第4章唯一ID生成器——4.3 基于时间戳的趋势递增的唯一ID

第4章唯一ID生成器——4.3 基于时间戳的趋势递增的唯一ID
John Yaml时间戳是指计算机维护的从1970年1月1日开始到当前时间经过的秒数,并且随着时间的流逝而逐步递增。几乎所有的编程语言都仅需要一行代码,就可以轻而易举地得到当前时间戳,并支持毫秒精度,甚至是纳秒精度。时间戳自增的属性非常适合生成趋势递增的唯一ID。
4.3.1 正确使用时间戳
时下最为普及的计算机普遍采用64位操作系统,对应的时间戳也是用64位表示的。在4.1.2节中已经明确了唯一ID也是64位的,这样不就意味着唯一ID正好可以用时间戳表示吗?这种做法是不可取的,原因很简单,在高并发场景下,同一时间有很多业务请求到达唯一ID生成器,如果用时间戳表示唯一ID,就会生成重复的ID。
对于基于时间戳的唯一ID,应该继续考虑高并发与分布式环境下的其他变量。例如:
- 服务实例:同一时间业务请求1和业务请求2分别从ID生成器服务实例A和服务实例B获取唯一 ID,为了防止生成重复的ID,在唯一ID上应该对服务实例的差别有所体现。
- 请求:同一时间业务请求1和业务请求2从LD生成器服务实例A获取唯一ID,在唯一ID上应该区分这两个请求。
话是没错,但是时间戳已经占用了唯一ID的全部空间,还怎么考虑其他变量呢?其实照搬计算机时间戳的概念是一个常见的谬误。根据笔者的面试经验来看,不少面试者都知道唯一ID生成器可以用时间戳来实现,但是对时间戳已经占用唯一ID的全部空间(64位时)往往百思不得其解。
再看一遍时间戳的概念:从1970年1月1日开始到当前时间经过的秒数。假设我们设计的唯一ID生成器在2023年1月1日上线,那么根本不需要关心在上线时间之前时间戳的数值。所以,我们可以将时间戳的起始时间改为上线时间,仅记录唯一ID生成器从上线时间到当前时间经过的秒数就行。对于毫秒精度也是同样的道理。
假设我们期望唯一ID生成器可以正常提供服务50年(已经很久了),总计1,576,800,000s,那么实际上使用31位整数即可表示时间戳。即使采用毫秒精度的时间戳,41位整数也已经足够使用。所以,我们只记录唯一ID生成器从上线时间到当前时间的相对时间戳即可。
另外,需要强调的是,一个整数的大小优先由数字的高位决定。所以,时间戳应该被设置到唯一ID的高位,这样才能保证随着时间的推移唯一ID趋势递增。
4.3.2 Snowflake算法的原理
Snowflake的中文意思是雪花,所以Snowflake算法也被称为雪花算法。它最早是Twitter公司内部后台使用的分布式环境下的唯一ID生成算法,2014年开源了Scala语言版本。
Snowflake算法的原理是将分布式环境下的各变量按数位组合成64位的long类型数字生成唯一ID。如图4.8所示,唯一ID是由多个数位分段组成的,这些分段从高位到低位依次如下。
