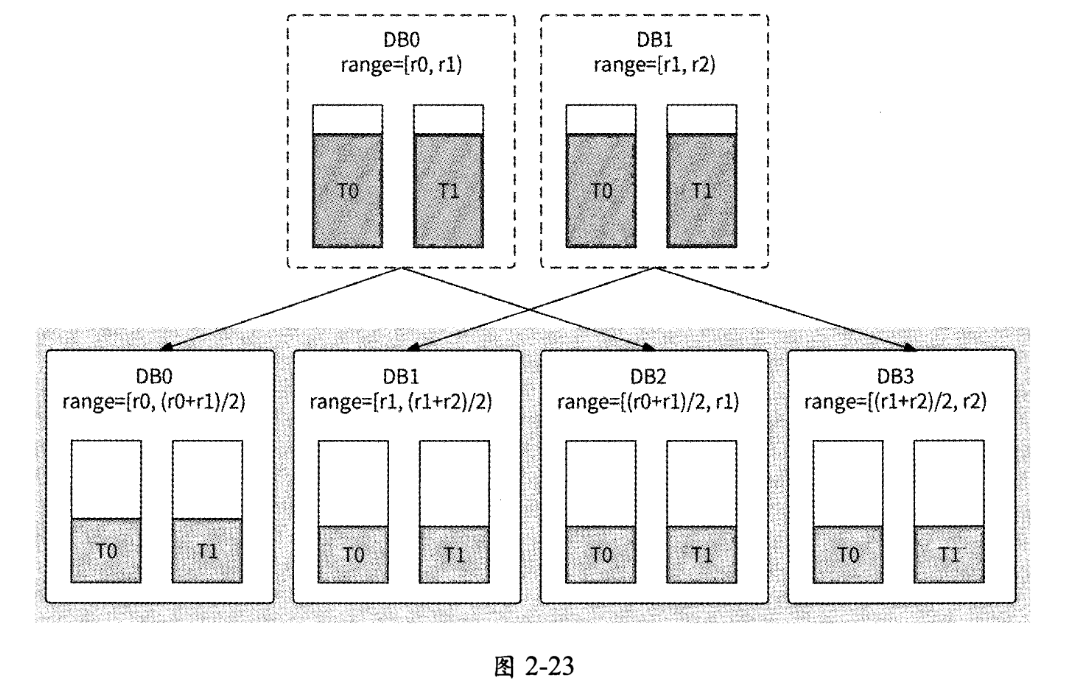
2.6.6 其他数据分片形式
除数据库分库分表之外,数据分片还有其他形式,这里再举3个例子。
(1)Kafka多Partition
在消息中间件Kafka中,以Topic区分不同的消息类型,每个Topic都可以被认为是一个逻辑上的消息队列。在Topic内部物理组成上,消息队列被拆分为多个Partition,每个Partition对应一个独立的日志文件被存放在不同的服务器上。Kafka在向一个Topic发送消息时,实际上是在并行写入Partition,一个Topic的Partition数目越多,越能增加这 个Topic的消息写入吞吐量。
(2)秒杀系统分布式锁
电商秒杀系统往往通过分布式锁来保证秒杀时产品不被超卖,但如果某个产品的热度很高,大量秒杀请求并发竞争同一个分布式锁,则会严重拖垮性能。由于分布式锁会造成请求串行化执行,假设一次分布式锁操作耗时20ms,1s最多可以接收50个秒杀请求,那么这对于热门产品来说难以接受。
对于这种情况,优化思路也是数据分片:将产品库存拆分为N份,每份库存使用单独的分布式锁保护,而每个秒杀请求仅争抢其中的一份库存。
例如,现有1000台iPhone手机,我们将库存拆分为20个分段(将分段命名为seg-0 ~ seg-19,每个分段有50个库存)。同时创建20个分布式锁(命名为iphone-lock-0 ~ iphone-lock-19)分别保护这些分段;当秒杀请求到来时,将请求用户ID与20取模得到值Z,尝试竞争分布式锁iphone-lock-z并扣减分段seg-z的库存。20个分布式锁支持20个秒杀请求并行加锁,这样一来,即使加锁耗时20ms,秒杀系统1s也能接收50 x 20 = 1000个秒杀请求。
(3)ConcurrentHashMap
ConcurrentHashMap是JDK内置的线程安全的HashMap,它并不会对整个HashMap加锁以保证线程安全,而是将其内部数据拆分到多个槽,为每个槽独立加锁,于是对这些槽可以并发读/写。这样的做法减少了线程间竞争,提高了HashMap的读/写性能。
总结
什么是数据分片?
- 数据分片是指将待处理的数据或者请求分成多份并行处理。
什么是数据库的分库分表?
分库指的是将数据库拆分为多个小数据库,原来存储在单个数据库中的数据被分开存储到各个小数据库中;
分表指的是将单个数据表拆分为多个结构完全一致的表,原来存储在单个数据表中的数据被分开存储到各个表中。
分库和分表的目的是啥?
- 分库的目的是充分利用多台服务器资源
- 分表的目的是提高一台服务器的单数据库处理能力
在拆分维度上,分库分表可以分为哪两类?
- 垂直拆分(侧重基于业务拆分)
- 水平拆分(侧重基于数据拆分)
什么是垂直分库?
- 垂直分库指的是按照业务归属将单个数据库中的数据表进行分类,与不同业务相关的数据表被拆分到不同的数据库中,其核心是“专库专用”。
什么是垂直分表?
- 垂直分表指的是将一个数据表按照字段分成多个表,每个表存储其中一部分字段。
垂直分表的依据?
- 字段被频繁访问的频率
- 字段值大小
什么是水平分库?
- 水平分库是指将同一个数据库中的数据按照某种规则拆分到多个数据库中,这些数据库可以被部署在不同的服务器上。
- 并且每个数据库拥有哪些表以及每个表的结构都与拆分前的数据库完全一致。
什么是水平分表?
- 水平分表是指在同一个数据库内,将一个数据表中的数据按照某种规则拆分到多个表中,每个表的结构都与拆分前的表完全一致。
如何根据业务需要来选择是水平分库、水平分表还是水平分库分表呢?
- 如果在业务场景中用户并发量很大,但是数据量较小,则可以只选择水平分库, 不选择水平分表。
- 如果在业务场景中用户并发量很小,但是数据量较大,则可以不选择水平分库, 只选择水平分表。
- 如果在业务场景中用户并发量很大,数据量也很大,则可以选择水平分库分表。
什么是水平拆分规则?
- 水平拆分规则是指数据路由算法,用于决定一条数据应该被拆分到哪个库和哪个表中。更广泛的说法是,一条数据应该被拆分到哪个数据分区。
什么是 数据偏斜 和 数据热点?
- 如果某个数据分区存储的数据量远大于其他数据分区,我们就称此情况为“数据偏斜”;
- 如果某个数据分区的读/写请求量远大于其他数据分区,我们就将这个数据分区称为“数据热点”。
什么是范围分区法?
- 将数据以可排序字段值的区间为依据进行数据分区,比如数据唯一ID、数据创建时间等。
常见的数据路由算法有哪些?
- 范围分区法
- 哈希分区法
- 一致性哈希分区法




