第9章排行榜服务——9.3 使用Redis实现排行榜

第9章排行榜服务——9.3 使用Redis实现排行榜
John Yaml9.3 适用Redis实现排行榜
在选定Redis ZSET数据类型后,我们开始一步步分析如何实现一个支持高并发读/写的排行榜服务。
9.3.1 适用Redis ZSET
一个ZSET对象代表一个具体的排行榜,其中存储了用户ID和用户积分。
- Key,排行榜名称,用于区分不同的排行榜。
- Member,存储用户ID,作为排行实体。
- Score,存储用户积分,便于实现按照积分排序的功能。
对于排行榜更新,可以执行ZINCRBY key score member命令,此命令用于向ZSET中的某个Member增加Score。假设ID为999的用户在角逐以千米数为积分的“跑步英雄(run_hero)”排行榜,他在某天跑了 10千米,于是需要执行如下命令为其在排行榜上加10分:
1 | ZINCRBY run_hero 10 999 |
ZINCRBY命令保证:如果member=999不在ZSET run_hero中,则将其作为新成员加入并设置初始score=10;否则,为其已有的Score增加10,正好满足排行榜的要求。
对于排行榜读取,可以使用ZREVRANGE key start top WITHSCORES命令,此命令可以按照Score从大到小的顺序返回Member和对应的Score。其中,start表示从排名为start+1的Member开始查询,top表示到排名为top+1的Member结束查询,WITHSCORES表示展示每个Member对应的积分。获取“跑步英雄”排行榜详情的命令如下:
1 | ZREVRANGE run_hero 0 -1 WITHSCORES |
start=0表示从Score最高的Member开始查询,top=-1表示查询整个ZSET对象。
如果要分页读取排行榜,那么通过start = (当前页数 - 1) × 页大小,top = start + 页大小 - 1就可以实现。假设 “跑步英雄”排行榜以50个用户为一页进行分页展示,那么对于第3页数据,可以通过执行如下命令获取:
1 | ZREVRANGE run_hero 100 149 WITHSCORES |
如果要查询某用户的具体排名,则可以使用ZREVRANK key member命令,此命令会获取指定Member在 ZSET中按照Score从大到小排列的名次。不过,偏移量是从0开始的,所以需要将所获取到的结果加1作为排行榜的名次。需要注意的是,ZREVRANK命令不返回Member的Score。如果需要在查询用户ID=999的排名时获取到他的积分,则只能额外运行一个ZSCORE命令:
1 | ZSCORE run_hero 999 |
使用Redis ZSET结构不仅可以满足排行榜的基本要求,而且Redis性能足够高,一个看似满足高并发读/写的排行榜服务就这么简单地实现了。为什么说“看似”?因为这种方式存在两个问题,即幂等更新和同积分排名处理。