- 1位:符号位,固定值为0,用于保证生成的long类型ID是正整数。
- 41位:存储当前时间与指定时间(可以是上线时间)的毫秒差值,从指定时间开始可运行$2^{41}/(1000\times 60\times 60\times 24\times 365)\approx 69$年。
- 5位:用于区分不同的机房,最多支持$2^5=32$个机房。
- 5位:用于区分ID生成器服务的不同实例,支持$2^5=32$个实例。不过,这5位与前5位共享10位存储空间——如果是单机房环境,则无须区分不同的机房,可以用10位来区分ID生成器服务的不同实例,即支持1024个服务实例;如果最多会建设6个机房,则区分不同的机房只需3位,可以用剩下的7位来区分ID生成器服务的不同实例。
- 12位:最后12位用于区分单个ID生成器服务实例在同一毫秒内生成的唯一ID,最多支持$2^{12}=4096$个唯一 ID,即单个服务实例1s可支持约410万个唯一ID生成请求。
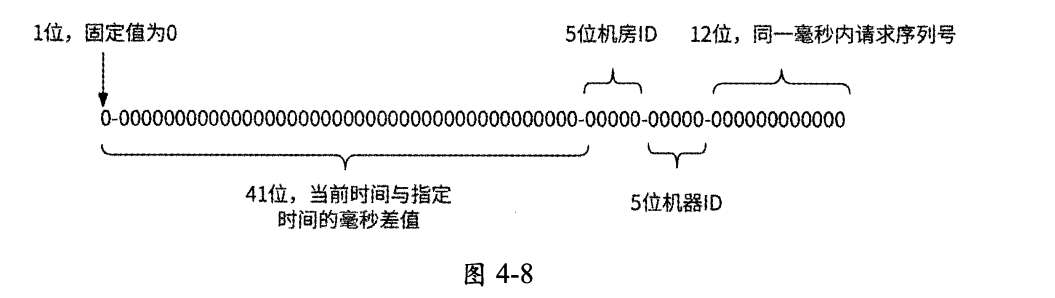
最终效果是,Snowflake算法给出的唯一ID生成器是一个支持多机房共1024个服务实例规模、单个服务实例每秒可生成410万个long类型唯一ID的分布式系统,且此系统可以正常工作69年。
4.3.3 Snowflake算法的灵活应用
Snowflake算法是想告诉我们:需要将所考虑的高并发与分布式环境下的变量都体现在唯一ID上,不是必须使用41位表示毫秒级时间戳、5位表示机房、5位表示服务实例、12位表示同一毫秒内的并发请求,而是应该按照实际的业务情况进行灵活调整。
假设某互联网公司将唯一ID生成器立为项目,该公司目前的条件如下。
- 1位:依然是符号位,固定值为0,以保证生成正整数。
- 40位:系统运行的总毫秒数,30年约为9461亿毫秒,可以用40位二进制数表示。
- 2位:用于区分3个机房,并满足将来增加一个新机房的需求。
- 接下来的10位:单个服务实例每秒处理100万个请求,即每毫秒处理1000个请求。使用10位二进制数来区分同一毫秒内的并发请求。
- 最后的11位:可全部用于区分单个机房内唯一ID生成器服务的不同实例,即可支持部署最多2048个服务实例。
最终的唯一ID生成器服务在全部机房每秒可承接的用户请求量为$3\times 2048\times 100$万,约等于61亿个,远超公司预期的请求量,并可实际运行34年有余。这个服务的核心代码实现也很简单,需要额外注意的细节是,如果在某一毫秒内处理的用户请求量超过1024个,那么服务将报错返回或者使请求阻塞等待到下一毫秒:
1 | // ID生成器服务结构体 |
