第4章唯一ID生成器——4.1 分布式唯一ID

第4章唯一ID生成器——4.1 分布式唯一ID
John Yaml在复杂的系统中,每个业务实体都需要使用ID做唯一标识,以方便进行数据操作。例如,每个用户都有唯一的用户ID,每条内容都有唯一的内容ID,甚至每条内容下的每条评论都有唯一的评论ID。
4.1.1 全局唯一与UUID
在互联网还未普及的年代,由于用户量少、网络交互形式单调,互联网产品后台数据库使用单体架构就可以满足日常服务的需求。当时每个业务实体都对应数据库中的一个数据表,每条数据都简单地使用数据库的自增主键作为唯一ID。
近年来,随着互联网用户的爆发式增长,数据库从单体架构演进到分库分表的分布式架构,同一个业务实体的数据被分散到多个数据库中。由于数据表之间相互独立,在插入数据时会生成相同的自增主键。此时,如果还使用自增主键作为唯一ID,就会导致大量数据的标识相同,造成严重事故。我们应该保证无论一个业务实体的数据被分散到多少个数据库中,每条数据的唯一ID都是全局的,这个全局唯一ID就是分布式唯一ID。
RFC 4122 规范中定义了通用唯一识别码(Universally Unique Identifier, UUID),它是计算机体系中用于识别信息的一个128位标识符。UUID按照标准方法生成时,在实际应用中具有唯一性,UUID重复的概率可以忽略不计。JDK 1.5在语言层面实现了 UUID,可以轻松生成全球唯一ID:
1 | import java.util.UUID; |
UUID的标准格式由32个十六进制数字组成,并通过连字符-分隔成8-4-4-4-12共 36 个字符的形式。例如,6a0d3e6f-allc-4b7d-bb35-c4c530a456b0、123e4567-e89b-12d3- a456-426655440000。这种唯一ID的生成方式足够简单,利用本地计算即可生成全球唯一ID。不过,UUID具有一些缺点:
- UUID字符串需要占用36字节的存储空间,如果每条数据都携带UUID,那么在海量数据场景下存储空间消耗较大。
- 此外,UUID是无数据规律的长字符串,如果将其用作数据库主键,则会导致数据在磁盘中的位置频繁变动,严重影响数据库的写操作性能。
