第9章排行榜服务——9.5 精确排名与粗估排名结合

第9章排行榜服务——9.5 精确排名与粗估排名结合
John Yaml9.5 精确排名与粗估排名结合
对于全民参与的超长排行榜,在设计功能时,产品经理基本上可以同意只展示前N名用户的详细排名,而其他用户只得知自己的名次即可的诉求。比如排行榜可以展示前10000名用户的列表,对于10000名以后的用户,并不展示其排名的前面、后面都有哪些人,只告诉其名次是多少即可。所以,实现超长排行榜的终极解决方案是ZSET精确排名与线段树粗估排名的结合:
- 前者负责维护前10000名用户的详细排名和排行榜列表;
- 后者负责展示每个用户,尤其是10000名以后的用户的粗估排名。
不过,由于线段树无法存储用户积分,所以需要使用额外的系统来做这件事情,比如第8章介绍的计数服务。
计数服务的作用是存储排行榜上的用户积分。每当更新排行榜时,直接更新计数服务,然后计数服务将积分变更事件发送到消息中间件就可以响应用户了。排行榜服务消费积分变更事件,而后持续构建ZSET和线段树,为用户提供查询排行榜列表和排名的能力。
从用户积分更新到排行榜名次变动生效的完整流程如图9-8所示。
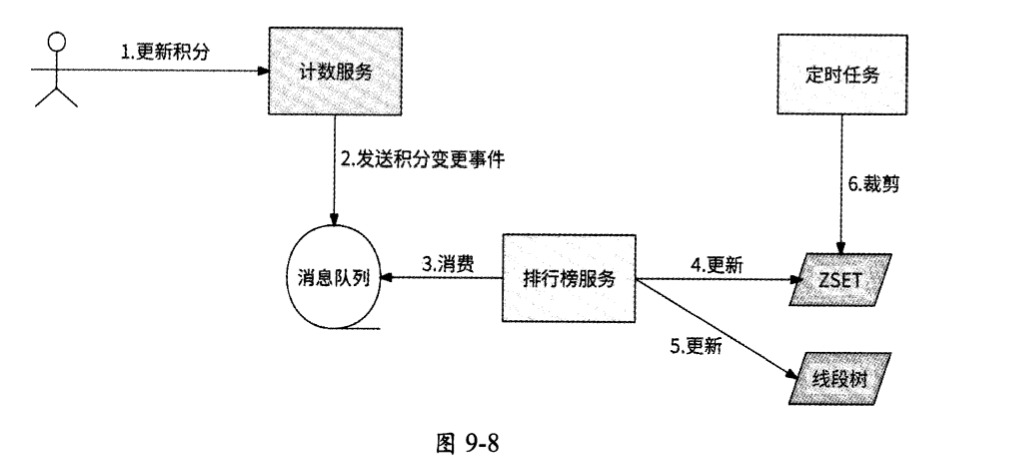
- 用户发起积分更新的请求,请求中包含用户ID、排行榜名称和待增加的积分。
- 计数服务接收请求,请求处理逻辑本质上是对Key为
排行榜名称—用户ID的String对象的Value加上增加值,处理成功后响应用户。然后,计数服务将此次增加积分作为积分变更事件发送到消息队列,对应的主题为change_counter_trigger,消息事件的结构如下:
1 | type ChangeCounterTriggerEvent struct { |
- 排行榜服务消费change_counter_trigger的消息;如果发现消息的KeyPrefix字段为排行榜名称,则处理这个消息,否则丢弃消息。
- 排行榜服务在处理消息时,使用KeyPrefix、Userid、Score字段请求Redis执行ZADD命令修改ZSET。
- 排行榜服务计算出积分更新前的值PScore=Score-DeltaScore,然后使用PScore和Score更新线段树。
- 为了防止ZSET的长度无限增长,定时任务周期性地将ZSET中前10000名之外的用户数据删除。
对于查询排行榜列表的请求,排行榜服务只需要读取ZSET即可。而对于查询用户排名的请求,排行榜服务可能需要从计数服务中查询积分,其处理流程如下所述,如图9-9所示。
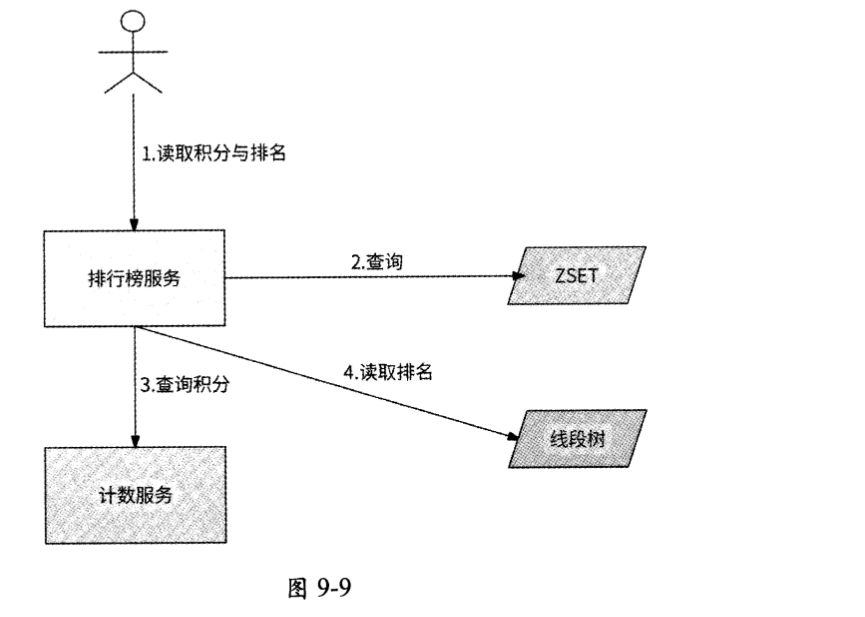
- 用户发起读取排行榜排名的请求,请求中包含排行榜名称和用户ID。
- 排行榜服务先查询ZSET,如果用户ID存在,则直接返回用户排名与积分。
- 如果在ZSET中查询不到用户ID,则说明此用户的名次可能比较靠后,于是从计数服务中获取用户积分。
- 如果计数服务返回了非零的积分,则说明用户有名次,再用积分查询线段树,得到用户粗估排名,而后排行榜服务将积分和排名返回给用户。
精确排名与粗估排名结合的方案具有如下优势。
- 可以保证排行榜头部用户积分的准确性,因为高频访问排行榜的用户大概率是头部用户。
- 只需要极少的存储成本,就满足了尾部用户查询排名的需求。
- 支持高并发读/写排行榜,满足高性能的要求。
不过,需要注意的是,由于此方案中用户积分既被存储在计数服务中,又被存储在排行榜服务的ZSET中,所以两者的积分数据保持一致非常重要,尤其是不能出现同一用户从计数服务中查询到的积分低于从ZSET排行榜中查询到的积分的情况(这种情况不符合产品预期)。如果出现这种情况,则对应的解决方法是在排行榜服务的基础上再启动一个定时任务,定期查询ZSET中每个用户的积分并与计数服务进行核对,如果出现不一致的情况,则将ZSET中的积分修改为与计数服务中的积分相同,即向计数服务看齐。