Snowflake算法要求人工指定系统初始时间、机房ID和服务实例ID。系统初始时间,可以设置为唯一ID生成器服务上线的时间;机房ID,很容易人为指定,如指定北京机房ID为1,深圳机房ID为2,上海机房ID为3;服务实例ID,由于唯一ID生成器服务本身涉及功能迭代、扩容、缩容,服务实例的集合相对动态,所以直接人工指定服务实例ID不太现实,我们需要找到一种自动化的方式,为目前在线的唯一ID生成器服务的不同实例分配服务实例ID。
4.3.4 分配服务实例ID
为了保证生成的ID的唯一性,应该为ID生成器服务的不同实例分配不同的服务实例ID(worker ID)。这其实也是唯一ID生成器的问题,4.2.2节介绍的数据库自增主键方案就是一种合适的选型。
1 | create table worker_id ( |
当一个ID生成器服务实例启动时,将携带本地IP地址查询worker_id表,如果找到对应的数据,则使用该数据行的主键作为其worker ID;否则,服务实例向worker_id表中插入IP地址,并将插入数据后得到的主键作为worker ID。如果某服务实例获得的worker ID数值超过所允许的范围,则启动失败。
分布式协调技术的相关开源项目如ZooKeeper或etcd,也可以实现服务实例ID分配的功能,这里以etcd为例介绍实现方案。
etcd是一个高可用的键值存储系统,通常用于服务发现、分布式锁、Leader选举、消息订阅和发布等场景中。etcd提供了Revision机制:一个etcd集群有一个全局数据版本号Revision,当集群内任何数据发生变更(创建、删除、修改)时,Revision值都会加1。etcd保证Revision全局单调递增,任何一次数据变更都对应唯一的Revision值。etcd中存储的每个键值数据都会维护两个与Revision相关的版本。
- create revision:键值数据被首次创建时,记录此时的Revision值。
- mod_revision:键值数据被修改时,记录此时的Revision值。
使用etcd为服务实例分配worker ID的方案就依赖create revision字段:每个服务实例都向etcd中写入一个代表自己的键值,然后与其他服务实例比较create_revision的大小。如果有M个服务实例的create_revision小于此服务实例的create_revision,则说明在此服务实例启动前已经有M个服务实例相继启动过,于是将此服务实例的worker ID设置为M。服务实例从etcd中获取worker ID的流程如下。
- 当唯一ID生成器服务实例启动时,将携带本地IP地址在etcd集群中创建新的键值
worker_id_{IP}。 - 此服务实例从etcd中获取所有前缀为
worker_id_的键值列表。 - 对所获取到的键值列表按照create_revision从小到大的顺序排列。
- 将此服务实例的键值在排序后的键值列表中的下标位置作为其worker IDO
对应的Go语言代码实现如下:
1 | func GetWorkerID |
4.3.5 时钟回拨问题与解决方案
时间戳的数据通过计算机的时钟获得,而计算机的时钟用专门的硬件来模拟:计算机主板上有一个石英晶体振荡器和一个纽扣电池,其中石英晶体振荡器的频率为32,768Hz。在通电状态下,石英晶体振荡器每振动32,768次,电路就会传出一次信息,表示1s到了,计算机就是通过这种方式来记录时间的。不过,用石英晶体模拟时钟会有误差,在正常情况下,每天的计时误差在±1s内,而在极端条件下(如低温)误差会变大。这种现象被称为“时钟漂移”。
由于时钟漂移的存在,一组工作的计算机之间可能会存在时间戳误差。1985年,David L. Mills设计了网络时间协议(Network Time Protocol, NTP)来同步计算机之间的时钟,它可以将所有计算机之间的时钟误差调整到几毫秒以内,一个局域网内的计算机时钟误差甚至可以在1ms内。NTP有效地解决了时钟漂移的问题。
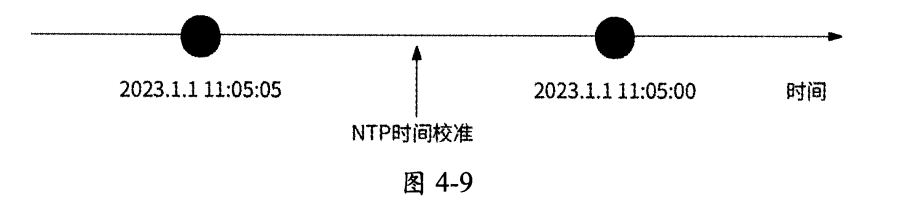
但是NTP时钟同步又带来了另一个问题:时钟回拨。如果某计算机的时钟时间远快于NTP标准时间,那么经过NTP时间校准后,此计算机的时钟时间需要回退到NTP标准时间,即发生了时钟回拨,这个问题会导致基于Snowflake算法的唯一ID生成器服务生成重复的ID。
如图4-9所示,唯一 ID生成器服务的某个实例的时间为2023年1月1日11时05分05秒,经过NTP时间校准后,此服务实例的时间变为2023年1月1日11时05分00秒,此时此服务实例生成的唯一ID与5s前生成的ID产生了重复。
当唯一ID生成器服务的某个实例收到请求时,首先计算出此时的毫秒时间戳millis,然后与上一次请求的毫秒时间戳svr.millisPassed进行比较,如果millis小于svr.millisPasseds,则说明发生了时钟回拨。当发生时钟回拨时,可以采取如下措施防止生成重复的ID。
- 如果回拨的时间较短(如10ms),则阻塞请求一段时间后再重新执行。
- 如果回拨的时间较长,则阻塞请求不可取,此时服务实例可以直接拒绝请求。
另外,还有一种建议的做法是对唯一ID生成器服务的全部实例直接关闭NTP时钟同步功能,防止发生时钟回拨。关闭NTP时钟同步功能,虽然可能会导致一些服务实例发生大幅度的时钟漂移,但是我们可以选择从服务集群中摘除这些服务实例。
4.3.6 最终架构
基于Snowflake算法的唯一ID生成器服务的最终架构如下所述,如图4-10所示。
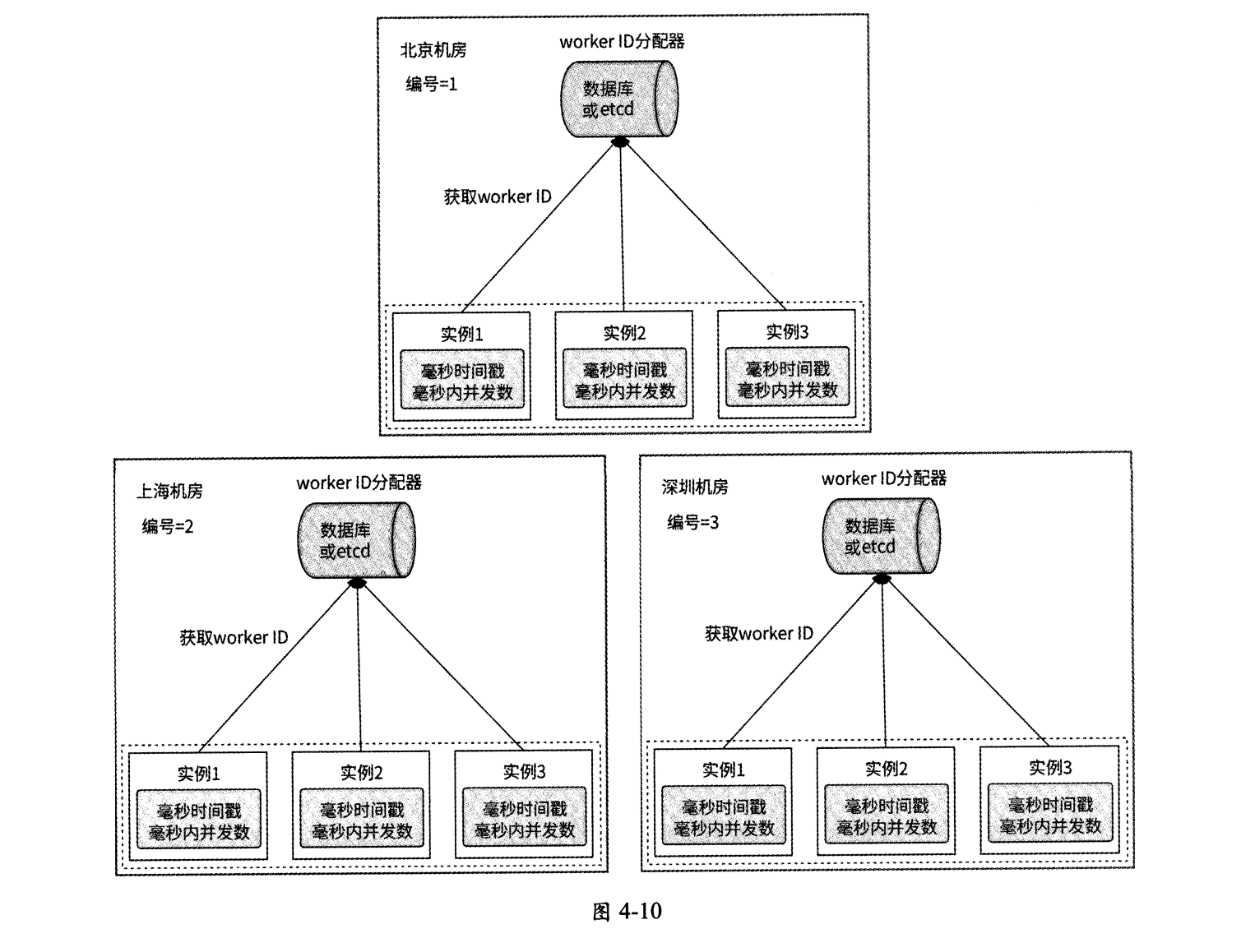
- 每个机房都单独编号。
- 在每个机房内都部署一个worker ID分配器,可以基于数据库或etcd等。
- 在每个机房内都部署若干唯一ID生成器服务实例,这些服务实例每次启动时都从本机房的worker ID分配器中获取worker ID。