即使要实现周期滚动排行榜也很容易,可以在ZSET Key上插入周期数来区别同一排行榜的不同周期排名。比如“跑步英雄”排行榜是按日来统计的(即“每日跑步英雄”排行榜),那么可以约定将此排行榜的首次上线时间作为起始时间baseTime(如2023年1月1日0点开启“每日跑步英雄”排行榜,时间戳为1672502400),ID为999的用户在完成一次10千米的跑步后,需要根据当前时间计算出需要更新的排行榜周期:
1 | period = (currentTime - 1672502400) / 86400 + 1 |
86400是一天的总秒数,所以计算出的period是自2023年1月1日开始的“每日跑步英雄”排行榜的周期,对应需要更新的ZSET Key为run_hero_{period}。
- 用户在2023年1月1日跑步,需要更新的排行榜ZSET Key为run_hero_0。
- 用户在2023年1月3日跑步,需要更新的排行榜ZSET Key为run_hero_2。
- 用户在2023年2月5日跑步,需要更新的排行榜ZSET Key为run_hero_35。
当用户请求获取某排行榜的详情时,可以使用相同的方式计算出对应的ZSET Key,所以用户可以获取到当前时间所在周期的排行榜。对于分钟、小时、周等其他周期,可以采用类似的处理方式来实现排行榜的滚动。
我们可以看到ZSET数据结构天然适合实现排行榜服务,但是上述实现思路还有两个问题没有考虑,即更新非幂等和同积分用户排名。
9.3.2 幂等更新
直接使用ZINCRBY的缺点是排行榜更新不具有幂等性。如果排行榜服务的上游调用者在更新排行榜时遇到网络超时而选择重试,那么就可能会导致用户积分被重复累计,最终引发其他用户对排行榜公平性的抱怨。
我们可以要求上游调用者为每个更新排行榜的请求都提供一个分布式唯一ID作为请求ID,排行榜服务在收到更新请求后,先在Redis中查询是否已保存此请求ID,如果没有保存,则执行更新排行榜的操作,并将请求ID保存到Redis中,从而实现排行榜更新的幂等性。
对于已更新过排行榜的请求ID,使用String对象保存,其中:
- Key为
{ZSET Key}_{请求ID},即待更新排行榜ZSET Key与请求ID的组合。这样可以防止一个请求在更新排行榜时被幕等性逻辑误判为已执行而过滤掉; - Value可以是任意值。
使用SETNX命令可以实现在Redis中查询请求ID是否存在,如果不存在,则保存。比如“跑步英雄”排行榜:
1 | SETNX run_hero_reqID 0 |
如果一个排行榜写并发较高,那么使用Redis存储全量更新排行榜请求ID会占用大量的存储空间。不过,重复更新请求基本上是上游调用者短时间内的重试请求,这意味着此时即使在Redis中能查询到对应的请求ID,这个请求ID也是最近才被写入的。所以,我们并不需要保存全量请求ID,只需要保存最近一段时间(如10min)的请求ID,也就是为String对象设置10min的过期时间即可。
为了实现使用SETNX命令增加过期时间,将上一个SETNX命令改写如下:
1 | SET run_hero_reqID 0 EX 600 NX |
