第10章用户关系服务——10.4 缓存查询

第10章用户关系服务——10.4 缓存查询
John Yaml10.4 缓存查询
虽然可以将数据库作为用户关系服务的存储选型,但是数据库毕竟是磁盘存储,其性能表现在高并发读场景中依然会遇到瓶颈。所以,本节我们在10.3节设计的基础上进一步通过缓存来优化高并发读场景的性能。
10.4.1 缓存什么数据
对于一个海量用户应用来说,读取用户的关注列表和粉丝列表,以及查询用户之间的关注关系都属于高并发读场景。
大部分互联网应用在设计用户关注功能时,都会限制每个用户的最大关注数量,这是为了防止用户滥用关注功能进行刷粉、刷流量等,避免影响应用内的用户体验和社交环境。如果不限制关注数量,那么有些用户可能会通过关注大量的其他用户来获取更多的关注和粉丝,从而提高自己的曝光率。新浪微博限制一个用户最多可关注2000人。这样的限制,意味着用户关注列表的长度不会超过2000人。因此,我们可以把用户的关注列表全量缓存到Redis中,数据模型与10.2节介绍的一致。
粉丝列表则不同,对用户拥有多少粉丝是没有限制的,这就意味着粉丝列表的长度可能达到数百万人、上千万人甚至上亿人,Redis无法全量缓存这些数据。不过,对于粉丝量巨大的大V来说,大部分用户只会简单地查看粉丝列表的前几页,很少有用户会专门耗费大量时间查看全部粉丝。所以,对于粉丝列表仍然可以使用Redis缓存,只不过仅缓存用户最近的10000个粉丝。对于查询最近10000个粉丝的用户请求,会优先查询Redis缓存 ;而对于查询10000个以外粉丝的用户请求,才会查询数据库。由于前者在读取粉丝列表的请求中占绝大多数,所以缓存最近10000个粉丝已经足以应对高并发的请求量。
不过,如果黑客恶意发起大量请求拉取最近10000个粉丝以外的粉丝列表,那么这些请求会统统访问数据库,可能造成数据库宕机。我们可以采用限流的方式来解决这个问题,比如在收到读取粉丝列表的请求时,用户关系服务先检查此请求查询的数据是否在最近10000个粉丝之外,如果是,则检查此时的请求量是否已达到限流阈值,对于超过限流阈值的请求拒绝执行。
我们再来讨论一下查询用户之间的关注关系的问题。查询两个用户之间的关注关系非常容易,使用关注列表缓存即可。比如查询用户1是否关注了用户2(即用户1是否为用户2的粉丝),只需要查询在用户1的关注列表缓存中是否包含了用户2即可。批量查询用户1是否关注了一些用户也是一样的,只需要查询在用户1的关注列表缓存中是否包含了这些用户即可。
比较麻烦的是如何批量查询一些用户是否是用户1的粉丝。如果用户1的粉丝很少(即用户1拥有不超过10000个粉丝),使用缓存可以全量存储,那么此时可以直接查询用户1的粉丝列表缓存;而如果用户1 的粉丝众多,Redis仅缓存了最近10000个粉丝,那么此时待查询的用户在缓存中不一定存在。
