第10章用户关系服务——10.5 基于图数据库的设计

第10章用户关系服务——10.5 基于图数据库的设计
John Yaml10.5 基于图数据库的设计
使用数据库与缓存结合实现高并发的用户关系服务是一种合格的传统方案,数据库、缓存技术都非常成熟,服务设计成本不是很高,所以在各大公司得到广泛应用。但是本节要介绍的是近年来有一定呼声的NoSQL数据库类型:图数据库。我们曾在1.10节中简单介绍过这种数据库,它以实体为点,以实体间的关系为边建立图结构,目的是更高效地描述和查询实体间的关系。用户关系服务是图数据库的典型应用场景之一,此服务本来就是用来处理用户之间的关注关系问题的,其中的用户就是图数据库的点,用户间关系就是图数据库的边。
接下来以比较知名的图数据库系统Neo4j为例,介绍如何实现用户关系服务。
10.5.1 实现用户关系
Neo4j使用Cypher查询语言(CQL)执行对图数据库数据的读/写操作,CQL不仅遵循数据库SQL语法,而且具有人性化、易理解的语言格式。
每个用户在Neo4j中都是一个节点,我们使用如下CQL语句创建了8个节点分别代表用户,将用户ID作为节点的属性:
1 | CREATE (u1:User {user_id:1111111}) |
为User节点设置的user_id属性用于记录用户ID,同时为此属性创建其到节点的索引,以便可以通过用户ID快速找到对应的User节点:
1 | CREATE INDEX ON :User(user_id) |
用户之间的关注关系是连接节点的边。如果用户U1关注了用户U2,那么在对应的User节点之间创建标签名为Follow类型的边,同时使用关注行为发生的时间作为边的属性:
1 | MATCH (u1:User {user_id:1111111)) , (u2:User {user_id:2222222}) // 先查找到User节点 |
为了方便介绍用户关系服务各个接口的实现,我们为目前这8个用户随机建立一些关注关系:
1 | CREATE (u1)-[:Follow{follow_time:'2022-04-17 22:05:37')]->(u2) |
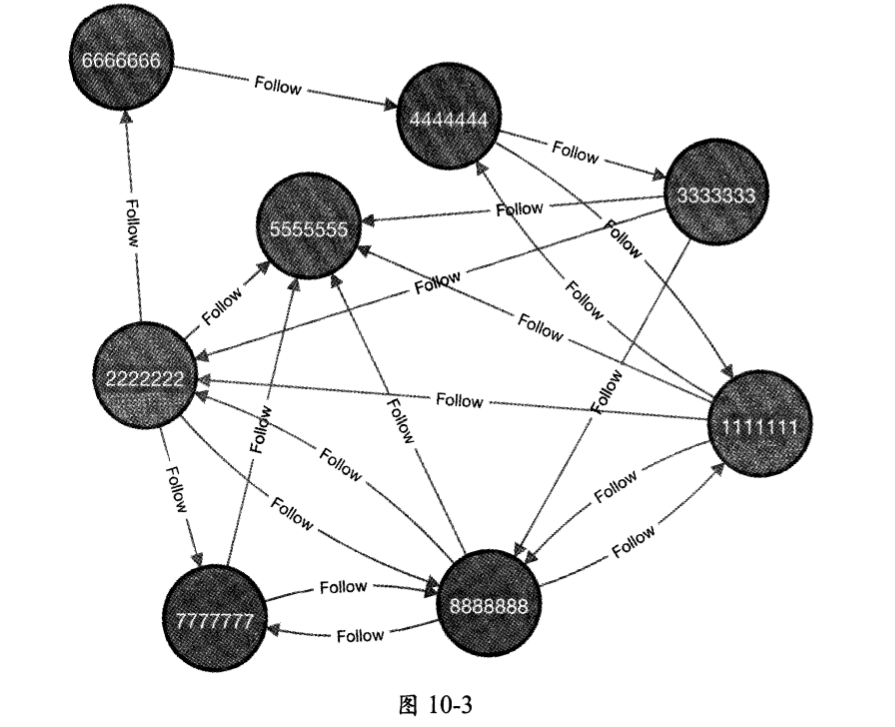
在 Neo4j操作界面中可以看到,创建这些关系后形成的图形数据如图10-3所示。
