第10章用户关系服务——10.3 基于数据库的设计

第10章用户关系服务——10.3 基于数据库的设计
John Yaml10.3 基于数据库的设计
既然存储用户关系需要大量的存储空间,那么还是使用数据库来设计方案为好。
10.3.1 最初的想法
创建一个数据表来表示用户1与用户2的关注关系,数据表名为User_relation,表结构如表10-1所示。
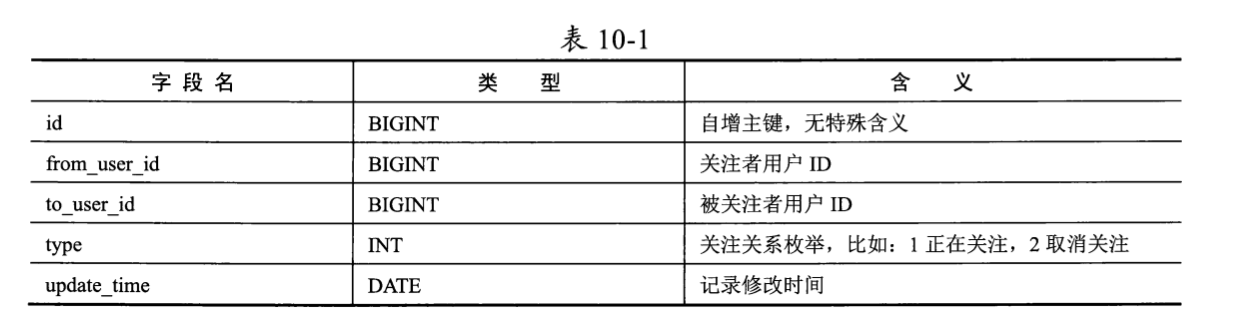
User relation数据表的每行记录都描述了from user id对to_user_id的关注关系。细心的读者可能已经发现,这里的表结构没有提到将哪个字段作为索引。这是因为在使用数据库实现用户关系服务时,对索引的设计需要考虑一些必要的技术细节,需要经过专门讨论后才能得出最佳设计结论。
为了高效支持查询用户1是否关注了用户2,以及查询某用户的关注列表,我们首先想到的是为from_user_id字段创建索引;同样,为了高效支持查询某用户的粉丝列表,我 们也需要为to_user_id字段创建索引。那么,创建这两个索引是不是就可以了?
答案是不可以。假设我们的应用拥有1亿个用户,平均每个用户关注1000个用户,那么User_relation表将拥有至少1千亿条数据。为了支持对数据库的高性能读/写,User_relation表必然要分库分表。
分库分表的依据应该是索引,否则,分库分表将失去其数据分区的优势。假设某数据表T的结构为T(A,B,C),其中A字段是索引。如果将B字段作为分库分表的依据,将T表拆分为100个子表,那么基于A字段值为x的数据查询请求,将不得不访问这100个子表来获取数据,因为A字段值为x的数据可能分布在这100个子表中;而如果使用A字段值来分库分表,那么只需要访问A字段值为x的1个子表即可。所以,我们应该将索引作为分库分表的依据。
然而,User_relation表有两个索引,分别是from_user_id字段的索引和to_user_id字段的索引,那么应该将哪个索引作为分库分表的依据?如果使用from_user_id字段来分库分表,那么在查询用户的粉丝列表时要访问所有的子表;使用to_user_id字段同理。这就是我们遇到的最核心的坑点。
10.3.2 应对分库分表
如果非要在这两个索引上寻求一个分库分表的依据,那么显然是没有答案的。所以,不如使用两个数据表来描述用户的关注关系:Following表和Follower表。这两个表的结构与User_relation表完全相同,只不过Following表使用from_user_id作为索引,Follower表使用to_user_id作为索引。
当查询用户1是否关注了用户2、查询某用户的关注列表,以及批量查询某用户对若干用户的关注关系时,使用Following表;而当查询某用户的粉丝列表、批量查询若干用户与某用户的粉丝关系时,使用Follower表。这样一来,这几种场景都可以命中索引,提高查询效率。
这种思路要求Following表与Follower表的数据完全一致,所以在创建和修改两者的数据时需要建立数据一致性关系。使用1.14.2节介绍的伪从技术是一种合适的方案,即Follower表作为Following表的伪从,消费Following表产生的数据更新binlog,如图10-1所示。
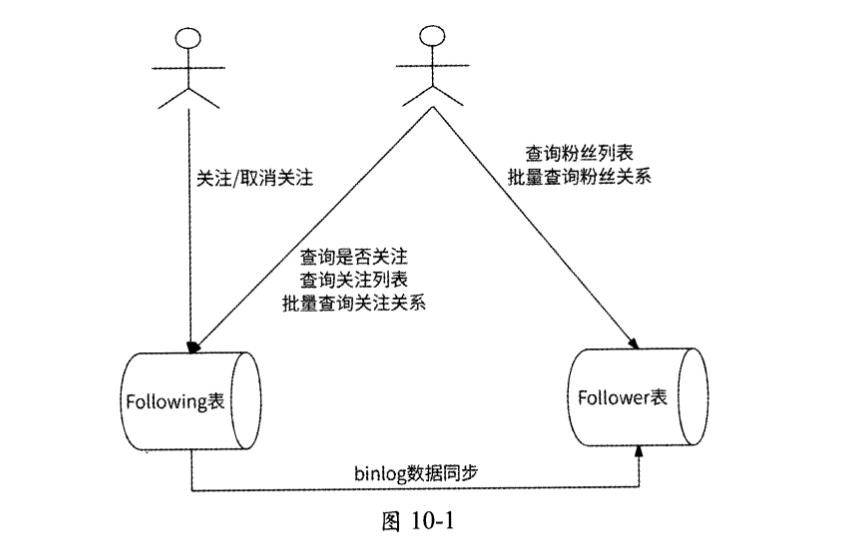
当用户1关注或取消关注用户2时,仅需要在Following表中更新数据,Follower表作为伪从会自动同步最新数据,保证了两者数据的一致性。
10.3.3 Following表的索引设计
我们应该为Following表创建怎样的索引?这要从它负责的查询功能说起。
首先,Following表需要支持查询用户1是否关注了用户2,即需要运行如下SQL语句,依次查询from_user_id字段、to_user_id字段和type字段是否满足条件:
1 | SELECT 1 FROM Following WHERE from_user_id = 用户1 AND to_user_id = 用户2 AND type = 1 |
如果将from_user_id字段作为索引,则数据库会先根据索引快速定位到from_user_id为用户1的数据记录,然后逐个扫描这些记录,找到满足to_user_id用户2的记录,并检查其type是否为1。如果用户1关注了上万个用户,那么通过索引会筛选出上万条数据记录让数据库逐个扫描。这是一个比较耗时的动作。