4.1.2 唯一ID生成器的特点
UUID仅适合数据量不大的场景,比如一个存储集群使用UUID标识每个数据分区。真正可用于海量数据场景的唯一ID生成器,除保证ID不可重复外,还应该具有如下特点。
- 空间占用小:作为每条数据都携带的字段,唯一ID不应该占用过多的存储空间。
- 高并发与高可用性:唯一ID生成器是大部分业务服务的重要依赖方,唯一ID的生成操作需要做到高并发无压力,维持长期高可用性。
- 唯一ID可用作数据库主键:为了不对数据库的写操作造成负面影响,需要保证唯一ID对数据库主键友好。
前两点很好理解,最后一点,什么样的唯一ID才对数据库主键友好呢?我们以MySQL数据库的InnoDB引擎为例。InnoDB使用基于磁盘的B+树表示数据表,并以主键作为索引,即B+树按照主键从小到大的顺序排列数据。
如图4-1所示,B+树的节点使用默认为16KB大小的数据页(Page)表示,其中:
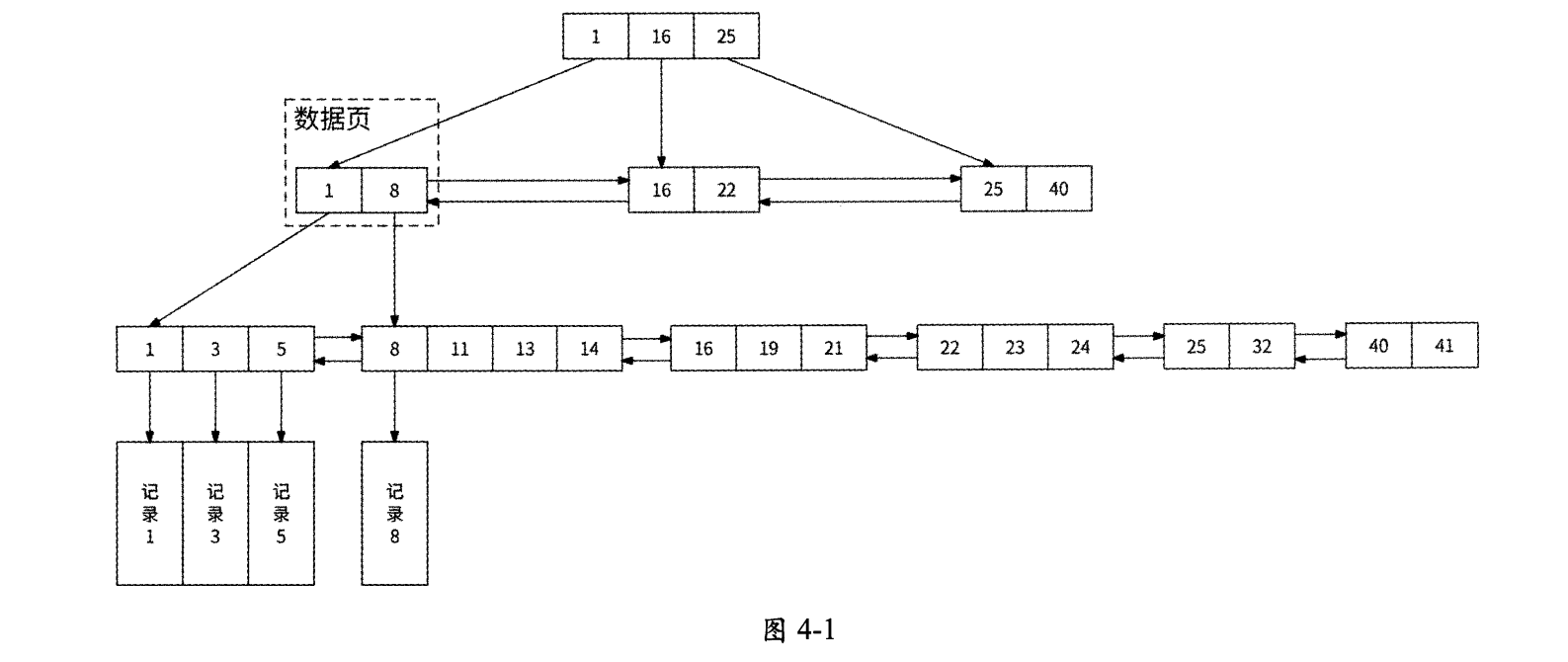
- 节点分为叶节点和非叶节点,底层是叶节点。
- 同层数据页之间相互组成双向链表。
- 非叶节点仅保存N个主键作为指向下一层N个数据页的索引,主键从小到大排列。
- 叶节点保存实际的数据,叶节点组成的双向链表上的所有数据按照主键从小到大的顺序排列。
使用自增性质的字段作为InnoDB数据表的主键是一个很好的选择,每次写入新数据时,数据都被顺序添加到对应数据页的尾部;一个数据页写满后,B+树自动开辟一个新的数据页。
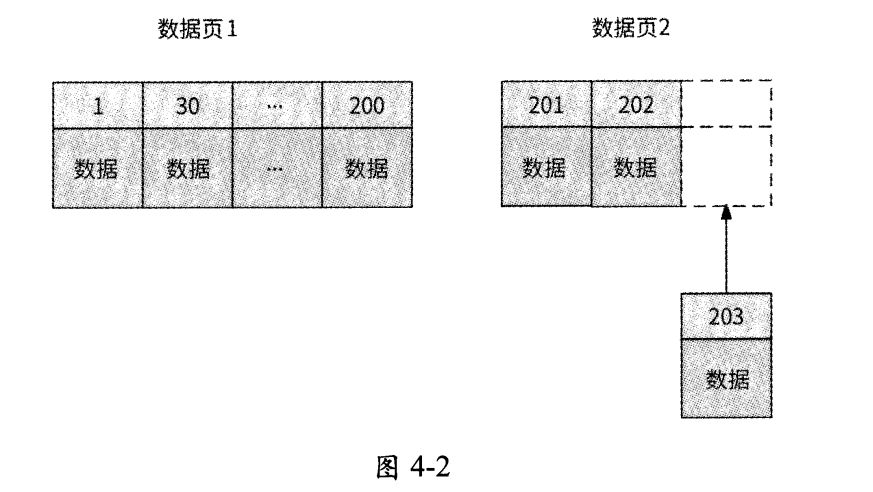
如图4.2所示,主键值为203的新数据被插入数据页2的尾部,这样一来,B+树将会形成一个较为紧凑的索引结构,空间利用率较高;而且,每次插入数据时也不需要移动已有的数据,时间开销很小。
而如果使用非自增性质的字段(比如身份证号码、电话号码)作为主键,由于主键值较为随机,新数据可能要被插入数据页中间的某个位置。如图4-3所示,主键值为15的新数据只能被插入数据1和数据30之间,数据30、50、90都需要向后移动。
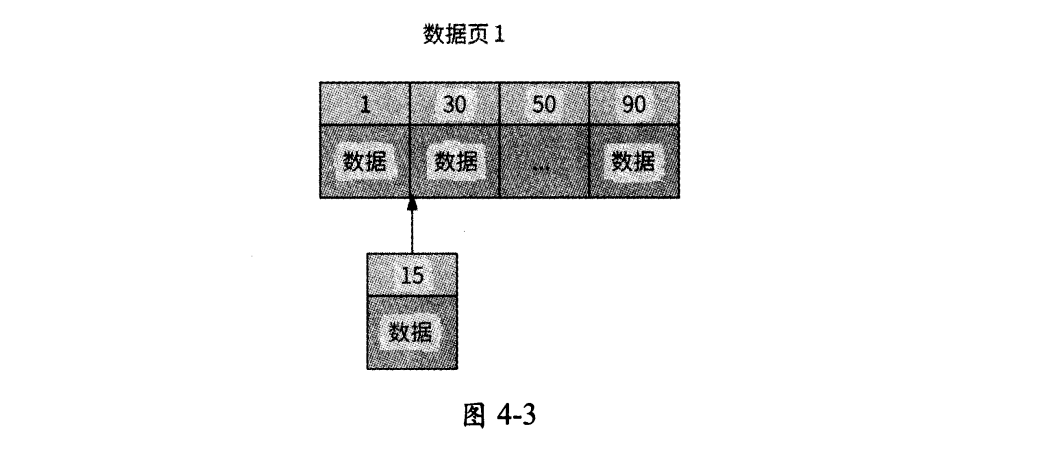