本章小节
本章详细介绍了通用排行榜服务的设计方案。
Redis的ZSET底层是基于跳跃表实现的,不仅支持对数据的自动排序,而且支持高效的数据查询与数据更新操作,因此,使用ZSET实现排行榜是一种非常好的选择。
虽然使用ZSET实现排行榜可能会产生大Key,但这并不一定会带来负面影响。因为ZSET的典型使用场景就是存储大量有序数据,此时它的读/写性能表现其实很好。
使用线段树是另一种实现排行榜的方案,线段树不存储每个用户的积分数据,只存储每个积分段的用户数量,并支持使用积分高效查询粗估排名。线段树是内存型数据结构。为了提高排行榜的可扩展性,排行榜服务实例只需要保存固定的线段树结构,而线段树每个节点的用户数量可以使用Redis的Hash结构保存,且线段树使用的存储空间极小,在海量用户排名时达到了“四两拨千斤”的效果。
ZSET可以实现精确排名,支持获取排行榜列表,但是对于超长排行榜其存储空间占用较大。线段树虽然无视排行榜的长度,但是无法提供精确排名。而ZSET和线段树结合的方案可以发挥两者各自的优势:排行榜的重点用户一般名次都很靠前,所以使用ZSET提供前N名用户的精确排名和排行榜列表,而对名次靠后的用户采用线段树提供粗估排名。
除本章介绍的方案外,业界或许还有基于其他存储系统和数据结构的解决方案。因为不同公司的排行榜服务面对的用户量级、高并发和性能的问题,以及排行榜功能的复杂度是有差别的,所以我们需要根据实际场景来选择最合适的实现方式。
总结
实现超长排行榜的终极解决方案?
ZSET精确排名与线段树粗估排名的结合:
- 前者负责维护前10000名用户的详细排名和排行榜列表;
- 后者负责展示每个用户,尤其是10000名以后的用户的粗估排名。
从用户积分更新到排行榜名次变动生效的完整流程?
- 用户发起积分更新的请求,请求中包含用户ID、排行榜名称和待增加的积分。
- 计数服务接收请求,请求处理逻辑本质上是对Key为
排行榜名称—用户ID的String对象的Value加上增加值,处理成功后响应用户。然后,计数服务将此次增加积分作为积分变更事件发送到消息队列,对应的主题为change_counter_trigger。 - 排行榜服务消费change_counter_trigger的消息;如果发现消息的KeyPrefix字段为排行榜名称,则处理这个消息,否则丢弃消息。
- 排行榜服务在处理消息时,使用KeyPrefix、Userid、Score字段请求Redis执行ZADD命令修改ZSET。
- 排行榜服务计算出积分更新前的值PScore=Score-DeltaScore,然后使用PScore和Score更新线段树。
- 为了防止ZSET的长度无限增长,定时任务周期性地将ZSET中前10000名之外的用户数据删除。
对于查询排行榜列表的请求,排行榜服务只需要读取ZSET即可。而对于查询用户排名的请求,排行榜服务可能需要从计数服务中查询积分,其处理流程如下?
- 用户发起读取排行榜排名的请求,请求中包含排行榜名称和用户ID。
- 排行榜服务先查询ZSET,如果用户ID存在,则直接返回用户排名与积分。
- 如果在ZSET中查询不到用户ID,则说明此用户的名次可能比较靠后,于是从计数服务中获取用户积分。
- 如果计数服务返回了非零的积分,则说明用户有名次,再用积分查询线段树,得到用户粗估排名,而后排行榜服务将积分和排名返回给用户。
精确排名与粗估排名结合的方案具有如下优势?
- 可以保证排行榜头部用户积分的准确性,因为高频访问排行榜的用户大概率是头部用户。
- 只需要极少的存储成本,就满足了尾部用户查询排名的需求。
- 支持高并发读/写排行榜,满足高性能的要求。