更好的做法是使用from_user_id字段和to_user_id字段做联合索引,数据库会根据此联合索引快速查询from_user_id用户1、to_user_id为用户2的数据记录。如果查询到相应的记录,则判断type是否为1即可。联合索引可以保证快速定位到用户1是否关注了用户2的相应记录。所以,为了高效支持查询用户之间的关注关系,我们需要创建联合索引idx_following:
1 | KEY idx__foilowing(from_user_id, to_user_id) |
其次,Following表需要支持查询用户1的关注列表,并按照关注时间从近到远返回结果,对应的SQL语句如下:
1 | SELECT to_user_id FROM Following WHERE from_user_id = 用户1 AND type=1 ORDER BY update_time DESC |
同样,如果将 from_user_id字段作为索引,则数据库会先根据索引快速定位到from_user_id用户1的数据记录,然后扫描筛选type为1的记录。所以,更合适的索引是from_user_id字段和type字段的联合索引,这样可以免去扫描而直接得到用户关注记录。 此外,由于关注列表要按照时间从近到远排序(SQL语句为ORDER BY update time DESC),所以对查询到的用户关注记录还需要使用额外的临时空间进行排序,这也会给数据库造成负担。我们应该把update_time字段也加入联合索引中,最终联合索引是由3个字段组成的:
1 | key idx_following_list(from_user_id, type, update_time) |
数据库索引保证:索引中的每个字段均按照值的大小排列,且当某个字段的值相同时,再按照下一个字段继续排序。
对于idx_following_list索引来说,先按照from_user_id字段对数据记录进行排序;
对于from_user_id字段值相同的记录,再按照type字段排序;
对于type字段值相同的记录,再按照update_time字段排序。
所以,当执行上面的SQL语句时,from_user_id为用户1且type为1的记录是天然按照update_time字段排序的,获取时间从近到远的记录无非就是从最后一条记录开始反向读取,数据库无须再专门使用临时空间对数据记录进行排序,进一步提高了数据库查询性能。为了高效查询用户的关注列表,我们还需要创建idx_following_list索引。
最后,为了批量查询用户1是否关注了用户2、用户3和用户4,需要执行如下SQL语句:
1 | SELECT to_user_id FROM Following WHERE from_user_id = 用户1 AND to user id IN (用户2, 用户3, 用户4) |
这条语句的筛选条件from_user_id、tp_user_id正好可以命中联合索引idx_following。
总之 ,对于Following表需要创建两个联合索引,即idx_following和idx_following_list,而且这两个联合索引的第一个字段均为from_user_id。所以,即使按照from_user_id字段对Following表分库分表,其子表也可以充分利用索引的优势。
10.3.4 Follower表的索引设计
首先 ,Follower表需要支持查询用户的粉丝列表,并按照关注时间从近到远返回结果。 对应的SQL语句如下:
1 | SELECT from_user__id FROM Follower WHERE to_user_id=用户 1 AND type=1 ORDER BY update_time DESC |
与为Following表创建idx_fbllowing_list索引的思路一样,我们为Follower表创建idx_follower_list索引:
1 | KEY idx_follower_list(to_user_id, type, update_time) |
其次,Follower表需要支持批量查询用户2、用户3、用户4是否是用户1的粉丝。 对应的SQL语句如下:
1 | SELECT to_user_id FROM Follower WHERE to_user_id = 用户1 AND from_user_id IN (用户2, 用户3, 用户4) 一 |
为了使to_user_id条件和from_user_id条件可以依次命中索引,我们继续创建联合索引idx_follower:
1 | KEY idx_follower(to_user_id, from_user_id) |