于是,排行榜服务在处理更新请求时,会请求Redis先执行SET命令,再执行ZINCRBY 命令。需要注意的是,这两个命令的执行需要满足原子性:要么都执行,要么都不执行。如果不满足原子性,则可能出现图9-1所示的情况。
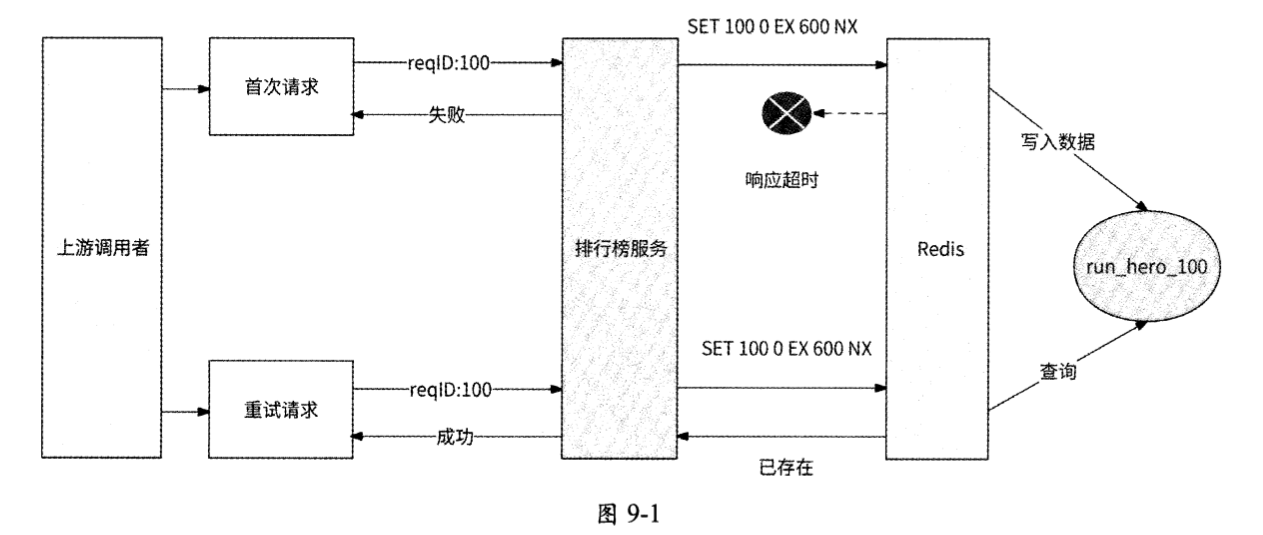
其流程如下:
- 上游调用者请求更新“跑步英雄”排行榜,请求ID为100。这是首次请求。
- 排行榜服务先请求Redis执行SET命令,检查run_hero_100是否存在。
- Redis发现run_hero_100不存在,于是保存此Key。
- Redis在响应排行榜服务时遇到网络抖动,导致响应超时。
- 上游调用者认为更新排行榜请求失败,于是再次发起请求。这是重试请求。
- 排行榜服务同样先请求Redis执行SET命令,检查run_hero_100是否已存在。
- Redis查询到Key为run_hero_100的数据,于是告知排行榜服务。
- 排行榜服务认为此请求已经成功执行,于是为了保证备等性而直接响应上游调用者:已成功更新。
实际上,这个更新请求从未真正更新排行榜,这是因为对于首次更新请求,虽然已经成功在Redis中执行了SET命令,但未执行ZINCRBY命令,从而导致重试请求被误判为已执行而被过滤掉。好在Redis支持运行Lua脚本,我们可以为SET命令和ZINCRBY命令的原子性执行编写如下Lua脚本:
1 | local res = redis.call('SET', KEYS[1] .. '_' .. ARGV[1], '0', 'EX', '3600', 'NX') |
排行榜服务请求Redis在执行此Lua脚本时,传入KEYS={排行榜名称,用户ID},ARGV={请求ID, 新增积分值}来实现排行榜更新的籍等性。
需要说明的是,此时的幂等性并不是真正的幂等性。由于引入了请求ID的过期时间,幂等性被局限为在过期时间内幂等,即上述例子保证的是同一排行榜更新请求在10min内幂等。不过,这种实现虽然不满足严格的幂等性,但是已经可以覆盖大部分重复更新的场景 ,我们可以近似地认为其满足幂等性。
9.3.3 同积分排名处理
对于相同Score的Member,ZSET进一步按照Member字典序排序,这就意味着当ZSET充当排行榜时,如果有多个用户积分相同,那么用户ID字典序更大的用户排名会更靠前,这是违反用户直觉的。比如在“每日跑步英雄”排行榜中:
- 早晨8点,ID为1111的用户跑步20千米,其排行榜积分为20,且位于排行榜第一名。
- 当天早晨8点到中午12点之间,没有其他用户跑步达到20千米,1111用户继续维持第一名。
- 当天中午12点 ,ID为2222的用户也跑步20千米,其排行榜积分也为20。由于“2222”的字典序大于“1111”,因此ZSET会将2222用户排在1111用户之前,于是2222用户成为第一名,而 1111用户被排到第二名。
- 1111用户查看排行榜,发现自己排名下降到第二名,且把自己顶掉的用户只不过和他跑的千米数相同而已。
- 1111用户大为不解,于是向产品方提交用户反馈:为什么2222用户跟我打了平手,排名却比我高,而且我还比他早一步达到20这个分数?
