第4章唯一ID生成器——4.2 单调递增的唯一ID

第4章唯一ID生成器——4.2 单调递增的唯一ID
John Yaml唯一ID生成器本身也是一个服务,为了生成单调递增的唯一ID,这个服务需要使用某种存储系统记录可分配的唯一ID。Redis和其他数据库都可以达到这个目的。
4.2.1 Redis INCRBY 命令
Redis提供的INCRBY命令可以为键(Key)的数字值加上指定的增量(increment)。如果键不存在,则其数字值被初始化为0,然后执行增量操作。使用INCRBY命令限制的值类型为64位有符号整数,此命令的特性与单调递增的唯一ID的诉求非常契合。基于Redis INCRBY命令实现的唯一ID生成器的Go语言代码非常简单:
1 | func GenID() (int64, error) { |
每当生成唯一ID的请求到来时,唯一ID生成器都对同一个键seq_id执行一次加1的增量操作,并将键的值作为唯一ID返回,这样就可以保证ID生成器生成的ID是唯一且单调递增的。
由于Redis具备高性能,且INCRBY命令执行的时间复杂度是O(1),所以基于Redis INCRBY命令实现的唯一ID生成器性能表现很好,不过还有优化的空间。
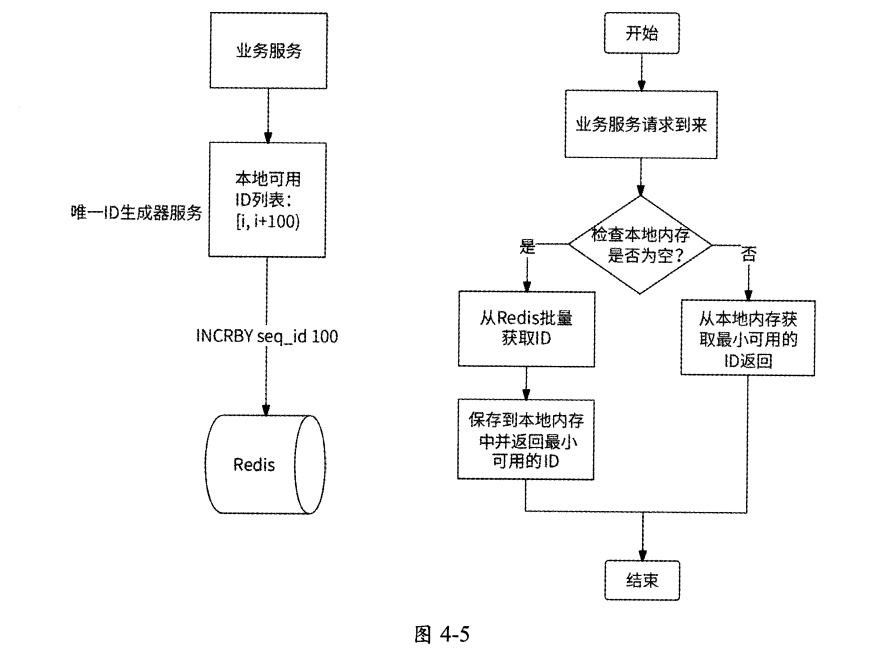
唯一ID生成器服务可以每次从Redis中批量获取ID并存储到本地内存中,当业务服务请求到来时,直接从本地内存返回最小可用的ID。
如果本地内存中没有可用的ID,则再次从Redis中批量获取。
这个优化方案的整体架构和流程如图4-5所示。
唯一 ID生成器的Go语言代码实现如下:
1 | // 唯一工D生成器服务结构 |
唯一ID生成器服务从Redis中批量获取ID的方式,不仅可以进一步提高服务的性能,而且可以降低由于网络抖动而导致Redis访问超时所带来的影响。不过,Redis主要用作缓存,它并不具有严格的数据持久化能力。如果最新的唯一ID数据丢失,则很容易生成重复的ID,给业务服务带来难以估计的风险。我们先来看一个Redis实例宕机的例子。
- T1时刻seq_id键的值为1000, Redis已将数据持久化到RDB文件和AOF文件中。
- T2时刻唯一ID生成器服务从Redis中获取10个ID,得到1001~1010,seq_id键的最新值变为1010。