一种解决方案是使用关注列表缓存反查,即对于不在用户1的粉丝列表缓存中的用户,进一步查询在这些用户的关注列表缓存中是否包含了用户1。比如现在要批量查询100个指定用户是否是大V 用户1的粉丝,在用户1的最近10000个粉丝中可以查询到其中的10个用户,那么对于剩下的90个用户,我们开启90个线程来分别查询这90个用户的关注列表缓存。为一个批量查询请求额外创建了90个线程,来执行90个查询Redis缓存的请求,所以,这种解决方案可能会带来线程暴涨和读请求被放大的问题,而这取决于批量查询的用户数量。
另一种解决方案是进一步缓存粉丝关系,即使用Redis缓存最近查询过的若干用户是否为用户1的粉丝的关系。具体来说,Redis使用Hash对象缓存数据,Key代表用户1, Field代表用户2、用户3、用户4 等指定用户,对应的Value表示这些用户是否分别是用户1的粉丝,其中值为1表示是粉丝,值为0表示不是粉丝。如果在待查询的这些用户中至少有一个用户不在此Hash对象中,则需要进一步为其回源查询数据库Follower:
1 | SELECT from_user_id FROM Follower WHERE to_user_id = 用户1 AND from_user_id IN (...) AND type = 1 |
这种方案会进一步占用Redis的存储空间,且 Hash对象可能会随着请求访问量的增加而变得越来越大,我们需要注意设置合理的过期时间。
10.4.2 缓存的创建与更新策略
创建缓存很简单,当用户请求访问关注列表或粉丝列表时,用户关系服务会先查询Redis缓存,如果查询不到数据,再进一步从数据库中获取数据,然后在Redis中创建对应的ZSET对象。
当用户1关注或取消关注用户2时,用户1的关注列表缓存和用户2的粉丝列表缓存就失效了。我们可以使用2.4.5节介绍的“先更新数据库,再删除缓存”方案,在数据库中执行完关注、取消关注操作后,将用户1关注列表和用户2 粉丝列表的缓存数据从Redis中删除。不过,对于大V来说,被关注的事件会频繁发生。假设有大V用户A,在1min内奇数秒时有用户读取A的粉丝列表,偶数秒时有用户关注A,那么缓存的工作流程如下。
- 第1秒 ,有用户读取A粉丝列表,此时Redis并未缓存此数据,于是请求会回源数据库获取A的粉丝列表,然后在Redis中创建缓存。
- 第2秒 ,有用户关注A,在数据库中写入关注关系后,Redis中A的粉丝列表被删除。
- 第3秒 ,有用户读取A的粉丝列表,由于Redis已经删除了此数据,所以请求又会回源数据库,然后又在Redis中创建缓存。
- 第4秒 ,有用户关注A,Redis中A的粉丝列表又被删除。
- 第5秒 ,有用户读取A的粉丝列表,于是再次回源数据库,在Redis中创建缓存。
- 第6秒 ,有用户关注A,Redis的缓存再次被删除。
- 第7~60秒 ,以此类推。
可见,前脚读取粉丝列表的请求在Redis中创建了缓存,后脚此缓存就被关注请求删除了,这就导致读取粉丝列表的请求永远在回源数据库,而Redis缓存完全没有起到作用,甚至在被无意义地反复创建与删除。