实际上,符合大部分排行榜的自然逻辑都应该是积分相同时,先达到此积分的用户排名应该更高,这样才符合用户对排行榜功能的预期。所以,排行榜需要有一个隐藏的特性:当积分相同时,自动按照时间先后顺序做二次排序。
虽然ZSET不支持按照更新时间排序,但是由于ZSET中的Score是浮点数类型的,我们可以让Score的整数部分存储积分,让小数部分存储积分更新时间戳。这样一来,积分更高的用户依然排名更高,而积分相同的用户可以进一步按照更新时间排序。为了实现当积分相同时按照时间先后排序,Score的小数部分存储的值应该保证先到者大于后到者,所以这里存储的时间戳不能是更新排行榜时的系统当前时间戳,因为系统时间戳的值随着时间在不断增加,与我们的要求是相反的。我们可以预设一个未来时间作为基准值(比如2050年1月1日0点整,时间戳为2524579200),将基准值减去更新排行榜时的系统当前时间戳的值作为小数部分的更新时间戳:
1 | update__time = 2524579200 - current_time |
这样就实现了先到者的更新时间大于后到者的效果。最终Score浮点数由用户积分和更新时间戳组成,如图9-2所示。

由于每次更新排行榜时都要在Score的小数部分记录更新时间戳,所以就不能再使用ZINCRBY了。因为ZINCRBY只会对积分累加,而无法重写小数部分。更新排行榜只能被拆分成如下几步。
- 使用ZSCORE命令获取用户的当前积分,并截取其整数部分,这是用户的真实积分。
- 将用户积分与此次更新的积分求和,作为积分更新后的整数部分。
- 将更新时间戳的值转换为小数,比如将12345转换为0.12345,作为积分更新后的小数部分。
- 使用ZADD命令将整数部分与小数部分组合成最终的积分写入排行榜。
对应的Lua脚本如下 :
1 | local res = redis.call('SET', KEYS[1] .. '_' .. ARGV[1], '0', 'EX', '3600', 'NX') |
运行Lua脚本,参数KEYS={排行榜名称,用户ID},ARGV={请求ID, 新增积分值, 更新时间戳}。更新排行榜最终需要使用3个命令:使用SET命令保证幂等性,使用ZSCORE命令获取当前积分,使用ZADD命令重写积分。
9.3.4 服务设计
在解决了幂等更新和同积分排名处理这两个问题后,我们就可以设计完整的排行榜服务了。
首先是协议部分。排行榜服务提供了 3个核心接口,对应的Thrift协议如下:
1 | namespace go ranking |
整体来说,选择Redis ZSET结构实现排行榜通常被认为是一种高效且可靠的方案,这种选择具有如下优势。
- 自动排序:ZSET会自动按照Score对Member排序,这使得其成为实现排行榜的理想数据结构。
- 高性能:ZSET底层使用跳跃表实现有序集合,数据的插入、删除、查询的时间复杂度都为O(logN),读/写效率都很高。
- 高并发:Redis服务器天然支持高并发读/写,而且主从模式架构能进一步满足高并发读取的需求,符合排行榜高度曝光的特点。
因此,笔者强烈推荐使用这种方案来实现排行榜。当然,它也存在如下一些缺点。
- 存储限制:这是Redis的主要缺点。虽然Redis支持数据持久化,但毕竟Redis是使用内存构建ZSET的,而内存是稀缺资源,当排行榜条目达到一定规模时,可能会出现内存不足的情况。我们需要保证Redis所在的物理机有充足的内存空间。
- 大Key问题:如果排行榜条目较多,那么很多人会质疑,使用ZSET将产生大Key,进而对Redis的性能产生影响。
9.3.5 关于大Key的问题
Redis的每种数据结构对大Key的定义都不同:
- String类型数据,长度超过10KB则被认为是大Key。
- ZSET、Hash、List、Set等集合类型数据,成员数量超过10000个即被认为是大Key。
对大Key的定义也不是绝对的,主要根据Value的成员数量和所占用的字节总数来确定。每个公司都有不同的大Key标准。之所以要定义大Key,因为Redis是单线程工作模型,只有在一个命令处理完后才会串行处理下一个命令,而大Key可能会造成Redis的性能损耗:
- 在读取大Key时,会占用更多的CPU资源和更大的网络带宽;
- 删除大Key耗时严重,可能阻塞线程,造成其他请求大量超时;
- 大Key有时也是热点Key,热点Key会造成大量的写请求访问同一个Redis实例,可能会影响稳定性。
