第2章通用的高并发架构设计——2.5 高并发读场景总结:CQRS

第2章通用的高并发架构设计——2.5 高并发读场景总结:CQRS
John Yaml无论是数据库读/写分离(见2.2节)、本地缓存(见2.3节)还是分布式缓存(见2.4节),其本质上都是读/写分离,这也是在微服务架构中经常被提及的CQRS模式。
CQRS(Command Query Responsibility Segregation,命令查询职责分离)是一种将数据的读取操作与更新操作分离的模式。query指的是读取操作,而command是对会引起数据变化的操作的总称,新增、删除、修改这些操作都是命令。
2.5.1 CQRS的简要架构与实现
为了避免引入微服务领域驱动设计的相关概念,图2-8给出了CQRS的简要架构。
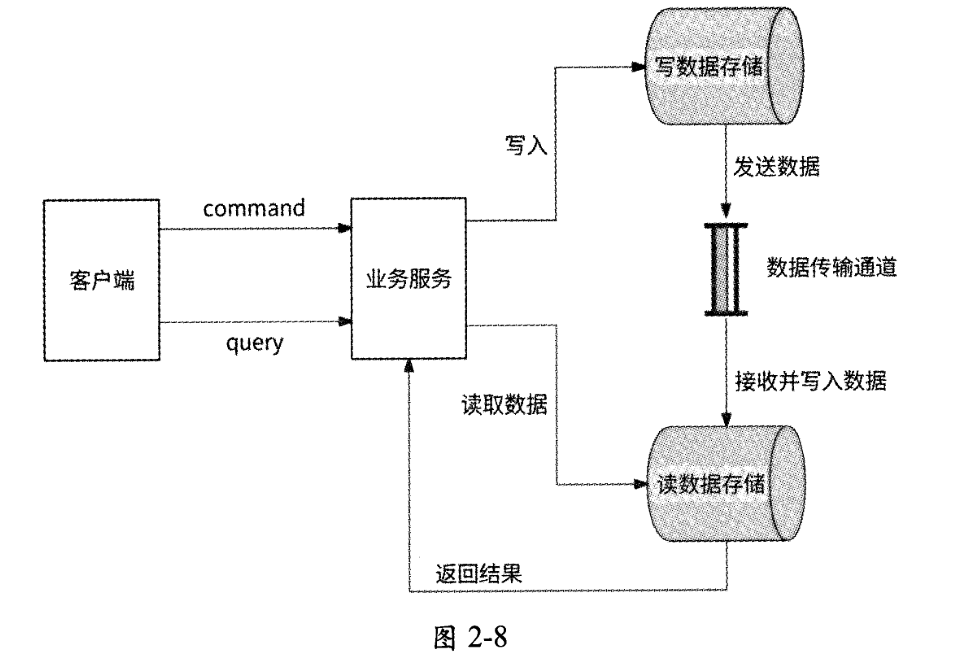
- 当业务服务收到客户端发起的command请求(即写请求)时,会将此请求交给写数据存储来处理。
- 写数据存储完成数据变更后,将数据变更消息发送到消息队列。
- 读数据存储负责监听消息队列,当它收到数据变更消息后,将数据写入自身。
- 当业务服务收到客户端发起的query请求(即读请求)时,将此请求交给读数据存储来处理。
- 读数据存储将此请求希望访问的数据返回。
写数据存储、读数据存储、数据传输通道均是较为宽泛的代称,其中写数据存储和读数据存储在不同的高并发场景下有不同的具体指代,数据传输通道在不同的高并发场景下有不同的形式体现,可能是消息队列、定时任务等。
- 对于数据库读/写分离来说,写数据存储是Master,读数据存储是Slave,消息队列的实现形式是数据库主从复制。
- 对于分布式缓存场景来说,写数据存储是数据库,读数据存储是Redis缓存,消息队列的实现形式是使用消息中间件监听数据库的binlog数据变更日志。
无论是何种场景,都应该为写数据存储选择适合高并发写入的存储系统,为读数据存储选择适合高并发读取的存储系统,消息队列作为数据传输通道要足够健壮,保证数据不丢失。