- 每个服务实例都在本地维护当前毫秒时间戳和毫秒内并发数,并与机房编号、worker ID一起作为输入参数,执行Snowflake算法生成唯一ID。
总结
请介绍以下雪花算法?
Snowflake算法的原理是将分布式环境下的各变量按数位组合成64位的long类型数字生成唯一ID。唯一ID是由多个数位分段组成的,这些分段从高位到低位依次如下。
- 1位:符号位,固定值为0,用于保证生成的long类型ID是正整数。
- 41位:存储当前时间与指定时间(可以是上线时间)的毫秒差值,从指定时间开始可运行$2^{41}/(1000\times 60\times 60\times 24\times 365)\approx 69$年。
- 5位:用于区分不同的机房,最多支持$2^5=32$个机房。
- 5位:用于区分ID生成器服务的不同实例,支持$2^5=32$个实例。不过,这5位与前5位共享10位存储空间——如果是单机房环境,则无须区分不同的机房,可以用10位来区分ID生成器服务的不同实例,即支持1024个服务实例;如果最多会建设6个机房,则区分不同的机房只需3位,可以用剩下的7位来区分ID生成器服务的不同实例。
- 12位:最后12位用于区分单个ID生成器服务实例在同一毫秒内生成的唯一ID,最多支持$2^{12}=4096$个唯一 ID,即单个服务实例1s可支持约410万个唯一ID生成请求。
最终效果是,Snowflake算法给出的唯一ID生成器是一个支持多机房共1024个服务实例规模、单个服务实例每秒可生成410万个long类型唯一ID的分布式系统,且此系统可以正常工作69年。
什么是时钟漂移?
- 用石英晶体模拟时钟会有误差,在正常情况下,每天的计时误差在±1s内,而在极端条件下(如低温)误差会变大。这种现象被称为“时钟漂移”。
NTP如何有效解决时钟漂移问题的呢?
- 通过设计网络时间协议来同步计算机之间的时钟,它可以将所有计算机之间的时钟误差调整到几毫秒以内,一个局域网内的计算机时钟误差甚至可以在1ms内。NTP有效地解决了时钟漂移的问题。
NTP会带来什么问题?
- NTP会带来时钟回拨问题。
什么是时钟回拨呢?
- 如果某计算机的时钟时间远快于NTP标准时间,那么经过NTP时间校准后,此计算机的时钟时间需要回退到NTP标准时间,即发生了时钟回拨问题。
当发生时钟回拨时,可以采取什么措施防止生成重复的ID呢?
- 如果回拨的时间较短(如10ms),则阻塞请求一段时间后再重新执行。
- 如果回拨的时间较长,则阻塞请求不可取,此时服务实例可以直接拒绝请求。
- 还有一种建议的做法是对唯一ID生成器服务的全部实例直接关闭NTP时钟同步功能,防止发生时钟回拨。关闭NTP时钟同步功能,虽然可能会导致一些服务实例发生大幅度的时钟漂移,但是我们可以选择从服务集群中摘除这些服务实例。