为了给新数据腾出位置,B+树不得不将已有的数据向后移动——如果数据页已满,则会进行多次分页操作。频繁的数据移动和分页操作使得B+树在磁盘上产生大量的碎片,且时间开销很大。因此,官方建议尽量使用自增性质的字段作为InnoDB数据表的主键。
为了成为自增性质的主键,唯一ID生成器生成的唯一ID在数值上应该是递增的,这样的唯一ID对数据库主键就是友好的。
占用8字节(64位)的long类型整数适合用作唯一ID,因为:
- long类型虽然占 用的空间较小,但是可表示的ID范围却非常大
- long类型整数很容易实现递增的效果。
至此,本章的议题已经明确:设计一个可以生成递增的long类型唯一ID的生成器。
4.1.3 单调递增与趋势递增
在正式开始设计唯一ID生成器之前,我们还需要解释一下递增。递增可以分为单调递增和趋势递增,从技术实现的角度来看,它们的差异较大。
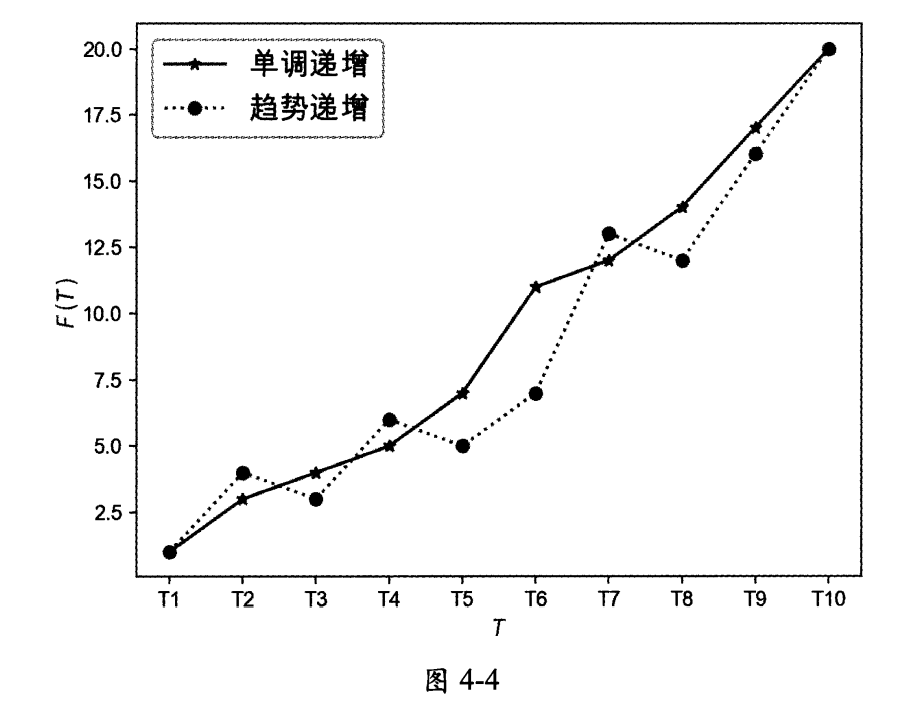
- 单调递增:T表示绝对时间点,如果$T_{n+1} > T_n$,则一定有$F(T_{n+1}) > F(T_n)$。如果唯一ID生成器生成的ID单调递增,则说明下一次获取到的ID一定大于上一次获取到的ID。
- 趋势递增:T表示绝对时间点,如果$T_{n+1} > T_n$,则大概率有$F(T_{n+1}) > F(T_n)$。虽然在一小段时间内数据有乱序的情况,但是从整体趋势上看,数据是递增的。
单调递增和趋势递增的数据特点如图4-4所示。
虽然我们在4.1.2节中已经讨论了唯一ID应该是递增的,但无奈受限于全局时钟、延迟等分布式系统问题,单调递增的唯一ID生成器的设计方案往往会有较大的局限性,与此相比,趋势递增的唯一 ID生成器更受业界欢迎。接下来具体介绍这两种递增类型的唯一ID生成器设计方案的差别。
总结
在分布式架构中,如果还使用自增主键作为唯一ID,会发生什么问题呢?
数据库从单体架构演进到分库分表的分布式架构,同一个业务实体的数据被分散到多个数据库中。由于数据表之间相互独立,在插入数据时会生成相同的自增主键。此时,如果还使用自增主键作为唯一ID,就会导致大量数据的标识相同,造成严重事故。
什么是UUID呢?