2.5.2 更多的使用场景
为了加深对CQRS的理解,下面再列举两个使用场景。
(1)搜索场景
很多互联网应用都支持根据关键词搜索用户昵称的功能,例如,用户在微博找人模块中输入关键词“北京”,微博会返回“北京日报” “北京大学” “这里是北京”等账号。这是一个典型的搜索场景。然而,账号信息被存储在数据库中,无法高效应对搜索昵称的业务场景。
这时候就很适合使用CQRS模式,数据库作为写数据存储负责账号信息的管理;而读数据存储应该选择一个在搜索场景中表现优秀的存储系统,比如Elasticsearch,它是基于倒排索引的分布式搜索系统,很适合作为此业务场景的读数据存储,将搜索用户昵称的请求交给Elasticsearch处理。选定读数据存储和写数据存储后,通过消息中间件为两者建立数据关联:创建一个消费者服务并使用消息中间件监听数据库的binlog数据变更日志,在筛选出用户昵称有更改的日志后,将最新用户昵称更新到Elasticsearch中。
(2)多表关联查询场景
有些业务场景如运营后台需要查询复杂的业务数据,这时就要对数据库进行多表关联查询才能得到完整的数据。SQL多表关联查询join语句的底层实现是效率较低的嵌套循环。如果直接对线上数据库执行join语句,则会严重影响其性能。此外,对线上数据库一般都做了分库分表(参见2.6.1节),无法直接执行join语句。
在这个场景下也非常适合使用CQRS模式,提前将需要多表关联的数据进行聚合计算,并将聚合结果单独存储到一个包含全部关联字段的宽表中,查询时直接读取宽表中的聚合结果,而不用执行join语句。在此场景下应用CQRS模式的架构如图2-9所示, 其中:
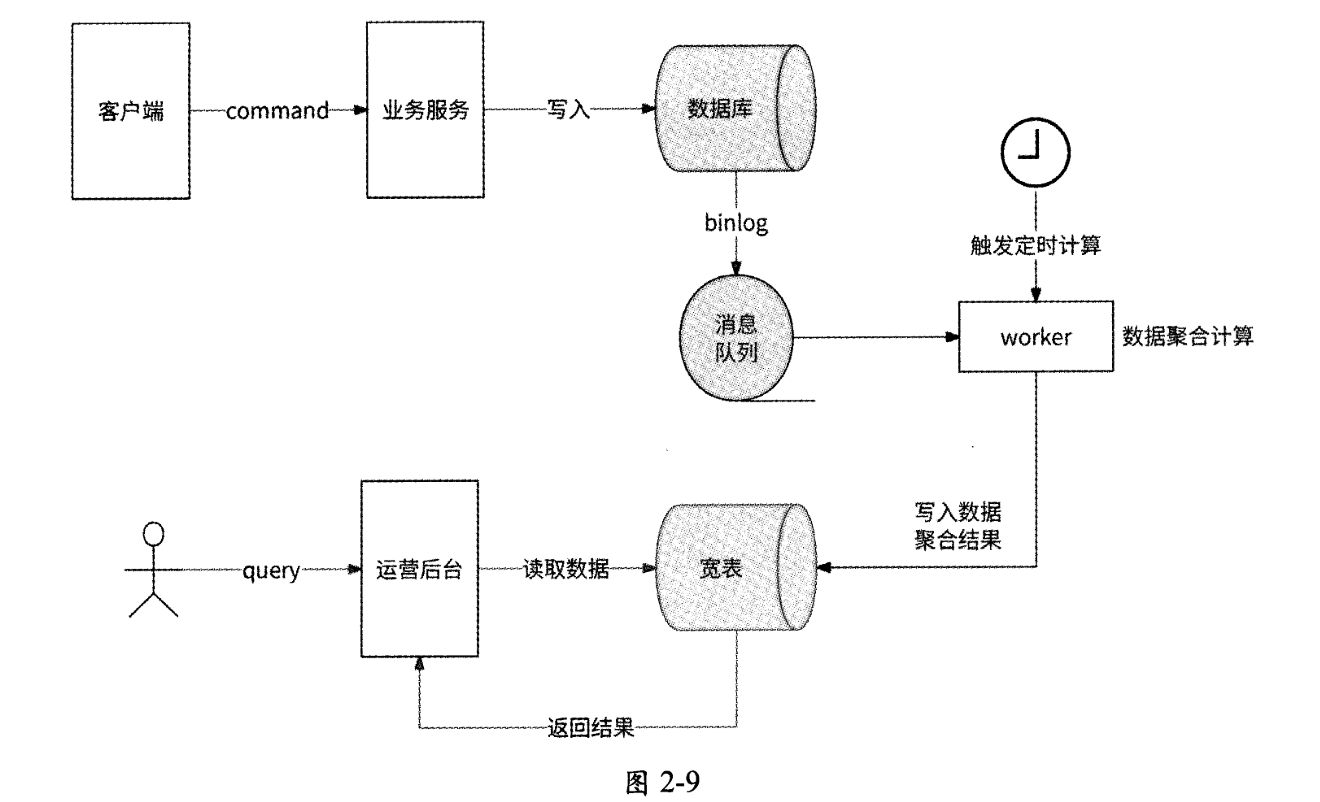
- 数据库为写数据存储;
- 宽表为读数据存储;
- worker为执行数据聚合计算的服务;