例如,查询用户u1的关注列表,就是查询其对应的User点主动与哪些节点建立了Follow类型的边。执行如下CQL语句:
1 | MATCH (u:User(user_id:1111111})-[f:Follow]->(v:User) RETURN v.user_id, f.follow_time ORDER BY f.follow_time DESC |
使用Follow类型的边的follow_time倒序排列,即可满足关注列表从近到远时间顺序的要求,执行此语句得到的关注列表结果如图10-4所示。

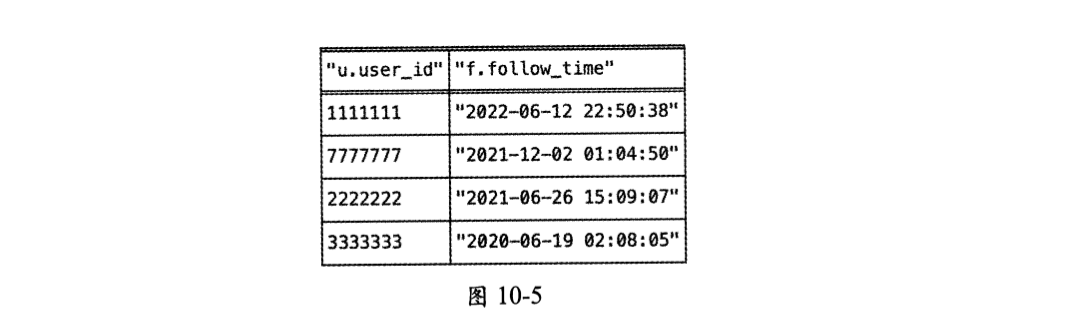
查询用户u8的粉丝列表,就是查询哪些User节点主动与用户u8对应的User节点建立了Follow类型的边,并按照follow_tinie倒序排列:
1 | MATCH (u:User)-[f:Follow]->(v:User(user_id:8888888}) RETURN u.user_id, f.follow_time ORDER BY f.follow_time DESC |
执行此语句得到的粉丝列表结果如图10-5所示。
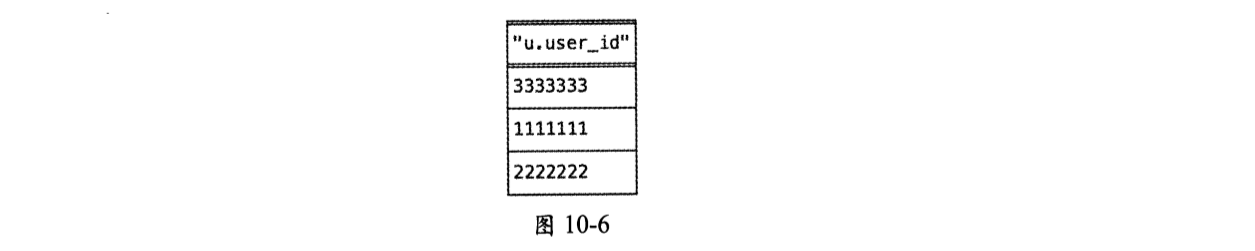
批量查询用户u1、用户u2、用户u3是否是用户u8的粉丝,就是查询它们对应的3个User节点是否有Follow类型的边指向用户u8对应的User节点:
1 | MATCH (u:User)-[f:Follow]->(v:User{user_id:8888888)) WHERE u.user_id IN [1111111,2222222,3333333] RETURN u.user_id |
执行此语句得到的结果如图10-6所示。
除了查询基本的用户关系接口,使用图数据库还可以非常容易地实现一些高级查询功能接口,如果这些查询使用传统数据库实现,则往往会比较沉重。下面举两个例子。
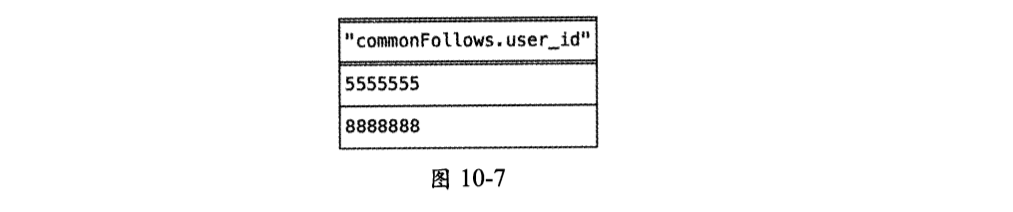
(1)查询用户u1和用户u2的共同关注人,Neo4j只需要执行一条CQL语句就可以高效完成这个任务:
1 | MATCH (u:User{user_id:1111111})-[:Follow]->(commonFollows)<-[:Follow]-(v:User (user_id:2222222}) RETURN commonFollows.user_id |