假设有一个由5000万个用户参与的排行榜,即ZSET的成员数量最多为5000万个,那么这个排行榜在Redis中可以算作一个大Key。接下来,我们逐一分析上面提到的Redis性能损耗问题。
首先是读取大Key的问题。在任何一个产品的逻辑上,对5000万个用户的排行榜都不可能有一次性展示全部用户排名的需求,而是要分页展示,如每页展示100个用户排名。使用ZREVRANGE命令展示连续M个用户排名,时间复杂度仅为O(log(N)+M),其中N为 ZSET的成员数量,这并不会占用多少CPU资源与网络带宽。
然后是删除大Key的问题。Redis官方也注意到这个问题,并在Redis 4.0中正式推出了惰性删除(lazyfree)策略——Redis在决定删除某个Key时,采用异步方式延迟释放此Key使用的内存,即将该操作交给单独的子线程BIO(Backgroup I/O)进行处理,避免Redis主线程在删除大Key时被长期占用而影响系统的稳定性。这样一来,这个问题已经不再是问题了。
最后是热点Key的问题。如果排行榜激发了大量用户的参与欲望,那么确实可能产生高并发的排行榜更新请求,最终这些请求都会访问同一个Redis实例。
如果产品并不要求更新排行榜的效果被实时地展示在排行榜读取请求中,那么可以采用消息队列对高并发的更新请求进行削峰——将更新排行榜的事件发送到消息队列,然后由排行榜服务按部就班地拉取这些事件并更新排行榜,这样就可以使得排行榜服务按照单个 Redis实例实际的处理能力来更新排行榜。
如果产品要求实时性,则可以将ZSET排行榜拆分为多个子ZSET排行榜(比如10个),其中用户ID尾号为0的用户在第1个ZSET排行榜中排名,用户ID尾号为1的用户在第2个ZSET排行榜中排名,以此类推,这样就可以将高并发的更新排行榜请求打散到10个Redis实例中,防止出现单个Redis实例无法应对更新请求的风险。此时读取排行榜是一个合并操作:如果要读取前100名用户,则需要先读取10个子 ZSET排行榜的前100名,然后进一步合并筛选出真正的前100名,读取排行榜产生了10倍的读放大。将排行榜拆分成几个子排行榜,要根据读/写请求量进行综合权衡。
综上所述,即使是几千万个用户角逐的排行榜,使用ZSET也不会遇到太大的问题。 事实上,Redis理论上支持ZSET存储$2^{31}-1$个成员,即大约42亿个。如果公司的Redis内存足够大,那么即使存储半个地球的用户也绰绰有余。笔者认为,我们不应该因为ZSET排行榜存储了几千万个用户排名就武断地认为这会影响Redis的性能。笔者的线上实战经验表明,这个成员数量级的ZSET的性能表现没有明显劣化。至于ZSET存储几亿个成员时性能表现如何,笔者只能持保留意见,因为这样的需求罕见。
总结
如何适用ZSET来实现排行榜服务?
一个ZSET对象代表一个具体的排行榜,其中存储了用户ID和用户积分。
- Key,排行榜名称,用于区分不同的排行榜。
- Member,存储用户ID,作为排行实体。
- Score,存储用户积分,便于实现按照积分排序的功能。
直接使用ZINCRBY更新排行榜的缺点?
直接使用ZINCRBY的缺点是排行榜更新不具有幂等性。如果排行榜服务的上游调用者在更新排行榜时遇到网络超时而选择重试,那么就可能会导致用户积分被重复累计,最终引发其他用户对排行榜公平性的抱怨。
解决方案:我们可以要求上游调用者为每个更新排行榜的请求都提供一个分布式唯一ID作为请求ID,排行榜服务在收到更新请求后,先在Redis中查询是否已保存此请求ID,如果没有保存,则执行更新排行榜的操作,并将请求ID保存到Redis中,从而实现排行榜更新的幂等性。
整体来说,选择Redis ZSET结构实现排行榜通常被认为是一种高效且可靠的方案,这种选择具有如下优势?
- 自动排序:ZSET会自动按照Score对Member排序,这使得其成为实现排行榜的理想数据结构。
- 高性能:ZSET底层使用跳跃表实现有序集合,数据的插入、删除、查询的时间复杂度都为O(logN),读/写效率都很高。
- 高并发:Redis服务器天然支持高并发读/写,而且主从模式架构能进一步满足高并发读取的需求,符合排行榜高度曝光的特点。
因此,笔者强烈推荐使用这种方案来实现排行榜。当然,它也存在如下一些缺点?
- 存储限制:这是Redis的主要缺点。虽然Redis支持数据持久化,但毕竟Redis是使用内存构建ZSET的,而内存是稀缺资源,当排行榜条目达到一定规模时,可能会出现内存不足的情况。我们需要保证Redis所在的物理机有充足的内存空间。
- 大Key问题:如果排行榜条目较多,那么很多人会质疑,使用ZSET将产生大Key,进而对Redis的性能产生影响。