- 执行数据聚合计算的时机是数据库有数据变更时,worker服务使用消息中间件监听数据库的binlog数据变更日志,每收到一条数据变更日志就执行一次数据聚合计算。也可以采用定时计算的形式,比如worker每分钟执行一次数据聚合计算。在数据聚合计算完成后,worker将聚合结果写入宽表。
2.5.3 CQRS架构的特点
CQRS架构一般具有如下特点。
- 写数据存储要选用写性能高的存储系统,而读数据存储要选用读性能高的存储系统,所以两者往往有不同的存储模型和存储选型。数据库读/写分离只是一个最简单的特例。
- 读数据有延迟。写数据存储中的数据实时变更,而何时能从读数据存储中获取到最新数据,依赖数据传输通道的传输延迟。无论是消息队列还是定时任务都会带来一定的数据延迟,因此写数据存储和读数据存储仅保证数据的最终一致性。
总结
什么是CQRS呢?
- CQRS(Command Query Responsibility Segregation,命令查询职责分离)是一种将数据的读取操作与更新操作分离的模式。
- query指的是读取操作,而command是对会引起数据变化的操作的总称,新增、删除、修改这些操作都是命令。
CQRS的工作流程?
- 当业务服务收到客户端发起的command请求(即写请求)时,会将此请求交给写数据存储来处理。
- 写数据存储完成数据变更后,将数据变更消息发送到消息队列。
- 读数据存储负责监听消息队列,当它收到数据变更消息后,将数据写入自身。
- 当业务服务收到客户端发起的query请求(即读请求)时,将此请求交给读数据存储来处理。
- 读数据存储将此请求希望访问的数据返回。
CQRS架构的特点有哪些?
- 写数据存储要选用写性能高的存储系统,而读数据存储要选用读性能高的存储系统,所以两者往往有不同的存储模型和存储选型。数据库读/写分离只是一个最简单的特例。
- 读数据有延迟。写数据存储中的数据实时变更,而何时能从读数据存储中获取到最新数据,依赖数据传输通道的传输延迟。无论是消息队列还是定时任务都会带来一定的数据延迟,因此写数据存储和读数据存储仅保证数据的最终一致性。