UUID的标准格式由32个十六进制数字组成,并通过连字符-分隔成8-4-4-4-12共 36 个字符的形式。例如,6a0d3e6f-allc-4b7d-bb35-c4c530a456b0、123e4567-e89b-12d3- a456-426655440000。
UUID的缺点?
UUID字符串需要占用36字节的存储空间,如果每条数据都携带UUID,那么在海量数据场景下存储空间消耗较大。
UUID是无数据规律的长字符串,如果将其用作数据库主键,则会导致数据在磁盘中的位置频繁变动,严重影响数据库的写操作性能。
唯一ID生成器的特点?
- 空间占用小:作为每条数据都携带的字段,唯一ID不应该占用过多的存储空间。
- 高并发与高可用性:唯一ID生成器是大部分业务服务的重要依赖方,唯一ID的生成操作需要做到高并发无压力,维持长期高可用性。
- 唯一ID可用作数据库主键:为了不对数据库的写操作造成负面影响,需要保证唯一ID对数据库主键友好。
为什么使用自增性质的字段作为InnoDB数据表的主键是一个很好的选择?
- 使用自增性质的字段,每次写入新数据时,数据都被顺序添加到对应数据页的尾部;一个数据页写满后,B+树自动开辟一个新的数据页。
- 使用非自增性质的字段(比如身份证号码、电话号码)作为主键,由于主键值较为随机,新数据可能要被插入数据页中间的某个位置。为了给新数据腾出位置,B+树不得不将已有的数据向后移动——如果数据页已满,则会进行多次分页操作。频繁的数据移动和分页操作使得B+树在磁盘上产生大量的碎片,且时间开销很大。
为什么占用8字节(64位)的long类型整数适合用作唯一ID呢?
- long类型虽然占用的空间较小,但是可表示的ID范围却非常大
- long类型整数很容易实现递增的效果。
什么是单调递增和趋势递增?
- 单调递增:T表示绝对时间点,如果$T_{n+1} > T_n$,则一定有$F(T_{n+1}) > F(T_n)$。如果唯一ID生成器生成的ID单调递增,则说明下一次获取到的ID一定大于上一次获取到的ID。
- 趋势递增:T表示绝对时间点,如果$T_{n+1} > T_n$,则大概率有$F(T_{n+1}) > F(T_n)$。虽然在一小段时间内数据有乱序的情况,但是从整体趋势上看,数据是递增的。