- T3时刻Redis实例宕机,seq_id键的最新值还未来得及被持久化。
- T4时刻Redis重启,Redis使用RDB文件和AOF文件重建内存数据,seq_id键的值依然是1000。
- T5时刻唯一ID生成器服务从Redis中获取10个ID,再次得到1001~1010。
如果采用Redis主从架构呢?依然无法彻底解决ID重复的问题,因为Redis主从复制是异步的,即Redis主节点无法确定从节点是否已经复制了某数据。假设唯一ID生成器服务从Redis主节点获取了 1001-1010的ID后主节点发生宕机,由于seq_id键的最新值尚未被复制到从节点,从节点上seq_id键的值依然是1000;如果此时从节点被提升为主节点,那么下一次唯一ID生成器服务从其获取的10个ID依然是1001-1010,即生成了重复的ID。
4.2.2 基于数据库的自增主键
生成单调递增的唯一ID的另一种方式是基于数据库的自增主键。首先在数据库中创建数据表seq_id:
1 | create table seq_id ( |
其中,id字段使用auto_increment声明为自增主键。首次向seq_id数据表中插入数据后,该数据主键被设置为1,之后每次插入新数据时,数据主键都会以1的增量自增;col字段只是为了方便插入数据,没有特殊含义。唯一ID生成器服务先在seq_id数据表中插入一条数据,然后读取此数据的主键并将其作为唯一ID返回。使用Go语言代码实现如下:
1 | func GenID() (int64, error) { |
基于数据库的自增主键插入数据生成唯一ID的性能不高,我们同样可以将其改进为采用4.2.1节介绍的批量生成ID的方式。唯一ID生成器服务的代码实现与Redis方案类似,只是批量生成ID的函数不一样:
1 | // 从数据库中批量获取工D |
为了保证高可用性,数据库采用主从架构,同时主从数据复制采用半同步复制或MGR(MySQL组复制)的机制,这样每次将新数据插入数据库主节点时,主节点都会将新数据同步复制到从节点。如果数据库主节点宕机,那么从节点可以立刻代替主节点对外提供服务,唯一 ID生成器服务不会因为访问从节点而生成重复的ID。
4.2.3 高可用架构