虽然现实情况是读取粉丝列表的请求和关注请求不太会恰好交替发生,但是只要比较频繁地发生关注事件,就会造成缓存被频繁地删除与创建,缓存用于应对高并发读请求的作用被削减。所以,对于粉丝列表缓存,并不适合采用“先更新数据库,再删除缓存”方案。缓存数据应该总是存在的,所以更合适的方案是缓存随着数据库的更新而更新。
其实现思路是使用伪从技术:创建专门的消费者服务作为数据库Following表的伪从,订阅 binlog,每当Following表有变更(即发生关注、取消关注事件)时,消费者服务都会收到最新数据变更binlog,然后修改缓存。
比如用户A关注了用户B,在Following表中写入此数据后,消费者服务收到对应的binlog,得知此时发生了“用户A关注用户B”的事件,于是在Redis中检查用户B的粉丝列表缓存是否存在;如果存在,则修改缓存数据,即将用户A加入用户B的粉丝列表ZSET中。这样一来,用户的粉丝列表缓存不会因为关注事件而被删除,而是与数据库对齐数据,“用户A关注用户B”的事件可以近实时地被反映在缓存中,后续读取粉丝列表的请求仍然可以命中缓存,而不需要回源数据库,缓存仍然发挥作用。使用伪从技术更新缓存可以有效提高缓存命中率,在缓存与数据库的数据一致性方面表现很好,唯一的顾虑是相对于“先更新数据库,再删除缓存”方案来说,有一点儿开发成本。
至于关注列表缓存,使用“先更新数据库,再删除缓存”方案没有太大问题,毕竟一个用户不太可能总是要关注其他用户,其关注列表相对稳定。当然,关注列表缓存也像粉丝列表缓存一样,使用伪从技术更新缓存也没有什么问题。
综上所述,在关注事件发生后,为了应对缓存失效的问题,关注列表缓存可以被删除,而对于粉丝列表缓存更适合采用伪从技术进行更新。如果不想区别对待关注列表缓存和粉丝列表缓存的更新策略,那么统一使用伪从技术更新缓存就行。
10.4.3 本地缓存
大V的关注列表的曝光率要远远大于普通用户的,很多用户都会关心大V关注了哪 些人。另外,大V在关注其他用户时相对谨慎,这就意味着他们的关注列表数据比较固定。综合考虑关注列表的访问量大、数据不易变这两个特点,我们可以将大V的关注列表进一 步存储到本地缓存中,从而减少访问Redis,进一步提高访问性能。
粉丝列表的数据特点则完全不同。大V的粉丝变动非常频繁(毕竟是网红),并不适合使用本地缓存;而普通用户的粉丝变动虽然相对较小,但是其粉丝列表的访问量也非常小,使用本地缓存不会有很高的缓存命中率,且意义不大。所以,无论是何种用户,都不适合使用本地缓存。
10.4.4 缓存与数据库结合的最终方案
经过对数据库设计、缓存设计的详细讨论,我们总结并提炼出缓存与数据库结合的最终方案。图10-2展示了用户关系服务设计最终方案的整体架构图。
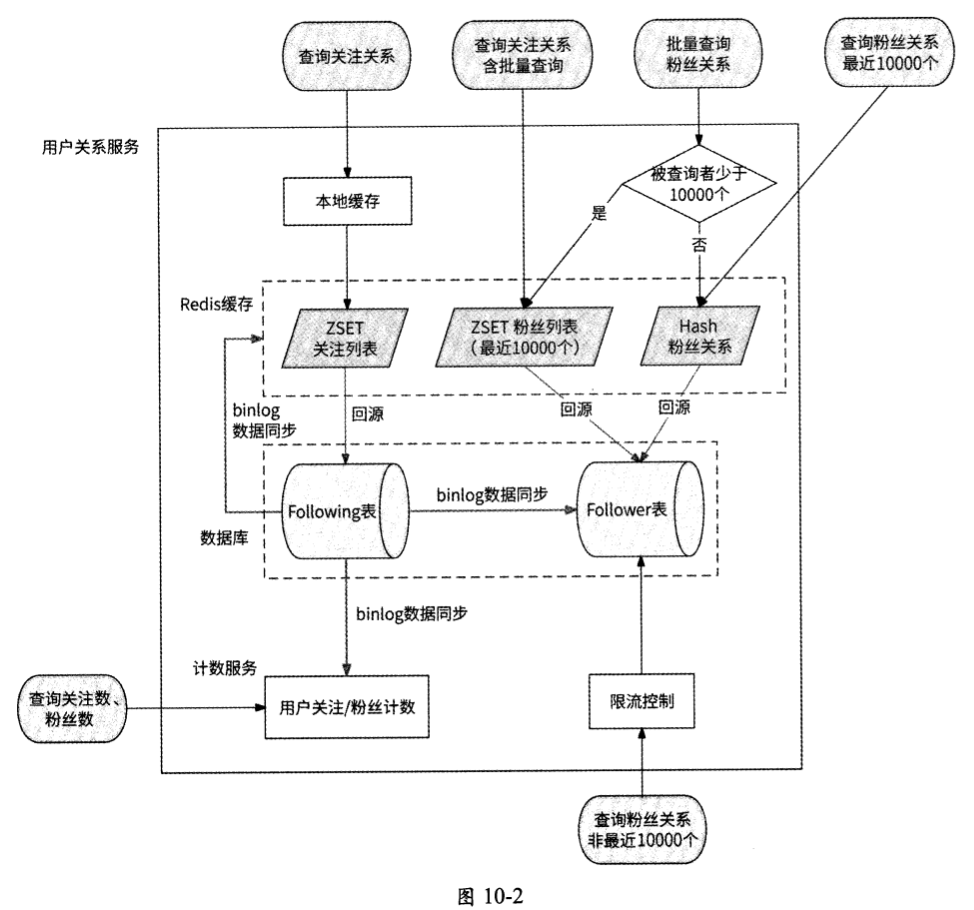
这套架构的核心是:Following表为数据库的主表,Follower表、计数服务、Redis缓存都以Following表为标准来更新数据。针对这样设计的用户关系服务,我们再详细描述一下每个接口的工作流程。