对应的查询结果如图10-7所示。
(2)查询在用户u1的关注列表中有谁关注了用户u5。如果使用10.4.4节介绍的传统方案,则需要取用户u1的关注列表和用户u5的全量粉丝列表的交集,而Neo4j只需要这样:
1 | MATCH (u:User(user_id:1111111})-[:Follow]->(someFollows)-[:Follow]->(v:User (user_id:5555555}) RETURN someFollows.user_id |
对应的查询结果如图10-8所示。

虽然这种复杂的高级查询功能接口一般不是用户关系服务的核心接口,但是有了这些功能接口,可以在一定程度上提高互联网应用内用户的互动性。比如你在使用微博的过程中点击打开了某用户的主页,虽然你更想看到的是该用户的头像以及其发布的内容,但是如果在该用户的主页上同时显示“你关注的谁也关注了该用户”或“你和该用户都关注了谁”,则可以进一步表达你们可能的兴趣和交际圈,起到锦上添花的作用。
10.5.2 应用权衡
图数据库是一种新兴的数据库类型,它以图形结构来存储和处理数据,适合处理复杂的关系型数据和网络数据。尽管图数据库具有许多优点,如具有高效的查询性能、灵活的数据模型和可扩展性,但目前它还没有得到真正的广泛应用。笔者认为可能的原因是图数据库缺乏标准化,各种图数据库产品使用了不同的数据模型、不同的设计原理、不同的查询语言来实现图数据库,不仅研发工程师学习图数据库的成本较高,而且由于缺乏统一的基础理论,很多数据库产品在实现图数据库时仍然在底层使用了其他NoSQL数据库。所以,对图数据库产品是否能够发挥图形数据的高效查询和保持高可用性是存疑的,一些公司对全量推广图数据库的态度也是相对保守的。
如果公司对推广图数据库的态度相对保守,则可以让图数据库承担一些非核心的但是能发挥其优势的接口实现。在10.4.4节给出的最终方案的整体架构的基础上,我们引入图数据库来负责复杂关系的查询,引入的思路也是借助伪从技术:图数据库为数据库Following表的伪从,随着Following表的数据变更而构建用户关系图数据,日常图数据库不负责处理用户关系服务的核心接口,只有非核心的、复杂关系查询的接口才由图数据库处理。此外,如果Redis或其他数据库发生故障,则在故障期间核心接口可以访问图数据库获取数据。也就是说,可以将图数据库作为用户关系的热备存储。