需要注意的是,如果批量生成唯一ID的生成器服务有多个实例对外提供服务,则无法生成单调递增的唯一ID。如图4-6所示,假设唯一ID生成器服务初次启动并有两个实例接收业务请求。
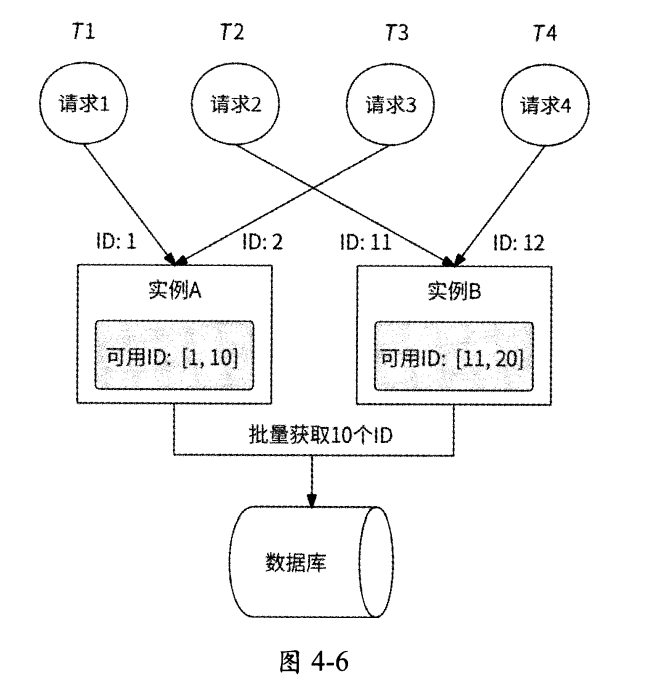
- T1时刻实例A收到请求1,于是从数据库中批量获取10个唯一 ID,即1-10,将其缓存到本地,然后为请求1返回ID=1。
- T2时刻实例B收到请求2,也从数据库中批量获取10个唯一ID,即11-20,将其缓存到本地,然后为请求2返回ID=11。
- T3时刻实例A收到请求3,于是返回本地可用的ID=2。
- T4时刻实例B收到请求4,于是返回本地可用的ID=12。
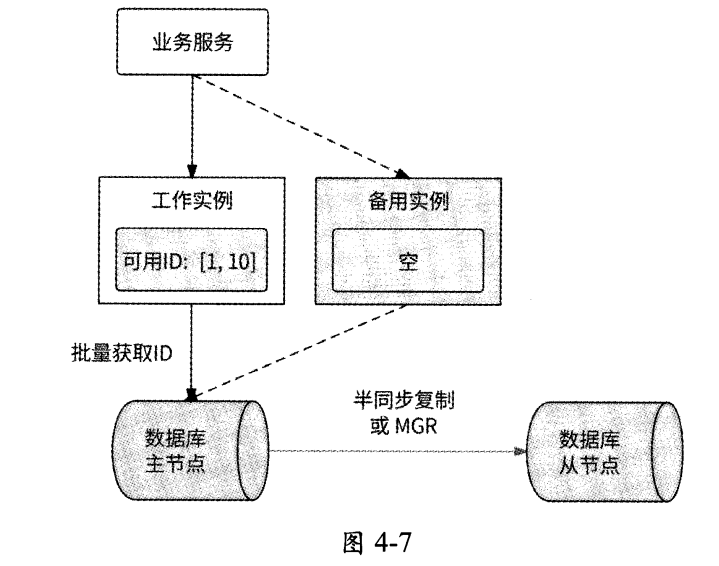
唯一ID生成器服务依次生成的ID是不满足单调递增的1、11、2、12,而是趋势递增的,所以此服务在任何时刻只能有一个实例对外提供服务。而服务只有一个实例,则意味着这个服务的可用性较差。为了提高唯一ID生成器服务的可用性,可以增加一个备用实例:此实例日常不对外提供服务,仅当工作实例宕机后,它才接替工作实例处理业务请求。最终的唯一ID生成器服务的架构如图4-7所示。
无论是否采用批量获取ID的思路,单调递增的唯一ID生成器都始终无法支持高并发访问,这是单调递增的唯一ID不被广泛使用的最主要原因。
- 如果不批量获取ID,则意味着每个业务请求都会写数据库,数据库难以承受高并发写入操作,性能表现不佳,甚至可能会被击垮;
- 如果批量获取ID,虽然数据库访问量级降低了,但是ID生成器服务只能有一个工作实例,单实例所能承载的并发量级非常有限,服务失去了可扩展性。
相比之下,唯一ID生成器能被广泛接受的实现方式是生成趋势递增的唯一ID。
总结
生成单调递增的唯一ID有哪些方法?
- Redis INCRBY命令
- 基于数据库的自增主键
为什么单调递增的唯一ID生成器不被广泛使用呢?
- 核心原因:单调递增的唯一ID生成器无法支持高并发访问。
- 如果不批量获取ID,则意味着每个业务请求都会写数据库,数据库难以承受高并发写入操作,性能表现不佳,甚至可能会被击垮;
- 如果批量获取ID,虽然数据库访问量级降低了,但是ID生成器服务只能有一个工作实例,单实例所能承载的并发量级非常有限,服务失去了可扩展性。