关注与取消关注的接口。这个接口直接更新数据库Following表即可响应用户,后续流程对用户来说是完全异步的,Follower表、计数服务、Redis缓存会依赖Following表产生的binlog分别更新数据。假设用户1关注了用户2:
- Follower表会使用from_user_id(用户1)、to_user_id(用户2)、关注时间更新表。
- 计数服务会计数消费者请求计数服务增加用户1的关注数和用户2 的粉丝数。
- Redis缓存会缓存消费者在用户1的关注列表缓存中加入用户2,在用户2的粉丝列表缓存中加入用户1。
查询用户关注列表的接口。用户关系服务先查询处理此请求的服务实例的本地缓存中是否有数据,如果没有数据,则再查询Redis中是否存在对应的数据;如果不存在对应的数据,则回源数据库,将所得到的结果以ZSET对象的形式存储到Redis中。然后,检查此用户的粉丝数是否达到一定的阈值(即是否是大V),如果达到,则将其关注列表数据也缓存到服务实例的本地缓存中。
查询用户粉丝列表的接口。如果用户查询的是最近10000个粉丝,则先查询Redis;如果查询不到,再回源数据库,将所得到的结果缓存到Redis中。如果用户查询的不是最近10000个粉丝,则需要对请求进行限流,只有当请求量未达到限流阈值时才允许从数据库中查询粉丝列表,以保护数据库不被高并发请求打垮。
查询用户的关注数与粉丝数的接口。这个接口非常简单,直接调用计数服务获取结果即可。
查询用户关系的接口。这个接口较为复杂,取决于是否是批量查询:
查询用户1与用户2的关注关系,以用户1的关注列表为判断标准,先从Redis中查询在用户1的关注列表缓存中是否存在用户2,如果缓存不存在,则回源数据库,拉取用户1的关注列表并缓存到Redis中。其流程与查询用户关注列表的接口的流程非常相似。
查询用户1是否关注了若干用户(用户2、用户3、用户4),依然以用户1的关注列表为判断标准,流程同上,只不过在获取到用户1的关注列表数据后,从中筛选出指定的用户。
查询若干用户(用户2、用户3、用户4)是否关注了用户1,则要先查询用户1的粉丝数。
- 如果粉丝数少于10000个 ,则其查询流程与粉丝列表请求的查询流程非常类似。无论是读取粉丝列表缓存还是回源数据库,只要在获取到用户1的粉丝列表后,查看粉丝列表中是否包含用户2、用 户3、用户4即可。最后给出这些用户是否分别关注了用户1的结论。
- 如果粉丝数大于10000个,则说明从粉丝列表缓存中可能无法得到准确的关系判断,此时无法依赖粉丝列表缓存,而只能依赖粉丝关系缓存,即使用Redis Hash对象形式的缓存。首先请求查询用户2、用户3、用户4是否在用户1的Hash对象中,然后根据查询结果进行下一步操作:如果这些用户都可以被查询到,则直接返回是否关注的结果;而如果用户2和用户3不在Hash对象中,则回源数据库Follower表查询两者与用户1的关注关系,并将结果回写到Redis Hash对象中。