10.3.5 进阶:回表问题与优化
无论是Following表还是Follower表 ,我们创建的索引都属于非聚集索引。以MySQL InnoDB存储引擎为例,索引被区分为聚集索引和非聚集索引。
聚集索引指的是将数据记录与索引保存到一起的索引,比如主键索引就是一种典型的聚集索引,InnoDB中的一个数据表就是一个聚集索引;
非聚集索引是分开存储数据记录与索引的,索引仅存储对应数据记录的指针(一种指针的形式是主键),比如上面创建的4个联合索引就是非聚集索引。
以Following表的联合索引idx_following(from_user_id, to_user_id)为例,执行如下SQL语句:
1 | SELECT 1 FROM Following WHERE from_user_id = 用户1 AND to_user_id = 用户2 AND type = 1 |
数据库使用from_user_id和to_user_id条件命中了非聚集索引idx_following,并且在其中查询到对应数据记录的主键。为了得到数据记录的type字段值,数据库接着使用主键访问主键索引得到数据记录,读取其type字段值。这 条SQL语句依次访问了idx_fbllowing索引和主键索引。
而如果执行如下SQL语句,不查询type字段:
1 | SELECT 1 FROM Following WHERE from_user__id = 用户1 AND to_user_id = 用户2 |
那么在这条SQL语句命中idx_following索引后 ,我们会发现所有待查询的字段(from_user_id和to_user_id)均已经在此索引中,所以直接返回结果即可,这条SQL语句并不需要访问主键索引。
上面第1条SQL语句的执行效率要低于第2条SQL语句,因为非聚集索引无法涵盖其查询的字段,所以需要进一步访问主键索引。这个问题被称为“回表”。因此,对于基于非聚集索引的查询,如果待查询的字段均在非聚集索引中,那么可以减少1次索引访问,即防止数据库回表,提高了数据库查询性能。按照这种思路,我们重新考虑在10.3.3节和10.3.4节中创建的那4个索引。
idx_following(from_user_id, to user id):用于查询用户之间的关注关系。由于此索引中不包含type字段,所以会回表。idx_following_list(from_user_id, type, update time):用于查询用户的关注列表。由于此索引中不包含to_user_id字段,所以会回表。idx_follower_list(to_user_id, type, update time):用于查询用户的粉丝列表。由于索引中不包含from_user_id字段,所以会回表。idx_follower(to_user_id? from_user_id):用于批量查询用户的粉丝关系。由于此索引中已经包含from_user_id字段,所以不需要回表。
上面前3个索引都产生了回表问题。为了进一步提高数据库查询性能,可以对这3个索引进行扩展以防止回表。
- 将idx_following索引扩展为(from_user_id, to_user_id, type)。
- 将idx_following_list索引扩展为(from_user_id, type, update_time, to_user_id)。
- 将idx_follower_list索引扩展为(to_user_id, type, update_time, from_user_id)。
在这3个索引中加入对应的SQL查询语句所需的全部字段,这样一来,在数据库中查询数据时,仅在非聚集索引上就可以得到结果,避免了不必要的回表操作,数据库查询性能得到进一步提升。这种覆盖了SQL查询语句所需查询的全部字段的索引被称为“覆盖索引”,它是一种典型的以时间换空间的思路。为非聚集索引加入新字段会使得它的存储空间占用更大,不过好在索引被存储在磁盘上,使用磁盘资源并不是那么奢侈。
10.3.6 关注数和粉丝数
虽然可以使用COUNT命令从数据库中获取用户目前的关注数与粉丝数,但是本书8.2.2节介绍过这种方式效率非常低下,更好的方法是使用计数服务单独存储这些数据。我们可以使用伪从技术,创建一个消费者服务作为Following表的伪从,订阅Following表的binlog,当用户1关注或取消关注用户2时,消费者服务会收到此事件对应的binlog,然后在计数服务中更新用户1的关注数和用户2 的粉丝数;当读取某用户的关注数和粉丝数时,直接从计数服务中获取数据即可,不需要与数据库交互。