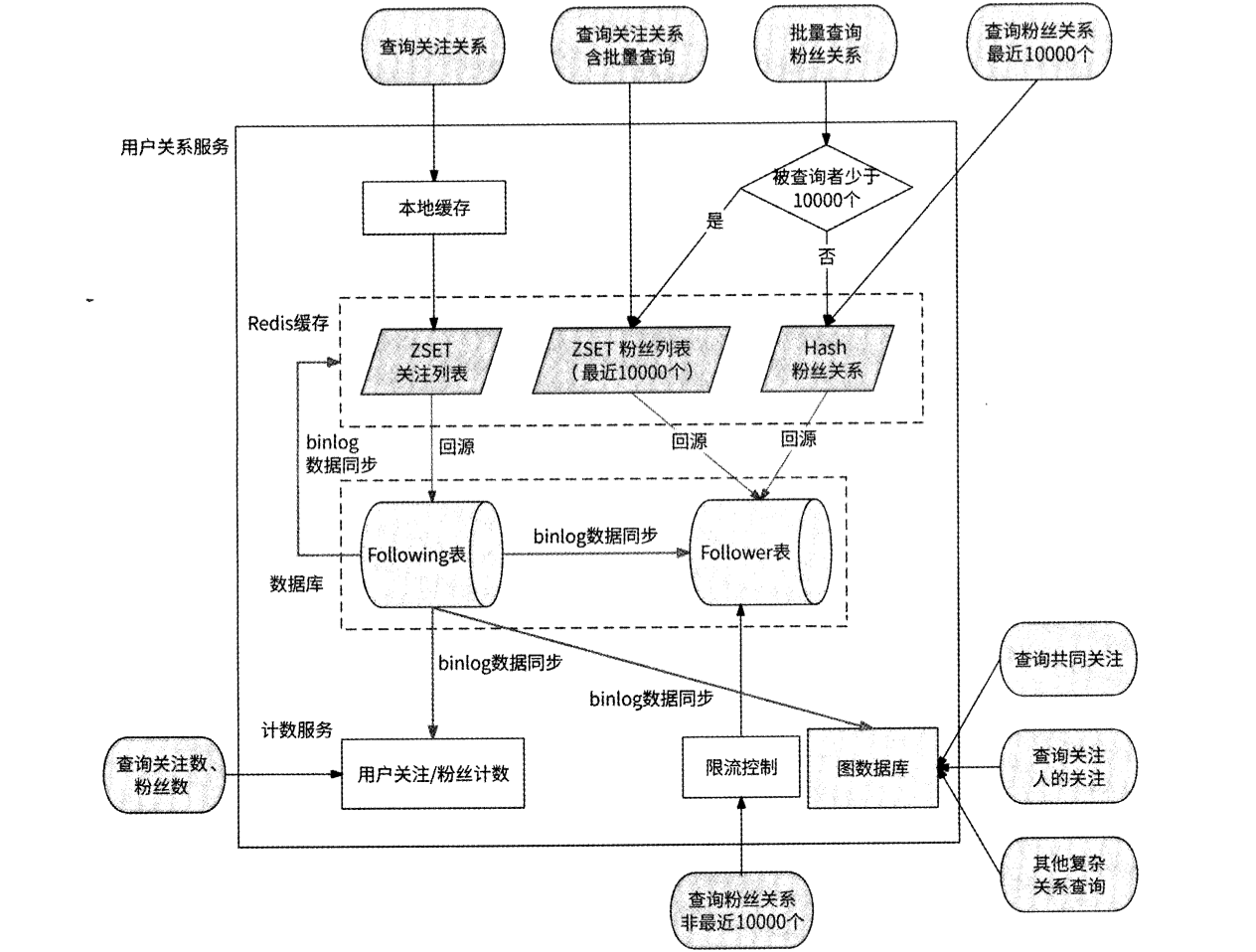
最后,基于图数据库设计的用户关系服务的完整架构如图10-9所示。
本章小结
实现高可用、高性能的用户关系服务,关键在于对各个存储系统的合理使用。
首先将数据库作为用户关系数据的最终存储。使用数据库存储海量用户关系势必要分库分表,所以最关键的设计就是需要把关系数据冗余存储到两个结构完全一样的数据表中。其中,Following表为主数据表,将from_user_id作为索引核心字段,负责用户的关注与取消关注、查询关注关系和查询关注列表的请求,而Follower表为Following表的伪从,复制完全相同的数据,但其索引核心字段为to_user_id,负责查询粉丝关系和查询粉丝列表的请求。另外,在这两个表的索引设计中可以使用覆盖索引,以进一步提高数据库查询性能。
然后将Redis作为数据库的缓存。用户的关注列表和用户的粉丝列表使用ZSET对象缓存,最近查询的粉丝关系则使用Hash对象缓存。我们需要重点关注的是大V,大V的粉丝量巨大,Redis无法全量缓存其粉丝列表,于是选择只缓存最近10000个粉丝。因为大部分读取粉丝列表的请求就是读取粉丝列表的前几页,至于读取粉丝列表后几页的请求 ,就只能交给数据库处理了,我们可以对这类请求进行限流以防止击垮数据库。Redis也被作为数据库Following表的伪从,用于实时地更新关注列表、粉丝列表的缓存。此外,对于关注列表还可以由每个服务实例本地缓存,以进一步减轻Redis的访问压力。
图数据库也很适合存储用户关系。图数据库以每个用户为节点,以用户之间的关注关系为边连接节点,最终形成图形数据。使用图数据库不仅可以方便地拉取用户的关注列表和用户的粉丝列表,而且能轻松地实现一些复杂关系的查询。我们可以仅使用图数据库来实现用户关系服务,也可以将它作为数据库的热备使用。
最后将用户的关注数、粉丝数交给计数服务维护。计数服务也被作为数据库Following表的伪从,以实时更新关注与粉丝的计数值。
总之,用户关系服务以数据库Following表为数据中心,将最新的用户关系数据复制到Follower表、Redis、图数据库和计数服务中。




